


서론
딥 러닝을 배운 후, 딥 러닝을 어떻게 하면 더 빠른 속도로 할 수 있는지 알아보는 시간입니다 ! 이전 강의를 듣고 오시지 않으셨으면 지금 보시지 않는 것을 추천드려요 !! 딥 러닝에는 모델 개선 말고도 테스트 검증이나 데이터 넣는 개수 등 여러가지 속도와 정확성에 관련 된 요소들이 많습니다 ! 그 중 가장 유명한 3가지 테크닉에 대해서 설명드리려고 합니다.
목차
Hyperparameter Tuning
1.
Learning Rate
•
Learning Rate?
◦
Learning Rate는 Gradient Descent 속도를 조절하는 값
•
Learning Rate 값에 따른 정확도 변화
◦
작을 때 : 손실함수의 최소값을 구하는데 오래 걸림. 정확도는 제일 높게 나옴.
◦
클 때 : 빠르게 손실함수의 최소값을 구하는 방향으로 갈 수 있음. 하지만 정확성이 떨어짐.
◦
너무 클 때 : 손실함수의 최소값이 위치한 x값을 넘어서 발산해버릴 수 있음. (사진 첨부)
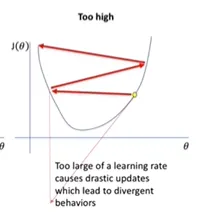
•
Learning Rate Scheduling
◦
Learning Rate를 적절히 사용하는 방식은 초반에는 크게, 후반에는 작게 하여 빠르면서도 정확하게 하는 것이다.
◦
방식
▪
연속적 : 연속인 그래프(ex - y=e^x)를 사용하여 epochs(반복횟수)가 커지면 Learning Rate를 늦추는 방식
▪
계단식(Stepping Down) : epochs가 특정한 값에 도달할때까지 Learning Rate를 일정한 값을 가지게 하는 방식. 초반에 큰 값을 변화시킬 수 있음.
◦
사용법
▪
keras에서 제공
•
callback=tf.keras.callbacks.LearningRateScheduler(schedule)
2.
Batch Size
•
Batch Size?
◦
Batch Size는 한번에 학습시킬 데이터의 양을 뜻하는 값
◦
Batch Size값에 따라 손실함수가 rough하게 변할지 섬세하게 변할지 결정됨.
•
Batch Size에 따른 정확도 변화
◦
작을 때 : 값 하나 넣고 손실함수 변화가 있기에 손실함수가 이상하게 변화할 수 있음. (Just Fit이므로)
◦
클 때 : 학습 양이 많기 때문에 손실함수가 Rough하게 변하므로 정확성이 떨어짐.
3.
How to get Optimal Hyperparameter
•
방식
◦
Grid Search
▪
Learning Rate, Batch Size 테이블을 만들어서 어떨때 가장 정확한 값을 갖는지 찾는 것
▪
Grid Search는 정해준 값만을 테스트 하기에 변화가 큰 구간을 파악하지 못할 경우가 있다.
◦
Random Search
▪
Random Learning Rate, Batch Size를 넣은 후 가장 최적의 점에서부터 또 범위를 넓혀 Random 값을 넣는식으로 동작
•
AutoML
◦
위 것들을 하나하나 할 수 없어서 자동화해주는 기법
◦
위 두개 파라미터(Learning Rate, Batch Size)외에도 정확성에 영향을 미치는 파라미터들이 많음.
▪
optimizer, layer count
◦
Katib, AutoKeras 등이 있다.
Prevent Overfitting
1.
Overfitting
•
Overfitting?
◦
Overfitting : 과적합. training-set에 너무 적합해져버린 나머지 test-set에서는 정확도가 떨어지게 되는 현상. 다른 말로 High variance(오차 들쑥날쑥), Low bias라고도 한다.
◦
Underfitting : 저적합. High bias(대체적으로 틀림), Low variance.
◦
Bias와 Variance는 Trade-off 관계.
2.
방법
•
Collect more data
◦
데이터를 많이 모으면 해결가능. (데이터가 많으면 overfitting 되기가 어렵기 때문(하나하나에 맞추려고 하기에는 너무 많아서))
•
Early stopping
◦
validation accuracy가 크게 변하지 않으면 멈춘다.
•
Regularization(정규화)
◦
Cost=Loss Function+Regularization Term 을 두는 것.
◦
feature size를 크게 하더라도 불필요하다고 판단되는 것들의 Weight를 0으로 만듦.
◦
방법 : tf.keras.layers.Dense(3, kernel_regularizer='l1')
•
Dropouts
◦
Dropouts?
▪
Training을 시킬 때 Random으로 Layer를 끊어서 학습한다. 마지막 Test 할 때는 다 연결시켜서 Test. Simple한 모델들의 앙상블.
◦
효과 : 간단한 모델이 여러가지로 학습이 되므로 votting의 효과. 특정 점으로 과적합을 방지한다. 효과가 굉장히 좋다!
◦
방법 : h = layers.Dropout(0.3)(h) - 0.3 : 30%를 빼겠다는 의미.
Weight Initialization
1.
Weight
•
Weight?
◦
weights = trainable parameters. Wx+b에서 W,b를 뜻함.
2.
Initialization Methods
•
Glorot Uniform (Xavier Uniform) - keras default
◦
limit 사이에서 uniform random으로 뽑음.
◦
limit = sqrt(6/in+out)
◦
효과 : 0에 가까운 값으로 초기화하면 optimal loss의 최대한 가까이에 있어 학습속도에 영향을 미침.
•
He Initialization
◦
방법이 없을까 할 때 다른 방식의 initialization 방식을 쓰는 것도 좋다.
◦
relu를 activation func로 많이 쓸 때 효과적.
◦
정규분표를 사용.
