


일반적으로 많이 안씀.
대부분 서버쪽이 많이 관심가질듯
내가 쓰는 패턴만 보여줌.
멀티스레딩의 목적 : 성능을 최대한 뽑기위해
응답성과 처리량은 차이가 있고 멀티스레딩을 한다고 응답성이 오르진 않는다.
처리해야하는 데이터가 많아서 응답성이 떨어지는 경우 응답성을 높일 수 있다 이게 제일 쓸모있는 상황
소켓프로그래밍 같은거할때 io, 상대적으로 시간이 많이 걸리는 작업들, file 입출력 등등 이런거 처리할때 os에서 io작업경우 비동기 api를 제공해주긴하는데 셋업과정이 귀찮거나 필요없는 기능들이 있어서 복잡하고 헷갈리는 경우가 많음
그래서 동기적 api를 쓰길 원하는데 그러자니 지연이 많이 생기기에 이런 걸 해결하고자 동기적 api를 비동기처럼 사용하기 위해 멀티쓰레드를 쓰기도 함
예를들어 connect 함수 같은경우가 대표적으로 있는데 block mode로 connect를 사용하게 되면 반응이 굉장히 느리다 접속을 해도 느린데, 접속이 빨리 안되는 경우에 굉장히 느리게된다 이런걸 백그라운드로 돌려서 비동기 api쓰는 느낌으로 쓸 수 있다.

라이트맵, 복셀은 생략
데모1
5천만개의 숫자로 된 난수를 만들어서 max값과 min값을 구하는 예제
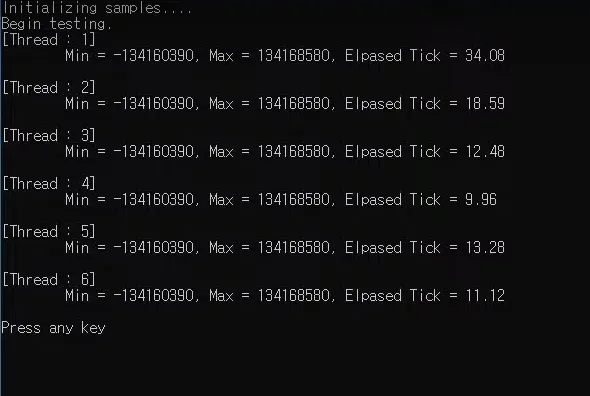
5개일때 시간이 늘어난부분 : 쓰레드 중 하나가 os 스케줄링에 따라 wait를 했다가 왔을 것.
일반적으론 갯수가 많아질수록 빨라짐.
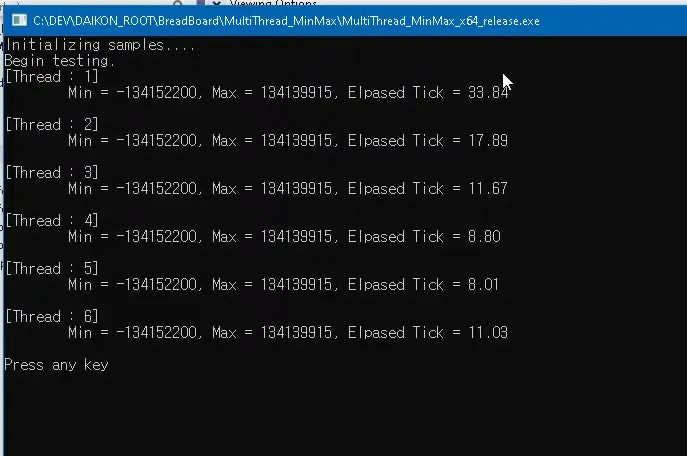
1개 → 2개는 1.8배의 성능향상이 있음
암달의 법칙 : 스레드 갯수가 늘어나는 만큼 정비례하지 않음
최신 cpu들은 전 코어가 터보부스터 적용을 받을 수 있다고 하는데 일반적으로 코어가 활성화 되는 코어가 많으면 클럭이 떨어짐 쓰레드 갯수를 늘리면 늘릴수록 클럭이 떨어짐
+동기화에 필요한 성능저하 : wait생기거나 bus가 잠겨서 다른 코어가 영향 받는 부분
락을 걸 필요가없거나 아주 잠깐의 락만을 걸 수 있다면 정비례에 가깝게 성능향상이 있음
데모 2
이미지가 크고 이미지 필터를 블러와 엣지를 거는 상황
엣지 필터
싱글쓰레드
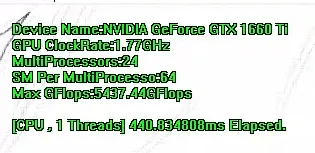
440.83ms

12쓰레드 91ms
하이퍼쓰레딩 ⇒ 물리코어 6코어
실질 활성화된 쓰레드는 6대라고 봐야함
결과론 4배보다 좀 더 나옴.
⇒ 4배정도 성능향상, 근데 CUDA쓰면 훨씬 빠름



