



1.Mutex, Semaphore 의 동작 원리는?
락들의 동작내부는 대부분 똑같다.
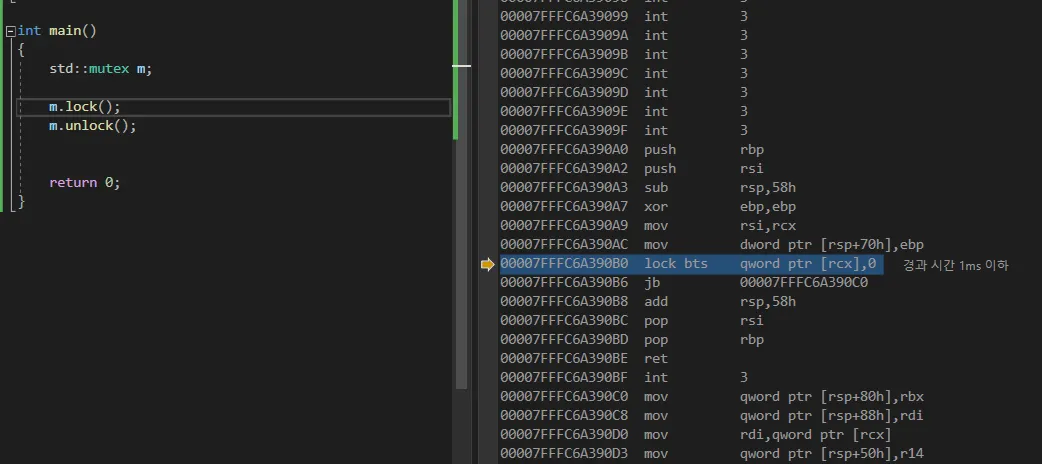
msvc의 std::mutex를 뜯어보면 안엔 lock bts (bit test and set) 이 있다.
atomic operation은 x86에선 명령어 앞에 이렇게 lock 접두어가 붙는다.
결국 어떤 락이든 뜯어보면 내부는 atomic operation이다.
하드웨어의 특수한 지원이 필요하다.
(대부분)
swap(&a, &b) // xchg. (lock exchange)
i++ // lock inc
a += b. // lock xadd (add and exchange)
C++
복사
atomic operation이란?
mutex, semaphore는 어떤 코드영역 에 대해 락을 걸지만
atomic operation은 한 변수에 대해서만 작게 락을 건다.
당연히 mutex같은 락보다 훨씬 빠르다.
#include <stdatomic.h>
atomic_int a; //< a에 적용되는 모든 연산은 원자적임(락상태)
// 아래 연산은 모두 atomic하다. (별다른 락을 걸지 않아도 됨)
a++;
a += 5;
a = b;
C++
복사
2. 애초에 Race Condition 문제가 왜 발생하는가?
Cache Coherence가 보장되는 cpu에서 atomic operation이 왜 필요할까.
하나의 operation은 여러 단계로 쪼개어질 수 있다.
예를 들어 i++ 이라는 코드는 다음과 같은 uop으로 쪼개어질 수 있다.
// i++
load eax, [i]
add. eax, 1
store [i], eax
Assembly
복사
캐시 일관성 프로토콜은 저기서 “store를 수행할 때” 만 다른 코어들의 캐시버스를 잠근다.
그래서 다른 코어의 load 실행을 막지 못하기 때문에 Race condition 이 존재한다.
캐시 일관성(Cache Coherence)(MESI Protocol) 란?
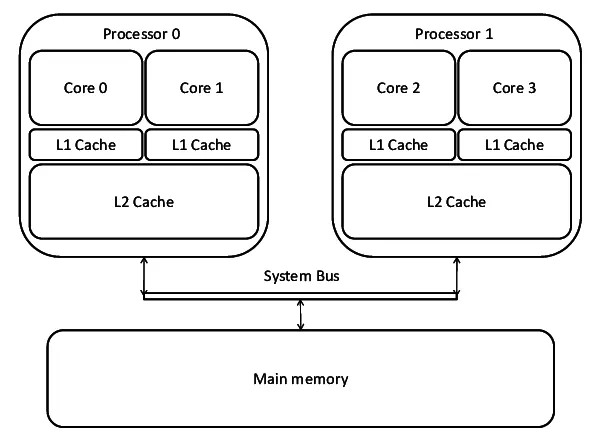
CPU의 코어0의 L1캐시와 코어1의 L1캐시는 독립적이다.
한 프로그램을 멀티스레딩으로 돌린다고 생각해보자.
쓰기스레드는 a = 1 를 하고, 읽기스레드는 a를 관측한다.
이 두 스레드가 별개의 코어에서 실행된다면,
쓰기스레드가 a = 1 를 해봤자,
쓰기스레드의 로컬캐시에만 쓰기가 되기 때문에
읽기스레드는 평생 a == 1 를 관측할 수 없다.
그래서 로컬캐시 내용이 수정되면
다른 코어도 수정된 최신 내용을 업데이트 받아올 수 있도록 하는 기능이
캐시 일관성이다.
우리가 사용하는 cpu 는 대부분 이 기능을 지원한다.
