


“운영체제 : 아주 쉬운 세가지 이야기”를 읽으면서 핵심 내용을 정리하였습니다.
이화여대 반효경 교수님의 운영체제 강의를 듣고 복습 차원에서 책 한권을 완독해보고자 합니다.
잘못된 정보가 있다면 댓글 남겨주시면 감사하겠습니다!
멀티 레벨 피드백 큐(Multi-level Feedback Queue, MLFQ)
이전까지 스케줄러를 설계를 위해 먼저 핵심 가정들을 세우고 어떤 지표로 스케줄러를 평가할지 선정한 후 가정들을 하나씩 완화해 나가면서 스케줄러를 발전시켜 보았다.
아직 "각 작업의 실행 시간은 사전에 알려져있다" 는 가정을 완화 하지 못했고 이를 해결하는 멀티 레벨 피드백 큐라는 스케줄링 알고리즘에 대해 알아보고자 한다. 멀티레벨 피드백 큐 알고리즘의 목적은 아래와 같다.
•
반환시간의 최적화
•
응답시간의 최적화
프로세스(작업)에 대한 정보 없이 어떻게 목표를 이루는지 알아보자.
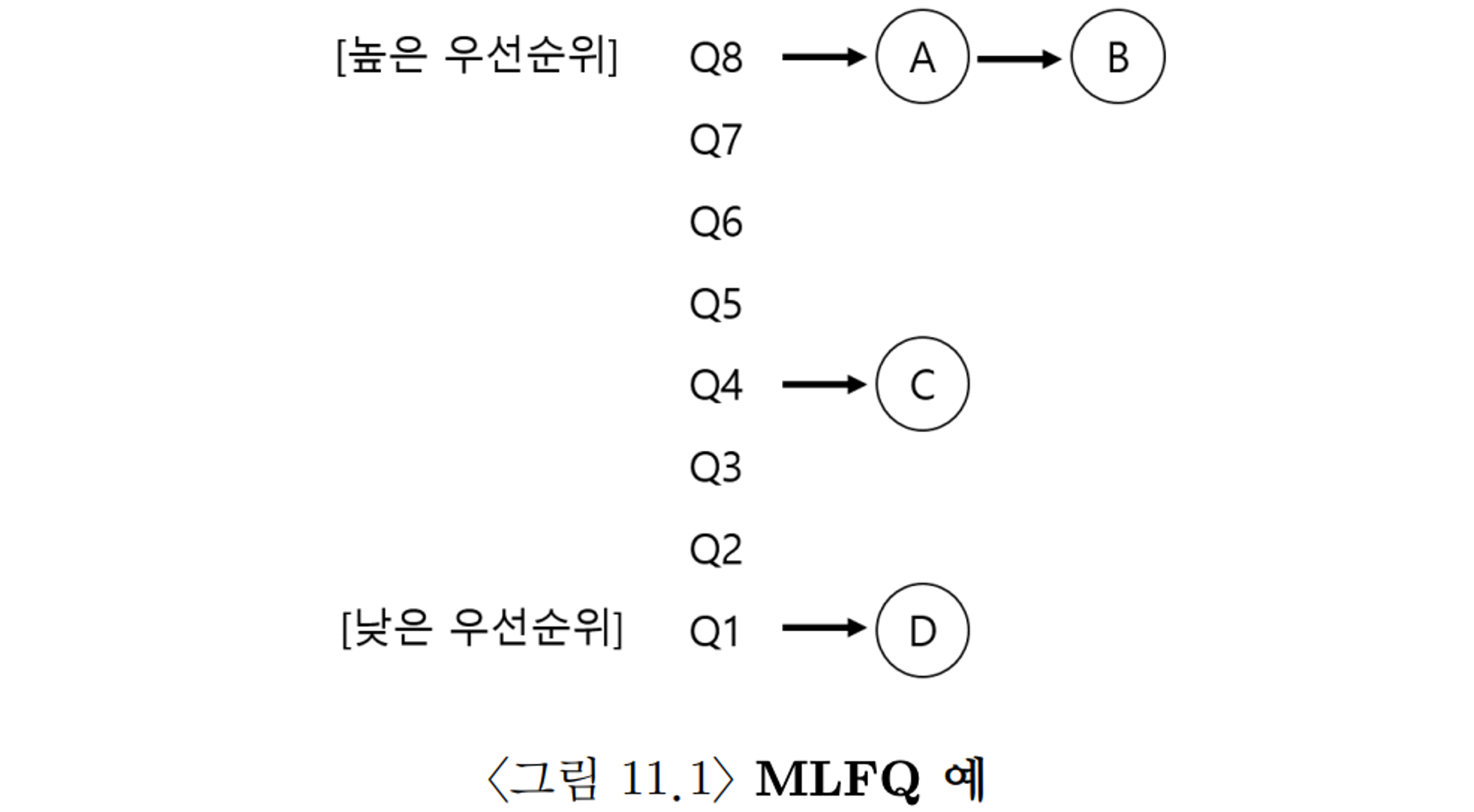
MLFQ : 기본 규칙
•
구성
◦
서로 다른 우선순위를 가진 여러개의 큐로 구성됨
◦
실행 준비 상태의 프로세스는 여러 큐중 하나에 속함
•
규칙
◦
규칙 1 : priority(A) > priority(B) 이면, A 가 실행 된다.