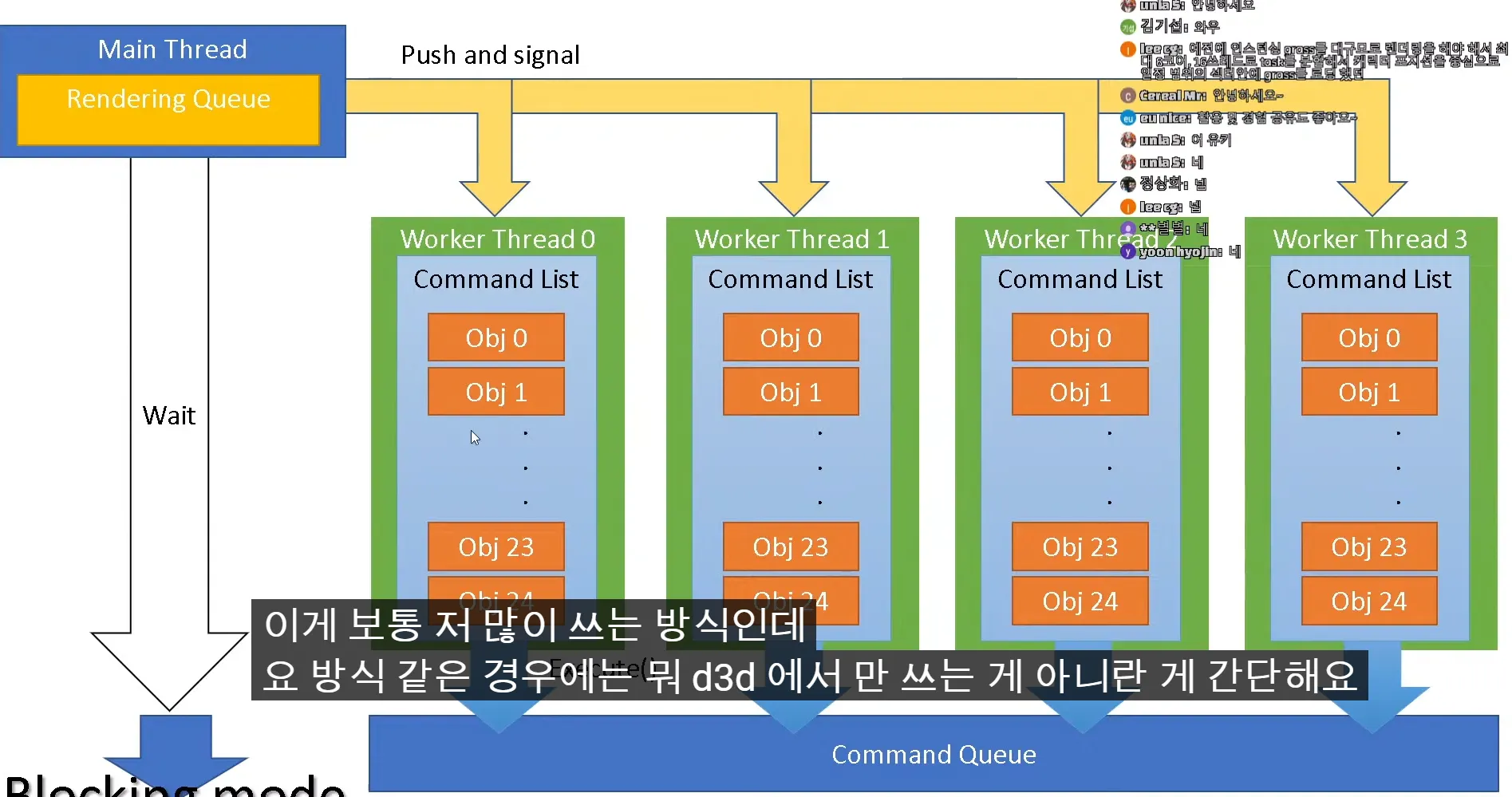
렌더링할 오브젝트가 100개가 있으면 스레드가 4개있으니 25개씩 할당 main은 wait
싱글 스레드 프로그램에서 성능을 선형으로 올리 수 있는 방식
중간에 wait가 생기는 방식
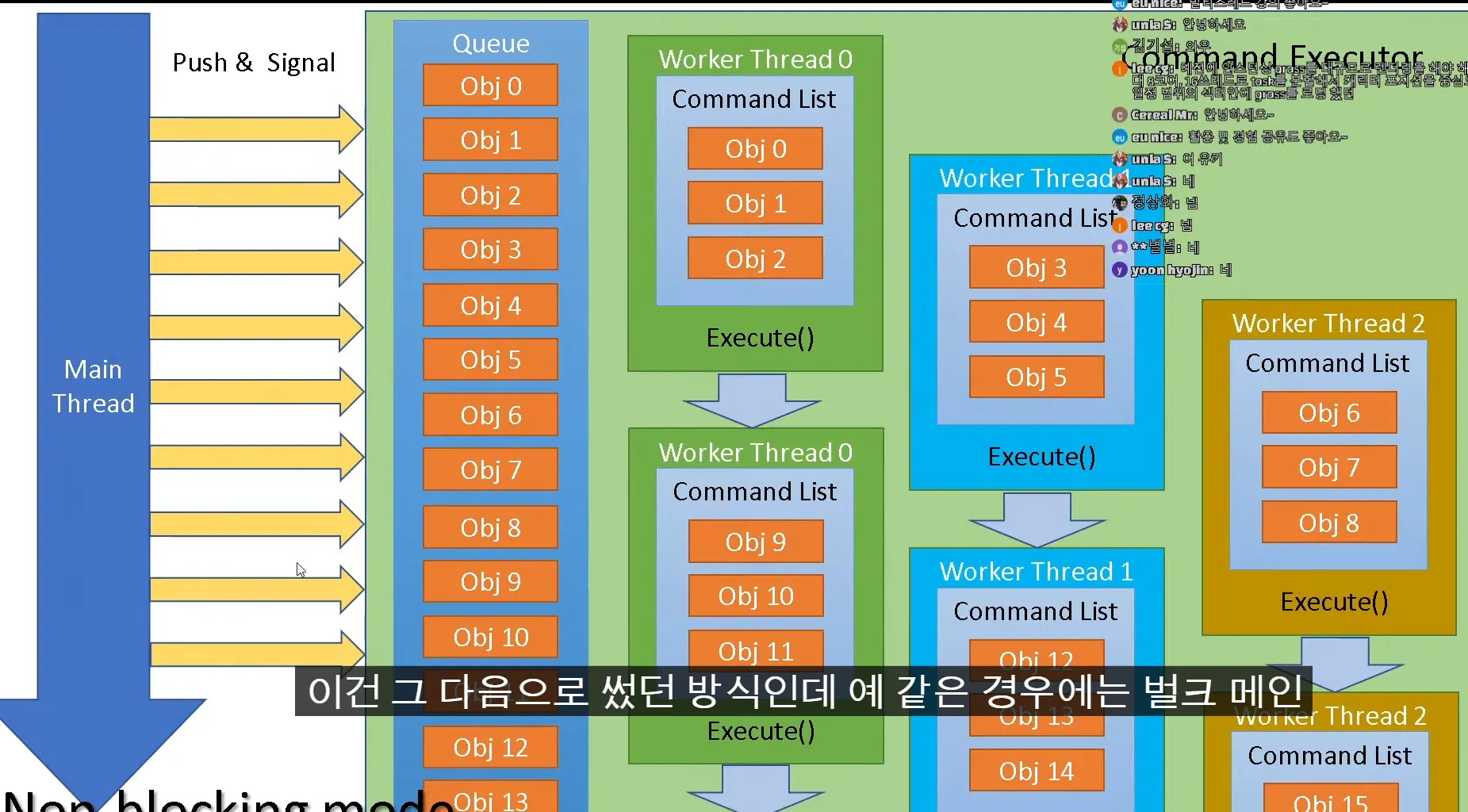
main thread가 wait하지않은 백드라운드의 렌더링 스레드와 main스레드가 동시에 진행하기 위함
main스레드가 계속 큐에서 쑤셔넣으면 woker thread들이 계속 큐에서 데이터 뽑아서 처리
전체 처리량은 앞의 상황이 많이 할 수 있음 그런데 wait가 있어서 gpu 생각을 안하면 main이 wait되도 상관없는데 이런 방식은 gpu가 놀 수가 있음
후자의 경우 gpu가 노는 경우는 없는데 최대치로 사용할 수 있다는 보장은 없음

