

c언어를 처음 배우기 위해 교재에 적힌 코드를 MSVC(Microsoft visual c++ compiler)에서 사용하면 다음과 같은 경고 메세지와 함께 컴파일을 거부 당한 경험이 있을 것이다.
‘scanf‘: this function or variable may be unsafe. Consider using scanf_s instead. …(생략)
무엇이 문제인지 검색해보면 보안 문제 때문에 개선된 함수를 사용하라는 경고라고 알려주지만 컴퓨터 구조에 대한 이해가 적을 때는 경고 문구가 와닿지 않아 무시하는 방법을 찾고는 했다.
이번에는 컴퓨터 구조, 원리와 함께 위에서 언급된 보안 문제가 정확히 어떤 문제를 뜻하는지 알아보려고 한다.

이번 글은 cpu의 작동 방식 부터 c언어의 함수가 작동하는 방법까지 단계적으로 설명할 것이다.
보통 전공 수업에서도 한번에 배우는 내용은 아니기에, 어렵다면 실습부터 확인해도 무방하다. 그러나 왜 이런 문제가 발생하는지 궁금하다면 천천히 따라오는 것을 권한다.
목차
스택의 구조
cpu의 구조 - 캐시
보통 c언어를 공부할 때 cpu가 메모리에 있는 정보를 불러온다고 배우지만 사실 그 중간에 생략된 과정이 있다.
cpu는 ram에서 정보를 불러오지만 ram 또한 정보를 불러오는 속도가 cpu의 속도보다 느리다. 따라서 이를 보완하기 위해 cpu에는 캐시라는 고속 메모리가 있다.
데이터를 불러오거나 저장을 할 때 인터럽트(interrupt)라고 불리는 과정이 있다. 이는 cpu의 처리 속도보다 데이터가 이동하는 속도가 현저히 느리기 때문에 저장/불러오기가 완료 될 때 까지 cpu가 대기하는 상황을 이야기한다. 인터럽트가 자주, 길게 존재 할수록 컴퓨터의 처리 속도는 느려질 수 밖에 없다. 따라서 자주 접근하는 데이터는 캐시에 저장하여 속도 문제를 극복하려 한 것이다.
캐시는 크기와 속도에 따라 3개로 나누어진다. (각 계층마다 용도도 나누어지지만 다른 글에서 다루겠습니다)
1.
L1 캐시:
•
가장 가까운 캐시로, CPU 코어에 위치한다.
•
몇 KB 정도의 용량을 가지고 있다.
2.
L2 캐시:
•
여러 코어가 공유하는 레벨 2 캐시로, L1 캐시보다 크기가 크고 속도가 상대적으로 느립니다.
•
몇 MB 정도의 용량을 가집니다.
3.
L3 캐시:
•
여러 코어가 공유하는 레벨 3 캐시로, 더 큰 용량을 가지고 있지만 속도는 더 느리다.
•
몇 MB에서 수십 MB까지의 용량을 가질 수 있다.
따라서 cpu가 데이터를 레지스터에 저장하는 과정은 다음과 같다.
1.
cpu는 1순위로 L1캐시를 확인한다.
2.
만약 L1 캐시에 필요한 값이 없다면 L2 캐시를 확인한다.
3.
L2 캐시에 필요한 값이 없다면 L3 캐시를 확인한다.
4.
L3 캐시에 필요한 값이 없다면 주 기억장치 혹은 보조 기억장치에서 필요한 값을 불러온다.
cpu의 구조 - 레지스터
cpu에는 캐시말고도 현재 상태, 임시 변수, 현재 주소 등을 저장하는 레지스터라는 저장공간이 존재한다. 연산장치는 임시 변수에서 값을 불러와 연산 후 저장하고, 컨트롤러는 현재 상태나 주소를 참고하여 cpu의 행동을 결정한다. 앞으로 자주 다룰 레지스터는 다음과 같다.
•
PC (program counter) : cpu가 다음에 실행할 명령어의 주소를 가리킨다. 보통 명령어를 불러온 후 명령어의 길이만큼 값이 늘어난다. 혹은 분기 명령어가 있을 경우 해당 주소로 변경된다.
•
SP (stack pointer) : 스택의 끝 주소를 담고 있는 레지스터다. 스택에 push하거나 pop할 때 변경된다.