◦
규칙 2: priority(A) == priority(B) 이면, A와 B는 RR 방식으로 실행된다.
•
우선순위 선정 방법
◦
각 작업에 고정된 우선순위를 부여하는 것이 아니라 동적으로 우선 순위를 부여함
▪
우선 순위를 조정해 주지 않는 다면 낮은 우선순위를 갖는 작업은 실행되지 않을 수도 있음
◦
어떤 작업이 키보드 입력을 기다리며 계속적으로 CPU를 양보하면 우선순위를 높힘
◦
어떤 작업이 긴 시간동안 CPU를 집중적으로 사용하면 우선순위를 낮춤
◦
즉, 작업이 진행되는 동안 작업의 정보를 얻어서 해당 정보를 이용하여 미래 행동예측에 반영함
시도 1 : 우선 순위의 변경 규칙
•
규칙
◦
규칙 3 : 작업이 시스템에 진입하면, 가장 높은 우선순위를 부여한다.
◦
규칙 4a : 주어진 타임 슬라이스르 모두 사용하면 우선순위는 낮아진다.
◦
규칙 4b : 타임 슬라이스를 소진하기 전에 CPU를 양도하면 같은 우선순위를 유지한다.
•
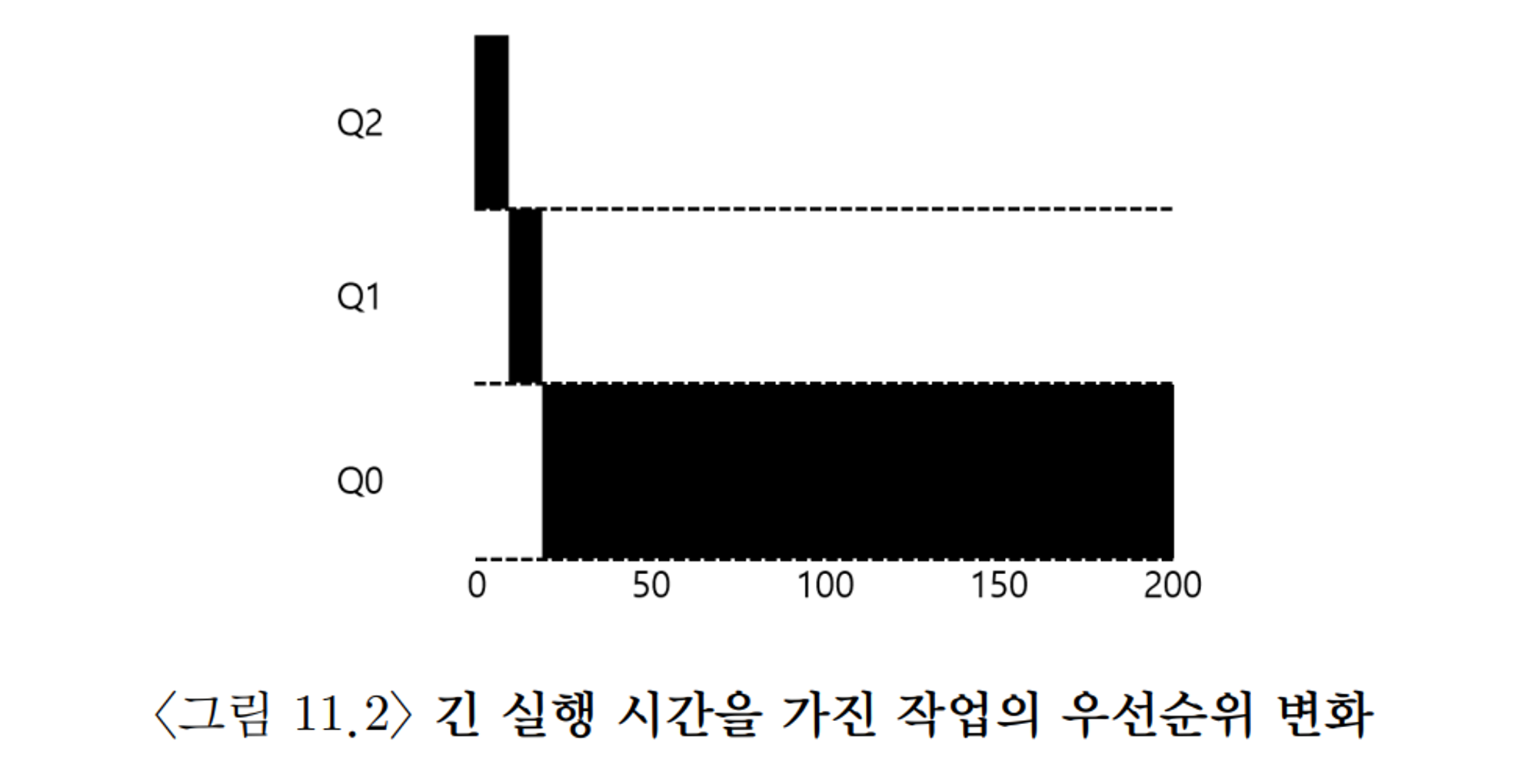
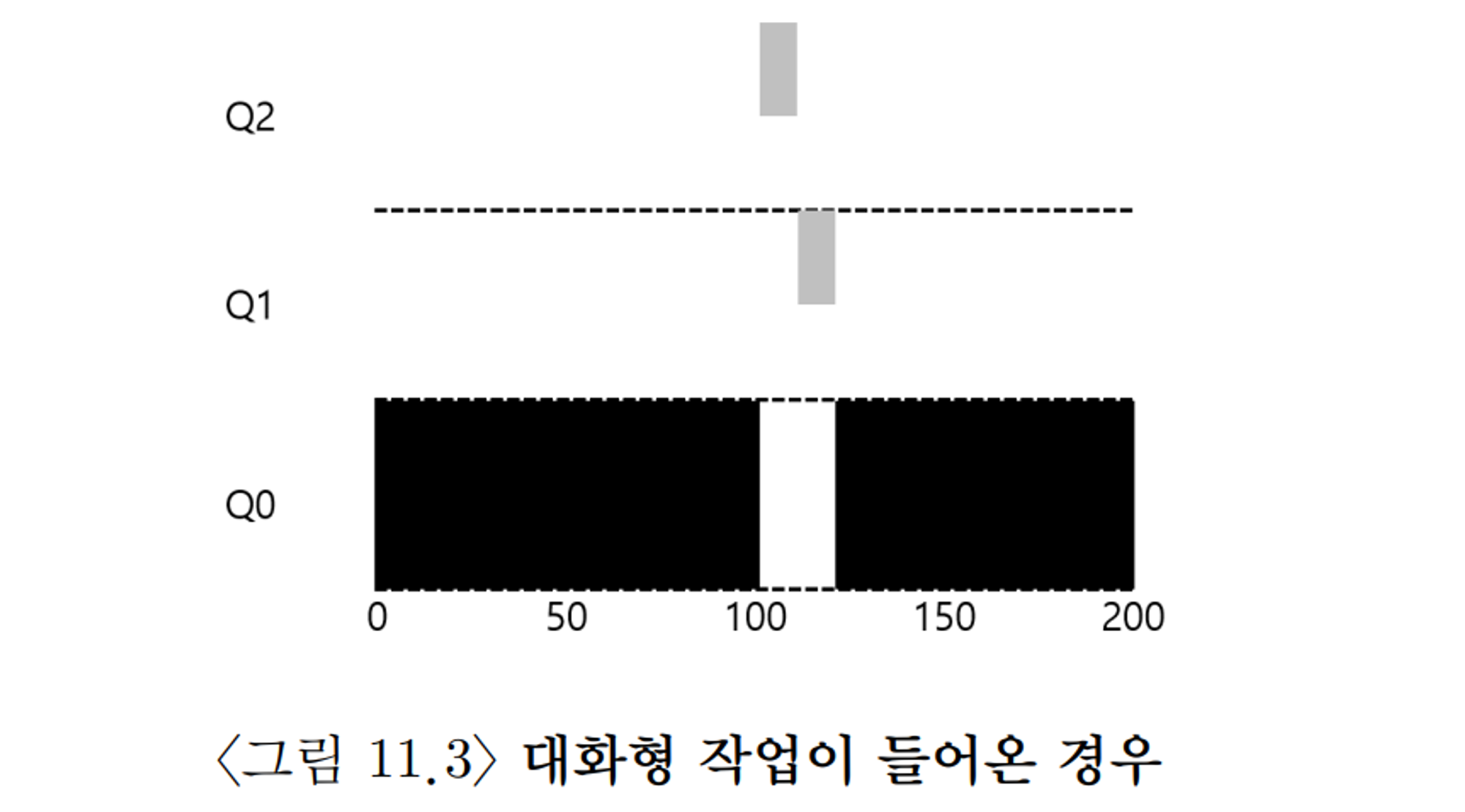
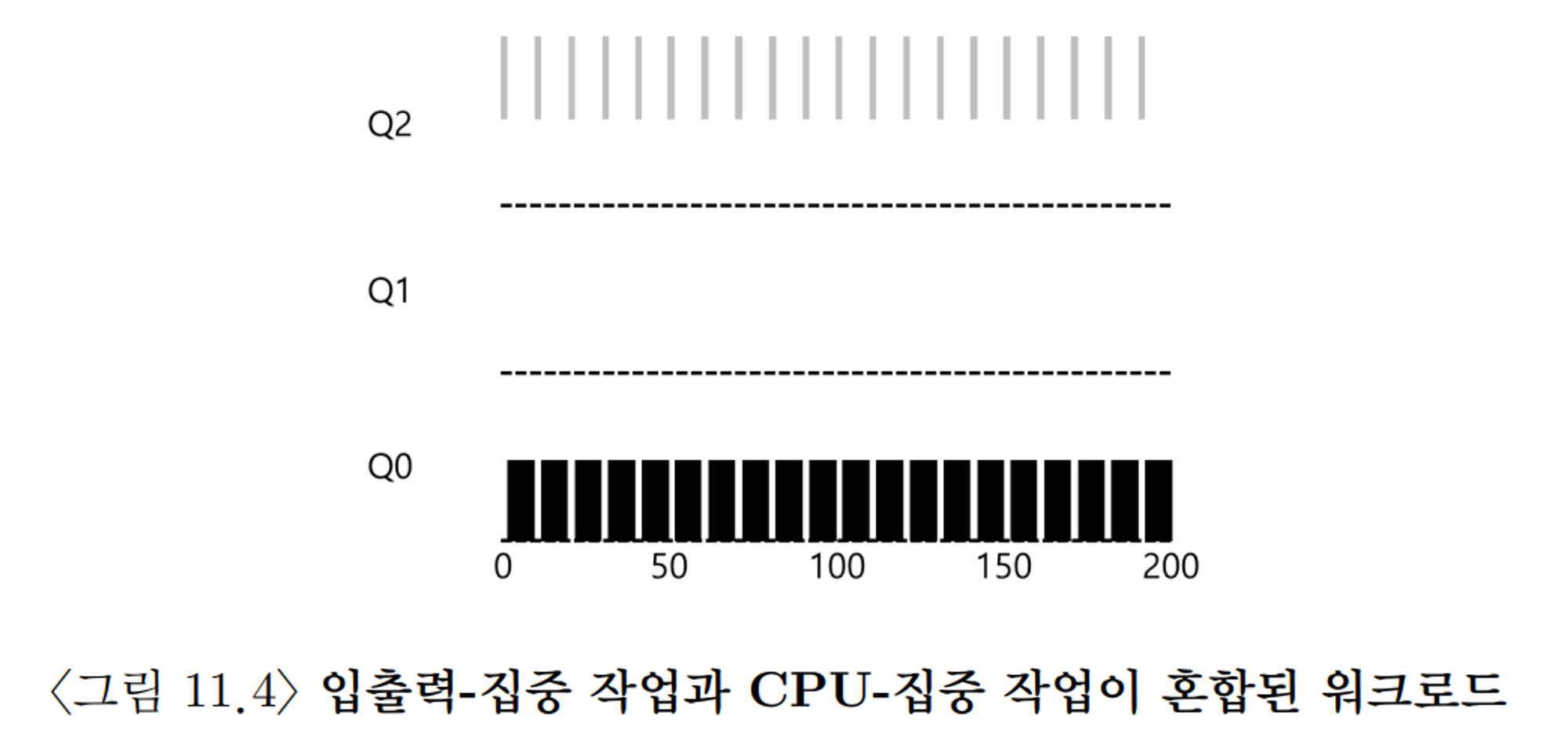
예시
◦
한개의 긴 실행 시간을 가지는 작업
◦
짧은 작업과 함께 들어 왔을 때
◦
입출력 작업을 하는 프로그램과 같이 들어 왔을 때
현 MLFQ 의 문제점
1. 기아상태가 발생할 수 있다.