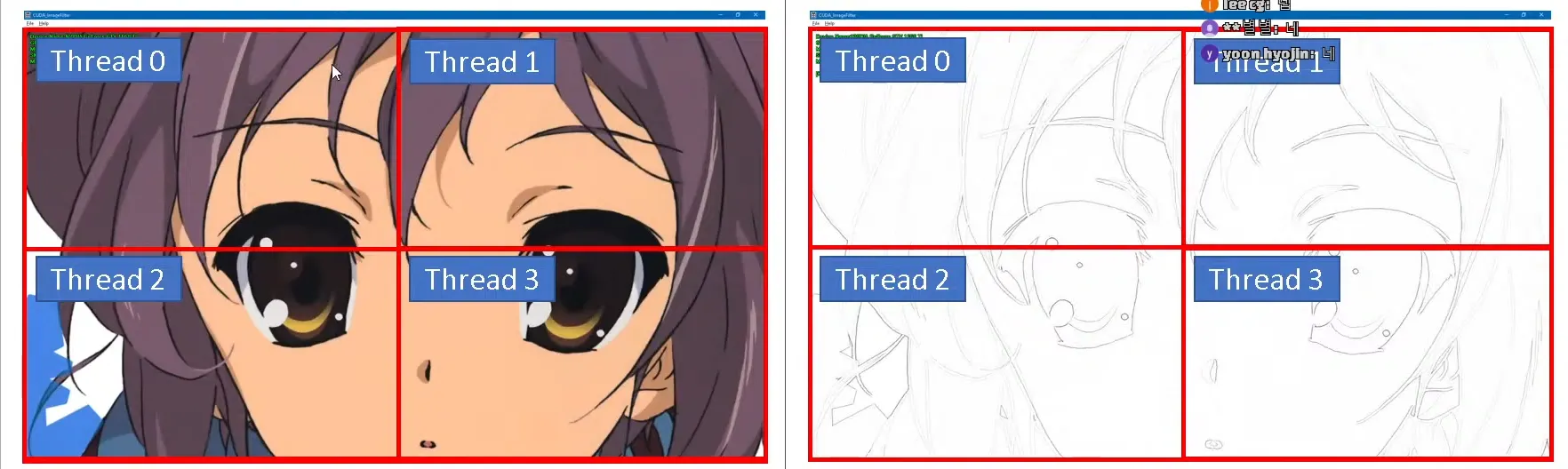
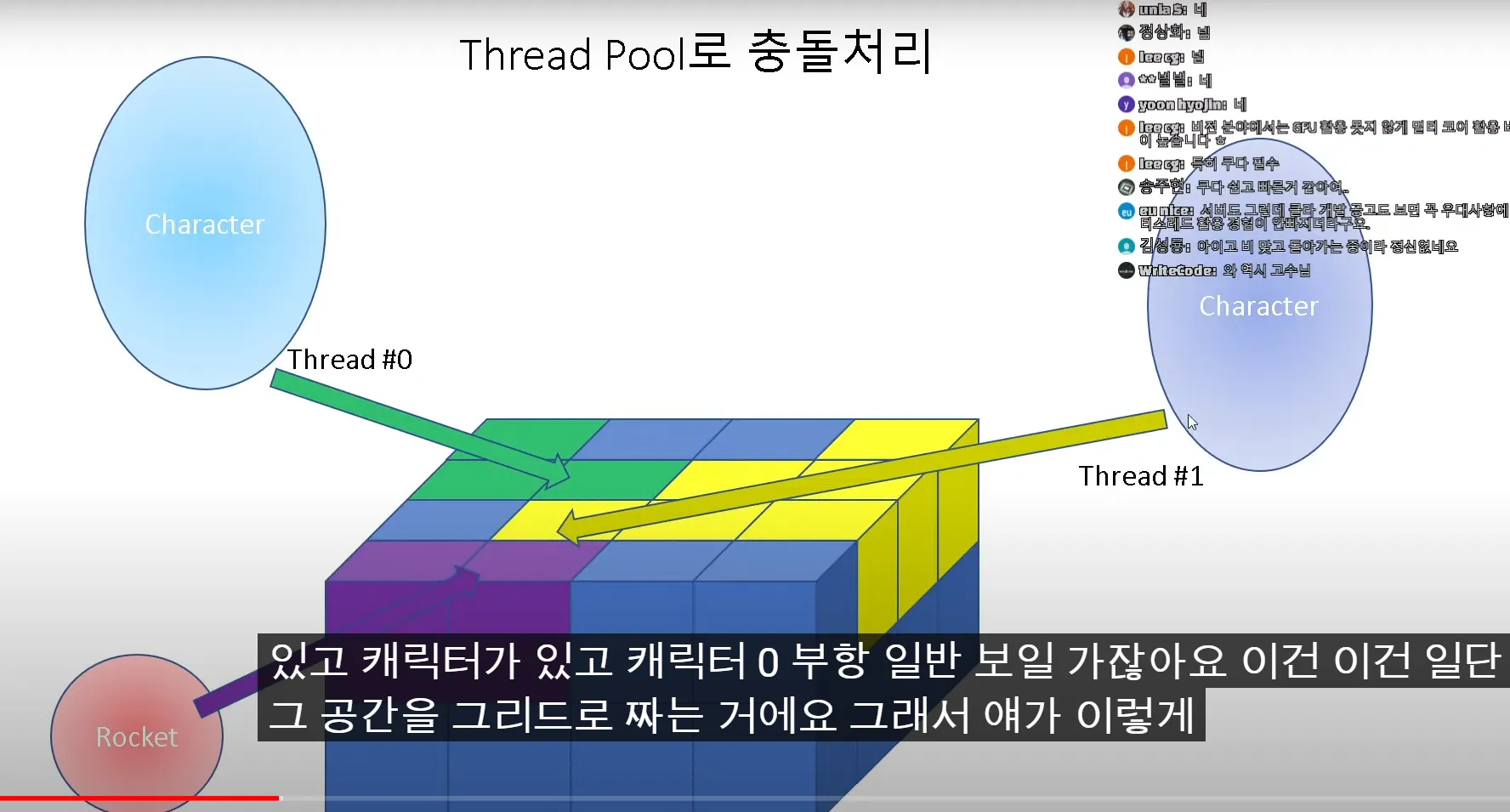
대상 시스템(서버 컴퓨터) 스레드 갯수 센다음 그만큼 만들어서 가로세로 분할
커널 필터 단위로만 정렬해서 이미지 짜르면 if 비교없이 곧바로 적용할 수 있고
동기화 할 필요도없고 가장 이상적인 상황
근데 좀 웃긴게 대부분의 경우 cpu에서 이미지 처리할 일이 없다.
gpu로하면 100배는 빠름
CUDA쓸 수도있고 CUDA안되면 openCL쓸 수도있음