•
BP (base pointer) : 스택의 시작 부분을 가리키고 있다(정확히는 그 아래 return 주소이 저장되고 그 위에 base pointer의 값이 담긴다) base pointer위에서 부터 변수의 값이 저장된다. 따라서 변수에 접근할 때 기준점으로 사용된다.
•
IR (instruction register) : 현재 실행중인 명령어의 주소를 담는다.
cpu instruction cycle
우리가 프로그램을 실행할 때 스택에는 변수들의 정보와 작성한 명령어가 컴파일되어 메모리에 저장된다. cpu는 메모리에 저장된 명령어를 순서대로 읽어가면서 프로그램을 실행할 수 있는 것이다. 이를 그림으로 나타내면 다음과 같다.
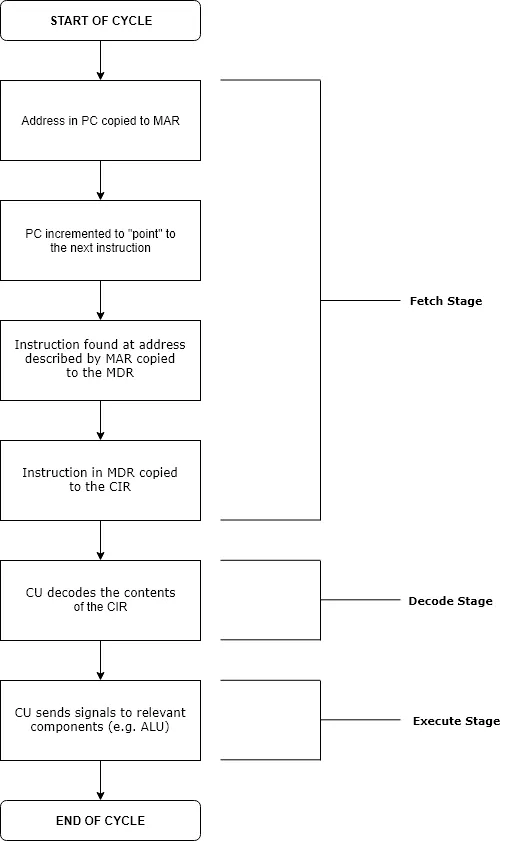
cpu는 instruction cycle이라는 과정을 통해 명령어를 실행하며 cycle의 각 과정은 다음과 같이 3단계로 이루어진다.
•
Fetch :
1.
pc에 저장된 값을 MAR(memory address register)에 전송한다.
2.
MAR에 저장된 주소에서 얻은 명령어를 MDR()로 저장한 후 CIR(instruction register)에 저장한다.
3.
다음에 실행될 명령어를 pc에 저장한다. (이 때 분기가 정해져있다면 해당 주소로 변경될 것이고 그게 아니라면 실행한 명령어의 크기만큼 늘어난다) pc에 저장된 내용은 다음 순환에 사용된다.
•
Decode : CU(control unit)는 CIR에 저장된 값을 해석하여 cpu의 행동을 결정한다. 예를 들어 add였다면 excute시 ALU(arithmetic logic unit)에 작동 신호를 것이다.
•
Execute : decode 단계에서 정해진 행동을 실행한다.
어셈블리 언어의 함수 구현
혹시 어셈블리언어를 접해본적이 있는가?
c언어와 달리 어셈블리 언어에서 함수를 사용하려면 다음과 같은 절차가 필요하다.
1.
현재 레지스터에 저장되어있는 정보를 저장한다.
2.
새로운 정보를 레지스터에 저장 한다.
3.
함수의 명령어 주소로 이동한다.
4.
함수가 끝났다면 저장했던 레지스터 정보를 복구한다.
int add(int a)
{
return (a + 1);
}
int main()
{
int a = 3;
a = add(a);
return (0);
}
C
복사
예를 들어 다음과 같은 c 코드를 어셈블리 언어로 변환 하면 다음과 같다.
Assembly
복사
생소한 구조이지만 생각보다 복잡한 내용은 아니므로 걱정할 필요는 없다.