•
시스템에 너무 많은 대화형 작업이 존재 할 경우 긴 실행 시간 작업은 CPU 할당을 받지 못할 수 있다.
2. 스케줄러가 자신에게 유리하게 작동할 수 있도록 프로그램을 작성할 수 있다.
•
타임 슬라이스의 99%까지 실행하고 아무 파일 대상으로 입출력 요청을 한다면 우선순위가 내려가지 않아 CPU를 독점할 가능성도 생긴다.
3. 프로그램은 시간의 흐름에 따라 특성이 변 할 수 있다
•
초기에는 CPU 위주의 작업이었지만 중간에 대화형 작업으로 성격이 바뀔 수 있는데 현재 구현 방식으로는 이를 처리하기 어렵다.
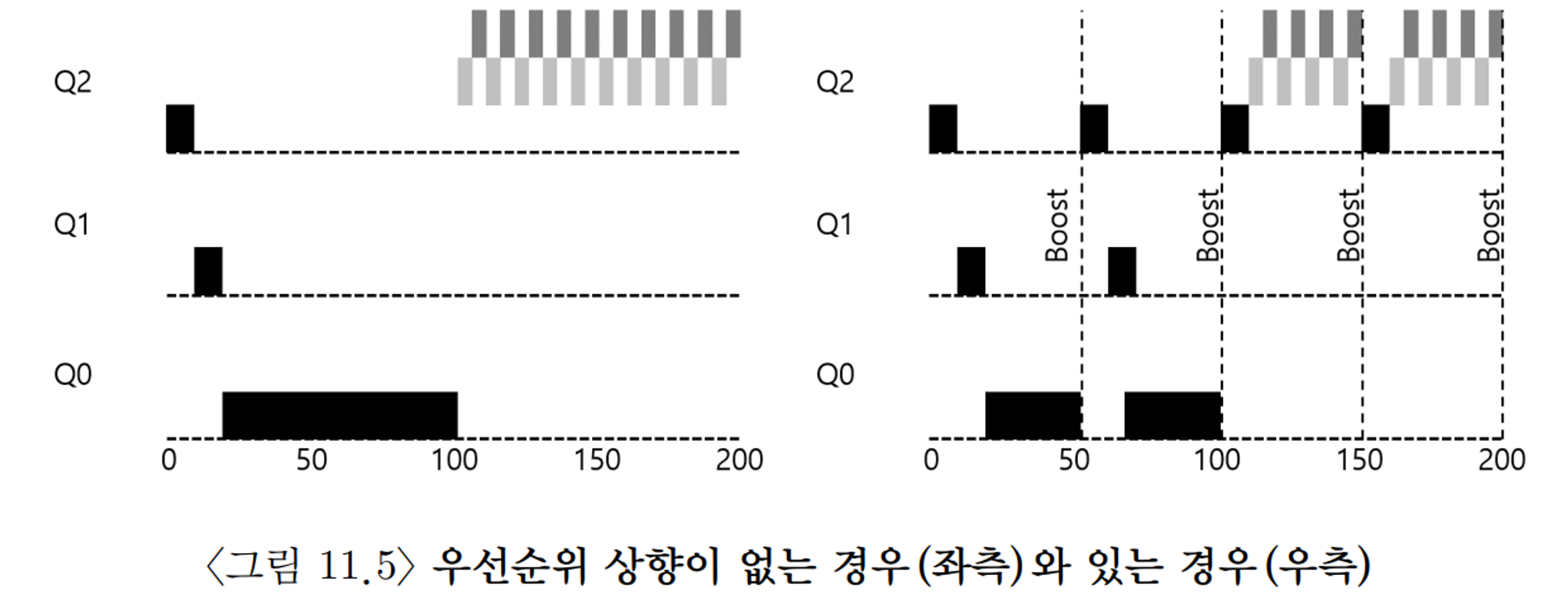
시도 2 : 우선순위의 상향 조정
•
규칙
◦
규칙 5 : 일정 기간 S가 지나면, 시스템의 모든 작업을 최상위 큐로 이동시킨다.
