



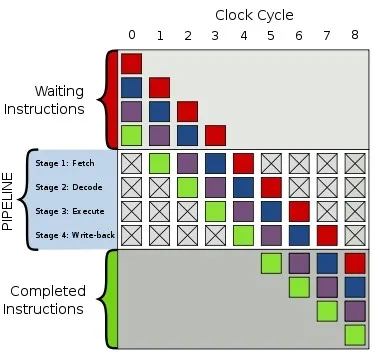
파이프라인 병목
cpu는 효율성을 위해 파이프라인(pipeline) 이라는 구조를 사용한다.
이 파이프라인에 명령어(코드)를 한줄한줄 집어넣어서 동작하는데,
if문, 즉 분기문을 만나면 다음에 오는 명령어는 2가지 경우의 수가 생긴다.
이 다음에 올 명령어를 if문이 계산되기 전 까지 알 수 없으므로
cpu는 if문이 계산되는 동안 놀게 된다. (control hazard)
비트연산을 사용한 해결 방법
간단한 해결방법으론, 분기를 없애버리면 된다.
이는 비트연산 등으로 가능하다.
예를 들어 절대값을 구하는 과정을 바꿔보자.
(이런 간단한 로직은 컴파일러가 알아서 비트연산 등으로 최적화 해준다.)
코드는 다음과 같을 것이다
int n = read();
if (n < 0)
n = -n;
C
복사
if 분기가 있으므로 느려질 수 있다.
이 코드는 분기를 없애 다음으로 바꿀 수 있다
int n = read();
int mask = (signed int)n >> ((CHAR_BIT * sizeof(int)) - 1); // Bit filling by MSB(sign bit)
// Trans sign only negative number
n ^= mask;
n -= mask;
C
복사
인라인어셈으로 작성할 수도 있다.
int n = read();
__asm
{
mov eax, [n]
cdq //extend eax to edx(make bitmask by signbit)
xor eax, edx
sub eax, edx
mov [n], eax
}
C
복사
물론 이러한 방식은 복잡하다.
이보다 간편하고 보편적으로 빠른 방식이 존재한다.
분기 예측
그래서 이걸 해결할 기가 막힌 아이디어가 하나 있는데,
분기문 이걸 그냥 때려맞혀버리면 된다. (Branch prediction)
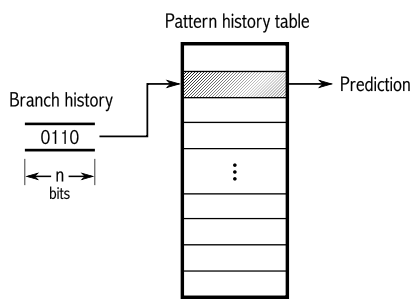
예측은 과거 분기를 했는지 히스토리 2회분 정도를 보고 결정한다.
이러면 대충 예측률 8-90% 정도 나온다
보통 분기는 한쪽을 더 많이 타는 경향이 있기 때문에 가능하다.
예시로 반복문은 반복할 확률이 높을 것이다.
대신 실패하면 예측했던 분기의 연산결과들을 전부 버리고 복구해야 하는 리스크가 있다.
그래도 현대 cpu에선 예측률이 90%를 넘어가므로 사용한다.
여기서 추가로 주변 분기문들과의 연관성을 파악해 예측률을 더 끌어올릴 수 있다.
여담
1.
여전히 예측 확류이 낮은 경우(abs() 등) 는 비트연산으로 해결해야 한다.
또한, 컴파일러는 만능이 아니다.
컴파일러는 어떤 데이터가 들어올 지 모르므로 보통 범용적으로 좋은 코드를 작성해준다.
데이터에 맞춰 맞춤형으로 작성할 수 있어야 한다.
2.
히스토리 테이블은 direct memory mapping(직접사상) 방식으로 구현 가능하다.
(명령어 주소의 하위비트로 룩업하여 사용)
3.
비슷한 원리로 Cache에서 데이터를 가져올 때, 다음 가져올 주소를 예측하여 미리 prefetch 한다.
그래서 일정한 간격으로 메모리 접근하면 랜덤하게 접근한 것 보다 빠르다.
이건 본인의 다른 글 참고
(https://ria9993.github.io/cs/2022/10/04/cache-prefetch.html)
