

Q)

1.
CPU에 내장된 L1, L2, L3 캐쉬 메모리는 프로그래머가 제어하지 않는지 궁금합니다.
2.
요즘은 다중 코어 CPU 가 개인용 컴퓨터에 일반적인데,
각 코어별로 레지스터(범용, mmx, sse, avx 등)들은 각 코어별로 가지고 있는건가요?
A)

프로그래머는 일반적으로 캐시를 직접 제어할 수 없습니다.
해당 데이터가 어떠한 캐시 레벨에 있는지도 직접 알 수 없습니다.
(물론 데이터 접근속도를 체크하여 간접적으로 알 순 있습니다.
이는 2018년 CPU 최대 보안게이트인 멜트다운의 핵심 아이디어가 됩니다.)
다만 몇 가지 제한된 명령어는 제공합니다.
1. 캐시을 통하지 않고 곧바로 메인메모리에 읽거나 쓰는 simd의 non-temporal hint(movntq 등)
2. 캐시 레벨을 강등시키는 CLDEMOTE(https://www.felixcloutier.com/x86/cldemote)
3. 캐시를 flush 하는 CLFLUSHOPT(https://www.felixcloutier.com/x86/clflushopt)
4. 캐시 prefetch 힌트 PREFETCHWT1 (https://www.felixcloutier.com/x86/prefetchwt1)
5. 등...
1번의 non-temporal hint는 3N 면접에 나왔다고도 들어서 꽤 쓰는 것 같지만
나머지는 잘 쓰지 않는 것 같습니다.
(nt hint 는 다음 글 참고 https://80000coding.oopy.io/551ed685-37b2-480c-aaa3-8f4996e26c4f)
과거에는 cache prefetch를 프로그래머가 직접 하는 경우가 꽤 있었고
하드웨어에서도 그것을 명령어로 지원했던것으로 압니다만,
현대 CPU에서는 "힌트"(CPU가 무시할 수 있음) 수준으로만 주로 제공합니다.
(Xeon 시리즈에서는 예외적으로 캐시 관련 명령어를 좀 더 지원해주는 것 같습니다)
이유는 Cache와 Hardware cache prefetcher가 엄청 발전했기 때문입니다.
현대 CPU의 cache prefetcher는 데이터의 접근 패턴을 분석하고,
다음에 접근할 데이터를 예측하여 미리 cache를 prefetch 할 수 있습니다.
그래서 프로그래머가 직접 캐시를 제어하는것 보다,
cache friendly한 자료구조를 사용하고 데이터 접근 스탭 패턴을 일정하게 하는것이
오히려 더 많은 성능을 낼 수도 있습니다.
(https://en.wikipedia.org/wiki/Cache_prefetching)
예로, 2차원 배열을 순회할 때,
for (int i : row)
for (int j : col)
arr[i][j]
Plain Text
복사
위와 같이 row/col 순으로 접근하는게,
col/row 순으로 접근하는 것 보다 빠릅니다 (캐시라인 때문).
하지만 col/row 순으로 접근해도 "그렇게 까진" 느리진 않습니다.
왜냐하면 col/row 순의 데이터 접근 패턴이 일정하기 때문에
hardware cache prefetcher가 다음 데이터를 예측해서 미리 prefetch 하기 때문입니다.
row/col, col/row, ramdomly 배열 접근을 측정해보시면
랜덤하게 접근하는 속도가 매우 뒤떨어집니다
row/col < col/row <<<< ramdomly
2. 각 코어마다 고유의 Physical Register File을 가집니다.
[1](full overview of the Intel Skylake microarchitecture.)
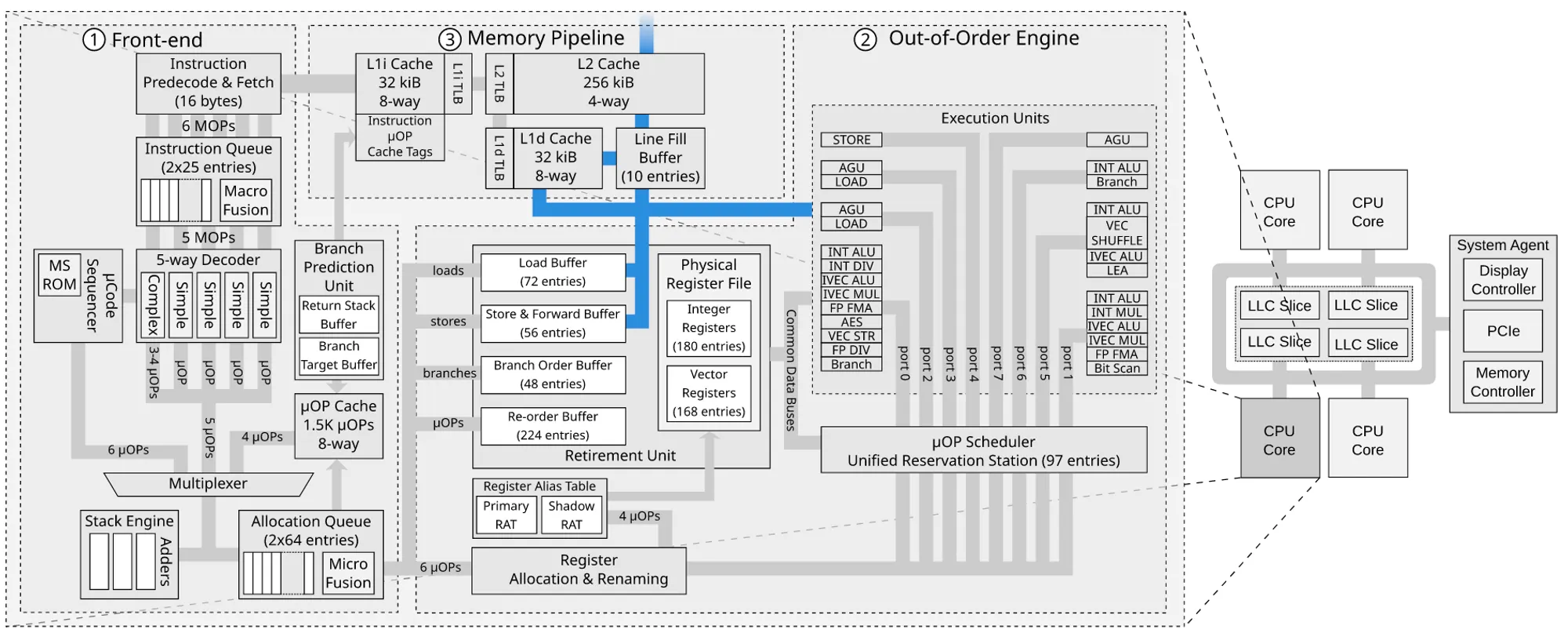
SMT(HyperThread) 에서도 각 논리스레드가 각각의 레지스터를 가집니다.
(Intel Architecture Software Optimization manual chapter 2.3.9.)
•
Duplicated for each HT thread: the registers, the return stack buffer, the large-page ITLB
•
Statically allocated for each HT thread: the load, store and re-order buffers, the small-page ITLB
•
Competitively shared between HT threads: the reservation station, the caches, the fill buffers, DTLB0 and STLB.
 51
51