주기적으로 우선순위를 상향 조정 함으로서 상기 제시한 2가지 문제점을 해결할 수 있다. 낮은 우선 순위의 프로세스가 최상위 우선 순위를 가지게 됨으로서 기아 문제를 해결할 수 있다. 또한 작업의 특성이 변하는 경우에도 스케줄러가 변경된 특성에 맞는 스케줄을 할 수 있게 된다.
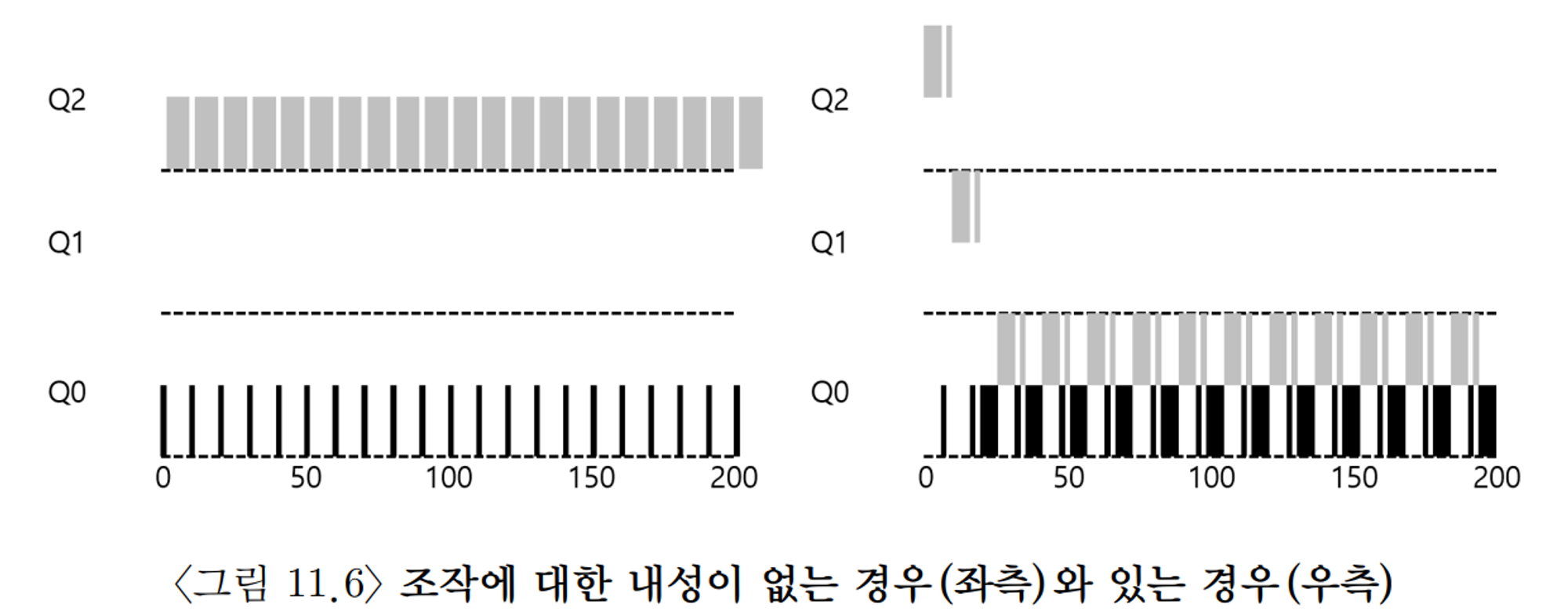
시도 3 : 더 나은 시간 측정
•
규칙
◦
규칙 4 : 주어진 단계에서 시간 할당량을 모두 소진하면(CPU를 몇 번 양도하였는지에는 상관없음), 우선순위는 낮아진다.
아직 스케줄러를 자신에게 유리하도록 동작시키는 것을 막지 못했는데 이는 타임슬라이스를 측정하는 방식을 변경하면 막을 수 있다.
결국 멀티 레벨 피드백 큐는 작업의 실행을 관찰(시간 할당량을 소진하는지?)하여 그에 따른 우선 순위를 지정하고 작업의 특성에 맞게 반환시간과 응답시간을 최적화하는 알고리즘이다. 이런 이유로 BSD Unix와 여기서 파생된 다양한 운영체제에서 기본 스케줄러로 MLFQ를 사용하고 있다.