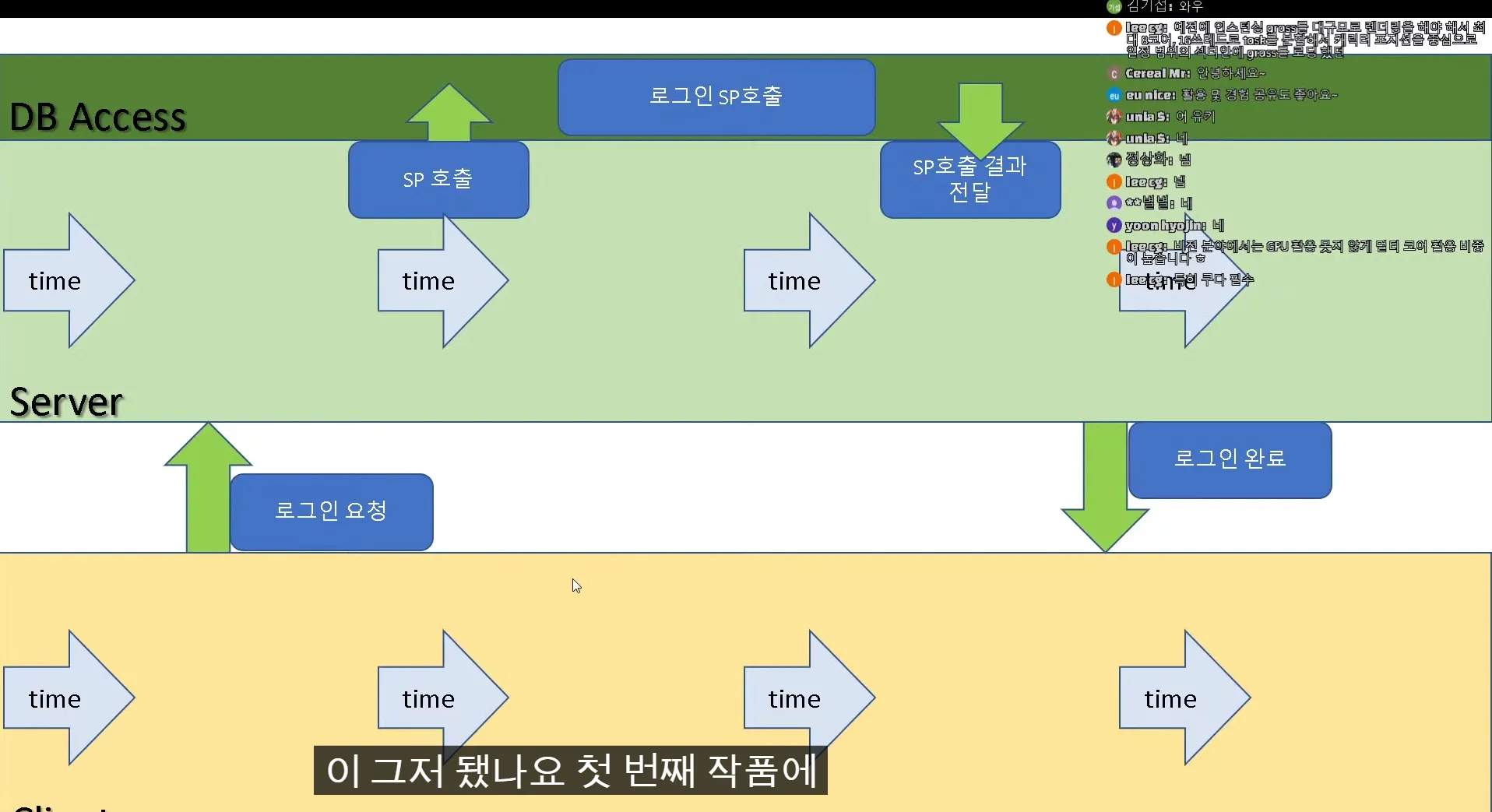
DB처리 socket 처리 등등 모두 이 방식으로 해결

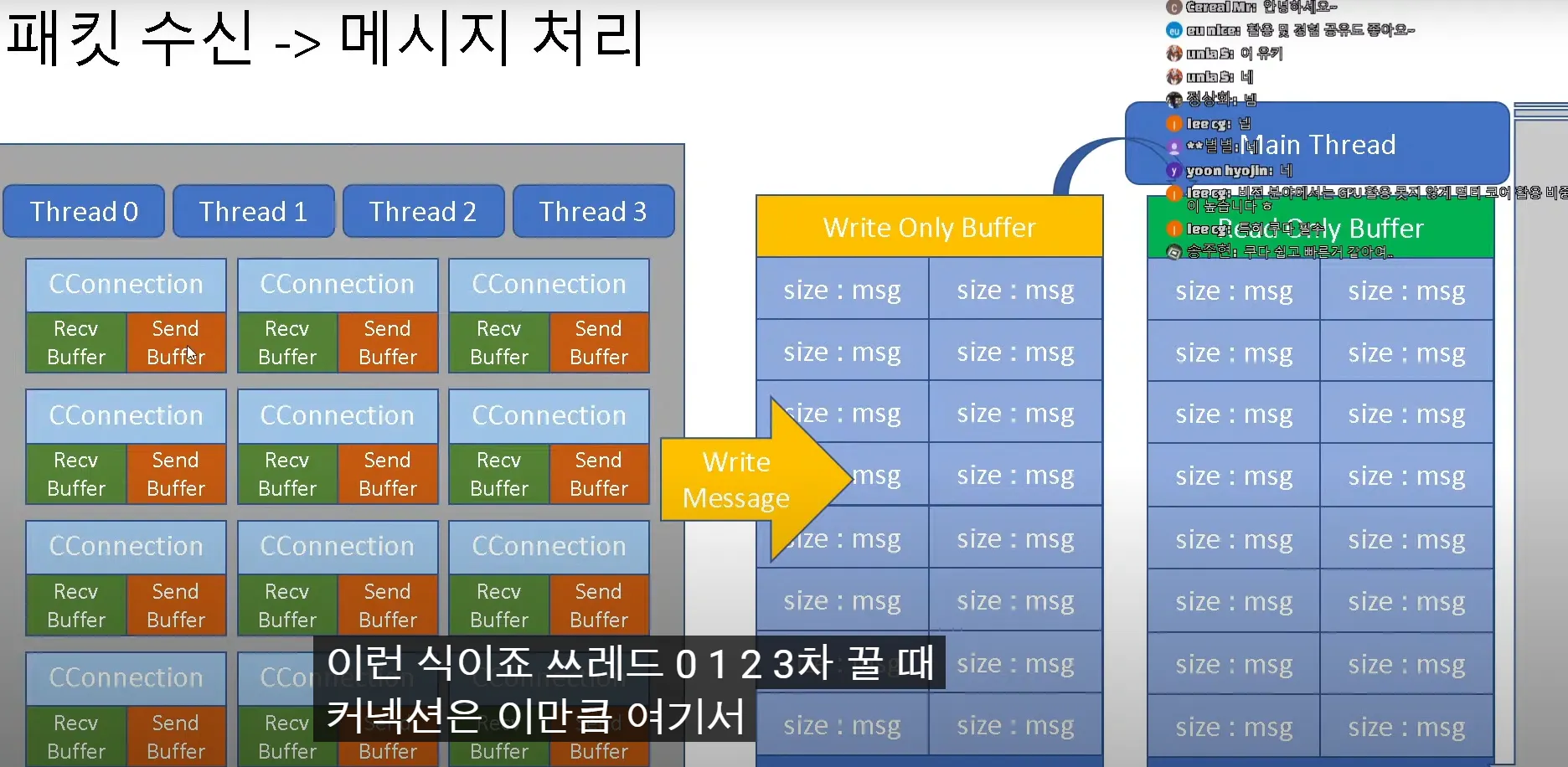
IOCP
스레드 풀에서 패킷을 수집하거나, 보냈는지 확인하게, woker thread들이 하는 일인데
패킵을 수집해서 서버쪽에 올려줘야하는데 서버의 main thread가 읽을수 있는 어떤 버퍼 하나가 내용을 넣어줘야하는데 lock을 안 쓸 순없는데 제대로 활용을 못하면 싱글 스레드만 못한 상황이 놓일 수도있다.
double buffering ..
저번에 서버 최적화 전략 강의에서 얘기함
락에서 많은 비용을 지불하지만 않는다면 코어 갯수만큼의 스레드는 사용해야 패킷들을 빠르게 처리가능
멀티스레드의 필요성 : 웹서버가아니라면 멀티쓰레드를 쓰긴써야댐 웹 서버 기반 환경이아니라면 예전에 만든 서버를 쓸 거다 그러니 유지보수를 위해 쓸 줄 알아야한다

온라인게임에서 서버에서 멀티쓰레딩이 가장 많이 필요한 부분.
가지고있는 코어를 최대한 활용.
이미지 프로세싱이나 오프라인 렌더링이 필요한 것들은 gpu가 압도적으로 성능이 빠름
예시

제일 중요한 내용
mulit threading 코드 직접 짜봐야지 암

윈도우 기준
C++에서 제공해주는 표준 동기화 안씀
멀티쓰레드 관련해서는 디버깅을 위해서라도 로우레벨 한 부분을 감춰선 안된다고 생각함.
capsulation 안좋아함
mutex 세마포어 안씀
결론 : SRWLock을 추천함 사실 SRWLock보단 내가만든 spin lock을 훨씬 많이 씀
때로 커널상의 waiting (os가 스케줄러에서 스레드를 밑으로 내려놔서 스케줄링 되지않게 만드는것을 thread가 wait한다고 말함) 이 필요한 경우에 Critical section 을 안쓰고 srw를 사용
SRWLock이 잘작동하면 critical section을 쓸 필요가 없음
쓰레드간 통신을 위해 이벤트 객체를 사용함
이벤트와 밑에 세개는 차이가 있음
밑에 세개는 쓰레드들이 경쟁적으로 코드 블럭을 진입할때 베리어를 치는 경우
이벤트는 쓰레드간 통신을 위해 사용한다고 보는게 맞음

WaitForSingleObject
WaitForMultipleObjects
SetEvent
쓰레드를 재우다가 signal로 깨움 ⇒ 응답성이 좋진 못함
장점 불필요한 폴링이 없음