일단 여기서는 다음과 같은 명령어들이 사용되었다. (어셈블리어는 at&t와 intel문법으로 나뉜다. 여기서는 intel 문법을 따르겠다)
변수 목록
mov : 첫 번째 인자에 두 번째 인자의 값을 복사한다
push : 스택의 맨 윗 부분(top)에 인자로 전달된 값을 저장한다
pop : 4바이트 데이터(32bit 기준)를 스택의 윗 부분에서 빼낸 후 인자로 전달된 곳에 저장한다.
add : 2개 인자를 더해서 첫 번째 인자로 전달된 곳에 저장한다.
xor : 전달된 인자끼리 xor연산하여 첫 번째 인자로 전달된 곳에 저장한다.
call : 함수를 호출할 때 사용하는 명령어, 스택에 현재 코드 주소를 push하고 테이블에 지정된 주소로 jump한다.
ret : 함수를 끝낼 때 사용하는 명령어, 스택에서 현재 주소를 pop하고 다음 주소로 jump한다.
mov add xor ret 명령어 (그 외 2개 인자를 사용하는 명령어)는 두 개 인자 모두 mem으로 사용하는 것은 허용되어 있지 않다.
우리는 여기서 push, pop, call, ret을 중점으로 설명하겠다.
Assembly
복사
먼저 main문이 시작한 시점부터 add함수를 호출할 때 까지의 스택 변화를 보여주겠다.
esp 와 ebp는 각각 스택의 끝 부분과 시작 부분의 위치를 저장한다.
1.
push ebp는 스택에 스택의 시작 부분을 백업해놓고 프로그램이 끝날 때 복구하기 위함이다.
2.
mov ebp, esp sub esp, 24esp : esp에 ebp에서 24바이트를 뺀 값을 할당한다. 이는 main의 스택 크기를 24바이트로 사용하겠단 뜻이다.
3.
스택에 a변수의 값을 저장한다. 각각 4바이트의 크기를 사용할 것이며 0은 a의 초기화 값, 3은 이후 할당해준 값이다.
4.
eax에 a의 값을 저장한다. eax는 여기서 함수를 호출할 때 인자를 저장하기 위해 사용된다.
이를 그림으로 표현하면 다음과 같다.
Assembly
복사
64비트 시스템의 레지스터
여기까지가 스택과 cpu작동 방식에 대한 설명이였다. 이제부터 소개할 것은 buffer overflow attack으로 불리는 공격기법으로, 해당 공격을 통해 공격자가 의도한 악의적인 프로그램을 작동시키는 것을 보여줄 것이다.
실습
작동 환경
작동환경은 ubuntu 20.04 버전을 활용했으며 다음과 같은 패키지를 사용하였다.

실행 코드
방어 방법
스택 스매싱 공격에 대한 방어방법은 다음과 같은 방법이 있다.
alsr
위에서 실습했을 때 우리는 특정 명령어가 어느 부분에 존재하는지 확인하며 시도해보았다. 이는 메모리에 스택이 생성되는 규칙이 동일하기에 가능한 것이다. alsr은 스택의 구조를 랜덤으로 변형시켜 해커가 특정구역을 찾지 못하도록 막는 방법이다. 다만 이렇게 랜덤화 해도 브루트포스로 시도하거나 다른 방법(ROP)으로 공격할 수 있기에 공격이 어려워질 뿐 불가능해지진 않는다.
stack canaries
스택의 특정 부분에 손상을 탐지하는 부분을 할당하는 방법이다.
non executable stack
스택에서 쉘 코드를 실행할 수 없게 하는 방법이다.
입력 검증
글의 맨 처음에서 나온 _s 함수에 해당하는 내용이다. 위에 나온 방법들은 모두 예상하지 않았던 길이를 입력시켜 오버플로우가 발생한 것이다. 따라서 애초에 적절한 입력만 받아들인다면 위에 해당하는 사항이 발생하지 않을 것이다.
결론
보안은 마치 창과 방패와 같다. 공격자가 끊임없이 취약점을 찾는다면 방어자는 끊임없이 그 취약점을 보완하는 것이 목표다. 취약점은 굉장히 사소한 부분부터 시작할 수 있다. 그러나 그런 취약점이 연계되어 결국은 큰 보안 허점이 되기에 사소한 위험이라도 항상 조심해야한다.