동작원리-
한 코어가 쓰기를 수행하면 다른 코어들의 해당 데이터를 무효화시켜버린다.
(store가 수행되는 동안 다른 코어들이 해당 데이터에 접근하지 못하도록 버스를 잠근다)
그러면 다른 코어들이 들고 있는 데이터는 무효화 된 데이터 이므로,
해당 데이터를 사용하려면 최신 데이터를 들고있는 코어에게서 캐시간 전송으로 받아온다.
성능저하 1. Cache Bus Lock
그렇다면 atomic opertion을 구현되려면,
위 세 단계 모두에 대해서 해당 캐시라인을 들고있는 모든 코어들의 캐시버스를 잠궈야 한다.
그렇게 되면 다른 코어들이 전부 방해를 받고 속도가 느려진다.
(캐시 일관성 프로토콜도 마찬가지. 거기선 false sharing이란 이름으로 알려져 있음)
+
위를 보면 알겠지만, 현재 x86의 atomic은 캐시 일관성의 MESI protocol을 사용해 주로 구현된다.
MESI protocol이 불가능한 프로세서에서는 메모리 버스 전체를 잠궈버리는 식으로 구현된다.
그래서 atomic operation이 mutex같은 lock이 아니지만 lock을 사용하긴 한다.
물론 lock-free는 종류 구분을 위한거라 맞는 말.
성능저하 2. Re-ordering barrior
atomic operation은 out-of-order 프로세서에서 명령어 reorder가 제대로 수행되지 못한다.
그래서 파이프라이닝을 제대로 수행하지 못해 오는 성능저하가 있다.
성능저하 3. Write-combined buffer flush (mfence)
std::atomic 은 연산이 끝난 후,
즉시 다른 코어에서 연산결과를 관측할 수 있어야 하기 때문에 mfence 명령을 동반한다. (lock접두도 mfence)
쓰기가 reorder되거나 버퍼링 되면 결과를 곧바로 기록하지 않아 다른코어의 관측이 느려질 수 있다.
이 mfence는 위에서 말한 reodering 을 제한하기도 하고,
cpu에는 write-combined buffer라고 하는 버퍼가 있는데 이를 flush해야 한다.
cpu에서 bus transaction을 열려면 꽤 많은 시간이 들고,
한 번 열리면 burst mode로 빠르게 전송할 수 있다. (전송이 끝날 때 까지 버스를 release하지 않음)
그래서 write할 메모리를 캐시라인 단위로 모아놨다가 버스 개통시 한 번에 flush 한다.
이게 WC Buffer 이다.
여기서 flush를 해야 한다면 버스를 마스터링 하는 시간 걸리고,
write-combined buffer가 캐시라인 단위로 꽉 채워지지 않았다면
캐시라인 단위로 한번에 전송하지 못하고 워드단위로 하나하나 메모리에 써야한다.
(혹은 DRAM 데이터를 L1까지 끌고와서 하나하나 써야 한다(엄청난 병목))
+(CACHE - DRAM 간의 전송은 워드단위만 가능하지만 CACHE - CACHE 간의 전송은 캐시라인 사이즈로 한 방에 전송 가능하다)
성능저하 4. Context Switching
mutex와 semaphore는 kernel object이다.
kernel space 까지 가야 한다. (아마 60clock 이내)
그리고 락 획득에 실패하면 wait상태로 들어가야 한다.
그러면 다른 스레드에게 cpu를 주고
엄청난 시간을 기다리다 마침내 락을 획득해도
TLB를 갈아야 하고 캐시도 다시 채워넣어야 한다.
(CriticalSection이나 SRWlock 같은 usermode lock 을 애용하자.
context switching 문제는 적당한 상황이라면 spin lock을 사용.
(웬만하면 atomic 선에서 해결하는것이 좋다))
(외전)Spin lock 구현할 때 막 돌리지 마라
위에서 서술했듯이 atomic operation을 수행할 때 마다 다른 코어들의 캐시가 계속 잠긴다.
while (atomic_try_lock() == false)
{
}
C++
복사
이럴 땐, 한 번 atomic으로 try_lock을 검사하고 락을 획득할 수 없다면
x86같은 경우에 pause라는 yield 명령어가 있다. 20-500클럭 정도 대기하는데,
이걸 써서 대기하다가 풀리면 atomic으로 한 번 더 검사하고
그래도 여전히 획득 할 수 없다면 wait상태로 들어가거나 아까 과정을 반복한다.
(pause를 하지 않고 지속적으로 cmp하면 추측실행 메모리 순서 위반으로
파이프라인을 flush해야돼서 느리다는데
그건 잘 모르겠다.
pause의 설명은
Wait for memory pipeline to become empty라고 한다.
그리고 남는 파이프라인를 이용해 하이퍼스레드로 다른 스레드를 수행하고 있을 수 있다)
_SPIN_LOCK:
if (atomic_try_lock())
goto TASK;
while (true)
{
for (int i = 0; i < 1024; i++)
__asm pause; // or _yieldProcessor()
if (atomic_try_lock())
goto TASK;
else
__sched_yield(); // Enter wait_queue
}
TASK:
C++
복사