20년전에는 뮤텍스 세마포어 크리티컬 섹션 딱 이렇게 설명을 했었고 각설하고 크리티컬 섹션이 가장 빠르다고 얘기 했었음
이벤트보다 응답성이 빠르다고 할 수 있는지 잘 모르겠다
얘도 wait한번 걸리면 커널로 들어감 : 커널 call 호출 ⇒ 커널 쪽에서 스레드를 스케줄링에서 빼버림
얘도 내부적으로 보면 커널 오브젝트를 사용
크리티컬 섹션을 빠르게 쓰고싶으면 확장 CriticalSectionAndSpinCount 함수가 존재
내부적으로 스핀을 돌게 만드는 함수가 있어서 상수를 넣어주면 쓰레드들이 경쟁상태에 들어갔을때 상수만큼 진입을 시도하다 wait 들어가는 기능을 제공




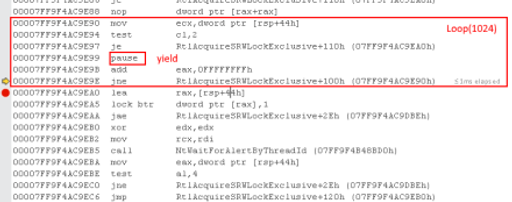
기본은 spinLock 임.
어셈까봤을땐 1024번돌고 나서는 wait로 들어감(Critical section이나 커널 오브젝트와 동일)
mutex와 CriticalSection은 다름
interLock을 가지고 spinlock구현가능
read : shared mode
write : exclusive
shared mode와 exclusive mode가 존재 두 쓰레드가 모두 shared모드로 진입할땐 Lock 안 검, 하나는 읽기고 하나는 쓰기다 하면 Lock 걸림
근데 짜다보면 의외로 둘다 읽는 경우는 잘 없음
interLock은 CAS ; Compare and Store을 얘기
그런 atomic한 명령어를 안쓰고 동기화를 시킬 방법은 아예 없다
어떤 스레드 동기화 api가 있다고 해도 내부적으로 다 들어가보면
x86이라면 접두어에 Lock이 있음 Lock이 붙으면 그순간 버스를 잠금
CompareExchange cmpExchange나 increament decreament 가 붙음
Lock을 쓰게되면 앞뒤로 fence 명령어가 붙을거임 메모리 io를 완료할때까지 대기
SRWLock은 스핀락을 기본으로 사용하고 코드블럭 진입을 못할때 대기상태로 들어갈때 critical setion과의 차이
critical section는 구조체를 보면 recursion count가 존재
한 쓰레드가 자기가 진입한 코드블록으로 들어갈수있다(재진입가능) 이때마다 recursion count 상승
SRW는 재진입 불가능
재진입하려면 데드락 걸림.(내가 보기엔 이런 코드는 코드 설계상 문제)
자기자신이 재진입을 허용하고 있는 코드라면 SRWLock 사용불가

x86에서는 pause란 명령어가 존재 호출시 다른 cpu가 작업을 할 수 있도록 양보
Compiler Intrinsic으론 yield라함
50클럭이내에 명백하게 끝낼 수 있는 작업들에만 사용 ex) 기본 C에서의 링크드리스트 메모리할당없이 정말 붙이고 떼는 정도의 함수 코드
대부분 스핀락을 사용을 한다고 한 많은 이유가 애초에 50클럭이내로 끝낼 수 있을 작업에만 락을 건다 그리고 그런작업이기에 스핀락을 사용
wait상태로 들어가야하는 경우면 SRWLock을 사용하는데 이건 내가 선호하는 설계는 아님
이땐 쓰레드간 통신을 이용해서 서로 양보해가며 사용할 수 있는 환경을 만드는게 좋다고 생각
경쟁적으로 쓰레드가 코드블럭에 진입을 해야한다면 50클럭 이내에 끝낼 수 있고 스핀락 사용
데모
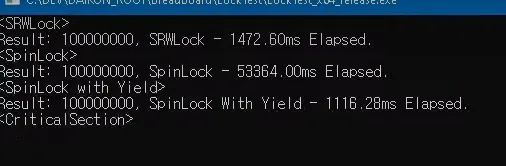
카운트 변수를 1억번 증가시킬건데
쓰레드 하나부터 6쓰레드까지의 걸리는 시간
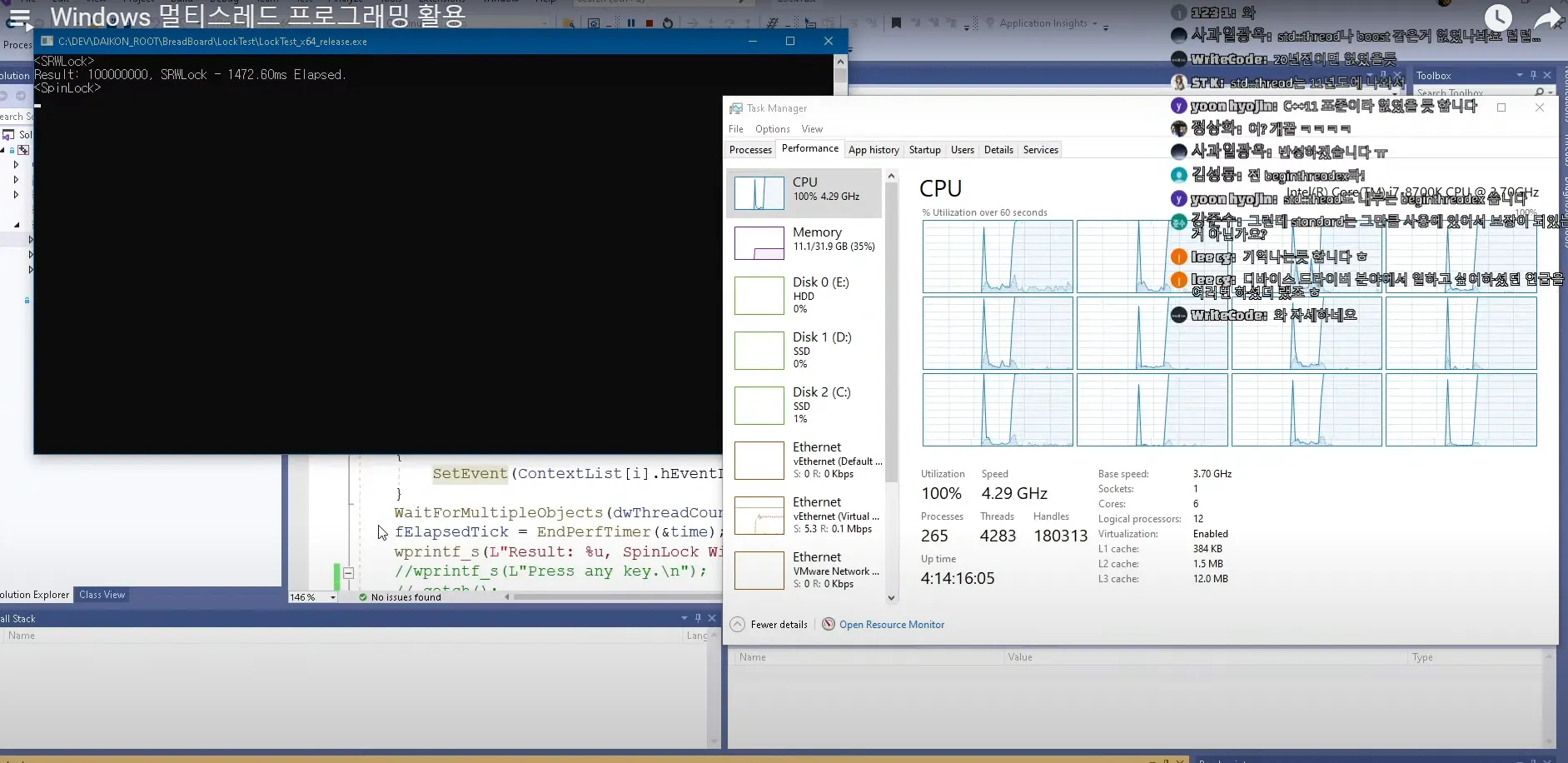
잠깐 오른게 SRWLock
1.4초
뒤에 계속 100찍고있는게 spinlock이 자원을 계속 먹고있는 상황
3.
pause 명령어를 사용하는 스핀락 (수제)
SRWLock을 내부를 보고 베껴만든거 1024번 돌고 yield호출
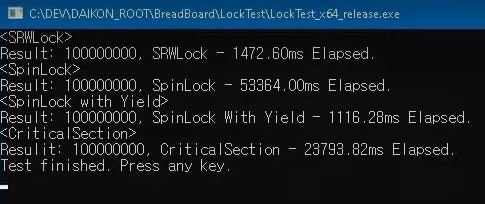
spinlock은 몇 십클럭이내 끝내야하는게 가장 중요
힙에서 메모리 할당, 해제에는 적합하지 않음
SRWLock이 빠른것은 wait전환이 일어나기 전에 대부분 스핀락으로 시도하고 스핀락으로 처리가 되서 빠름 근데 스핀락으로 생길 수 있는 문제는 다른코어의 작업을 방해함 bus를 잠그기때문에 다른 코어를 먹지않음
SRWLock은 스레드레벨이아닌 processor레벨에서 대기함 kenel call로 들어가서 대기
x86 pause 명령어
srw cpu점유
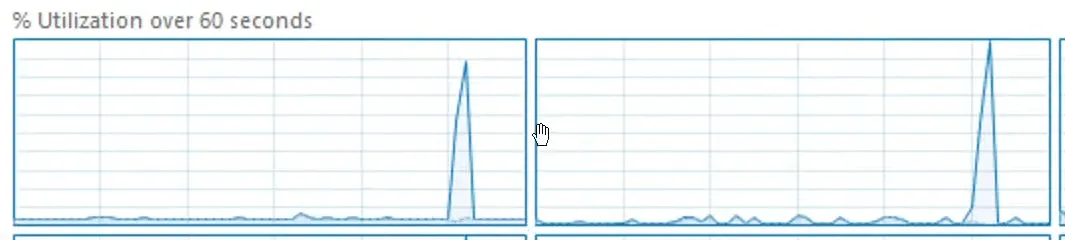
srwlock을 사용해서 1억번 연산 했었을떄 cpu사용량이고
이 밑에 작은 줄이 커널 사용시간이다 ⇒ 커널 사용을 거의 안했다
자체 spinlock도 비슷함
spinlock cpu 점유
커널로 거의 진입을 안함
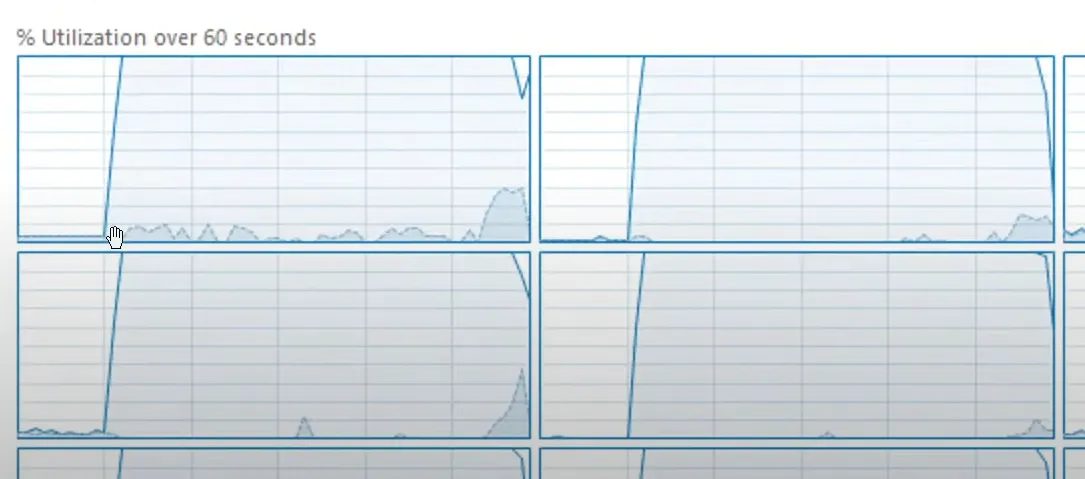
critical section cpu 점유
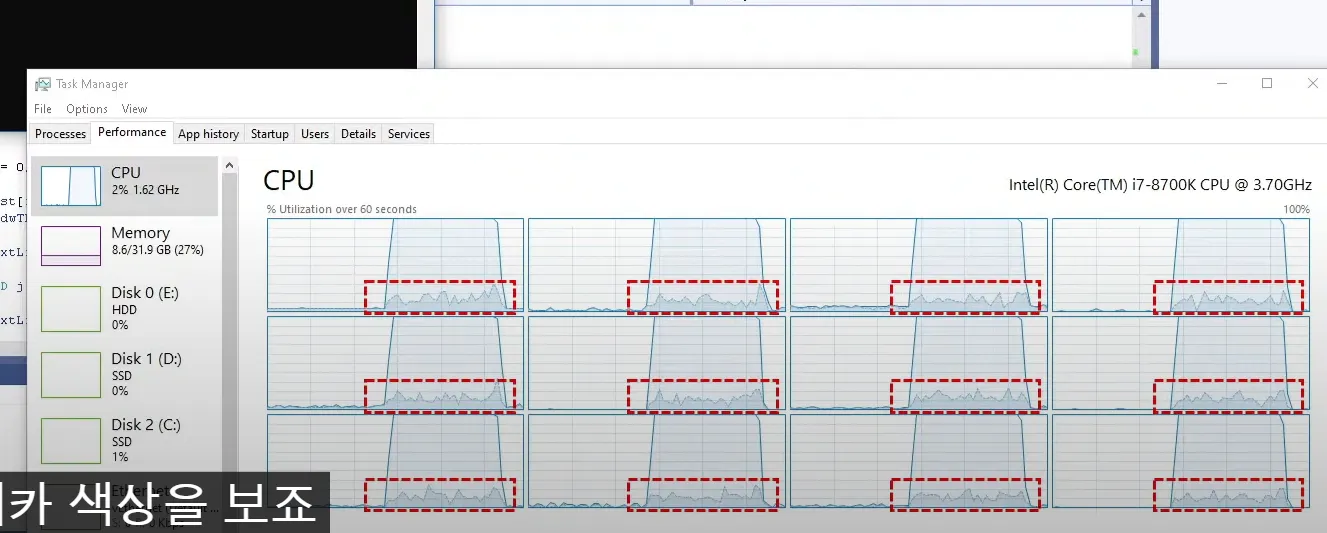
커널 사용량 쭉 올라감
락을 걸때마다 웨이트가 들어감 wait ⇒ 커널콜을해서 ⇒ 스레드를 스케줄링 큐에 내려놓고 ⇒ 재개될때마다 다시 스케줄링 큐에 올림 ⇒ 반복
동기화 팁

아주 짧은 시간 락을 걸거면 스핀락을 쓰면 된다.
스핀락을 쓰면 안되는 조건 코드블럭이 오래걸리면 안됨 가장해선 안되는게 힙메모리에 메모리 할당 해제하는거. 해제에는 시간이 두배이상 걸린다 병합을 해야하기때문에 (수백클럭은 먹음) 거기서 스핀락쓰려면 안쓰느만 못함
메모리 풀 사용도 복잡하겐 사용하면 안됨
고정사이즈 메모리 풀을 사용하면 아주 가벼운 동기화 락으로도 thread safe하게 메모리 풀을 만들 수 있다 (32byte, 128byte 짜리 이런식으로 ) 아주 간단한 링크드 리스트로 만들 수 있다
쓰레드 별로 힙을 분리하거나(windows의 경우 createHeap이라는 함수존재)
최초에 초기화 시킬때 메모리가 충분히 thread 사용할 만큼 할당을 해두고 사용
고정 사이즈 풀 할당 해제는 몇 십 클럭 넘어가면 안됨
데모

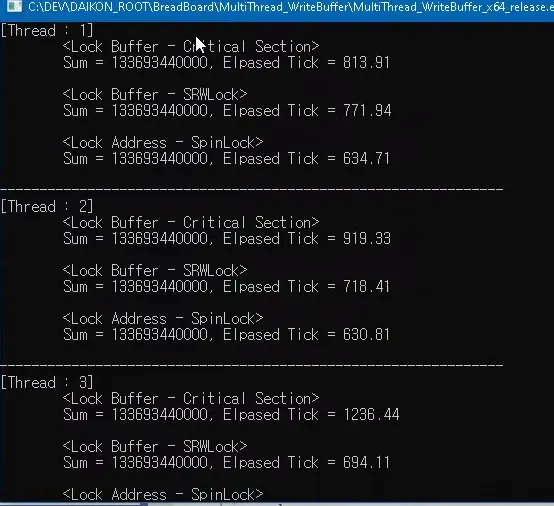
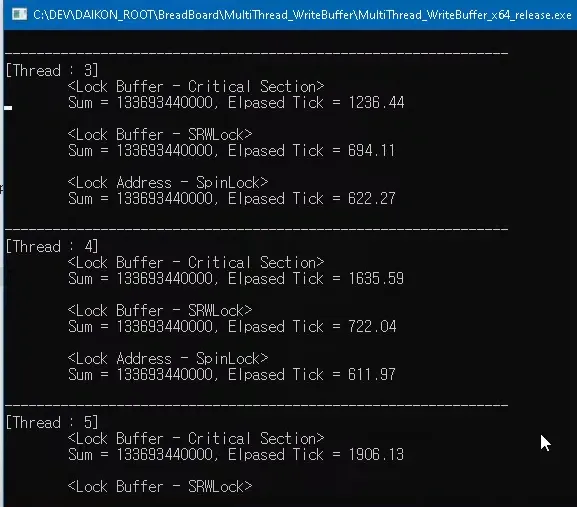
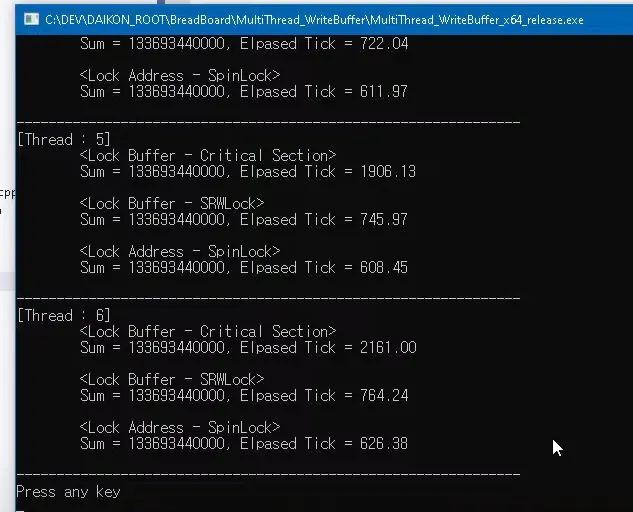
버퍼사이즈는 대략 1GB
코어 개수 만큼 스레드한테 각각 배분을 시킨후 네트워크 이벤트가 발생했다고 가정하고 랜덤하게 사이즈를 계속 얻어서 하나의 버퍼에다 쑤셔넣는것

넣을때 방식
1.
critical section
2.
SRWLOCK
3.
최소한의 spinlock 버퍼전체 락이아닌 버퍼에 써넣을 위치를 얻어오는 부분만 락걸기 버퍼에 써넣는 카피하는 코드 자체는 독립적으로 돌아감
4.
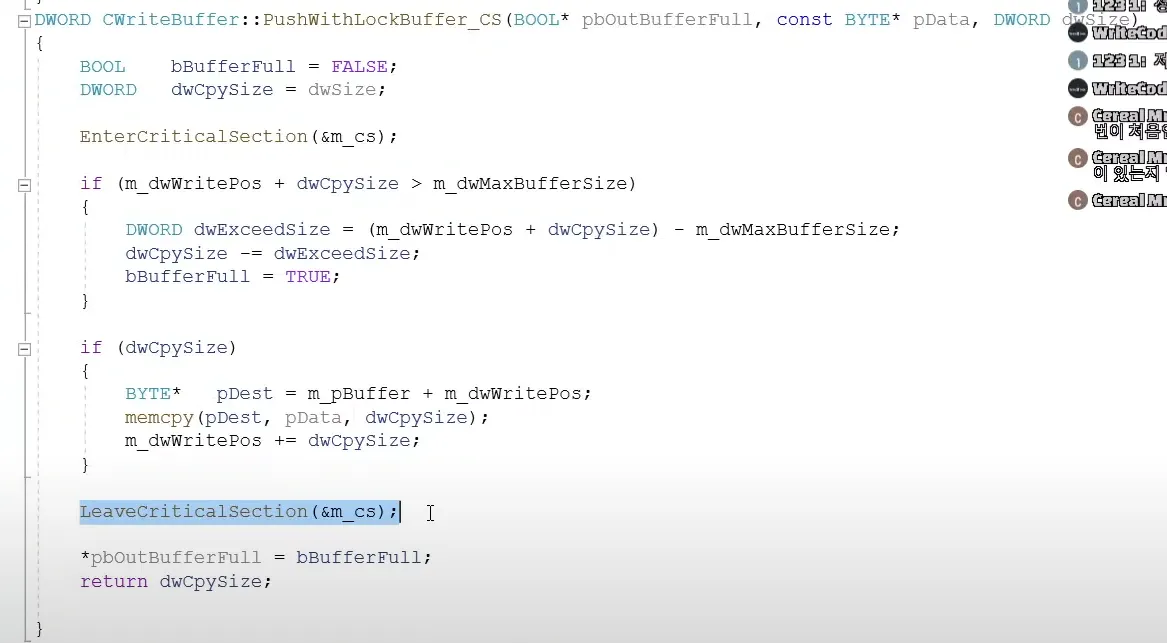
1.
critical section을 사용하는 코드
메모리 카피를 하는동안 진입불가
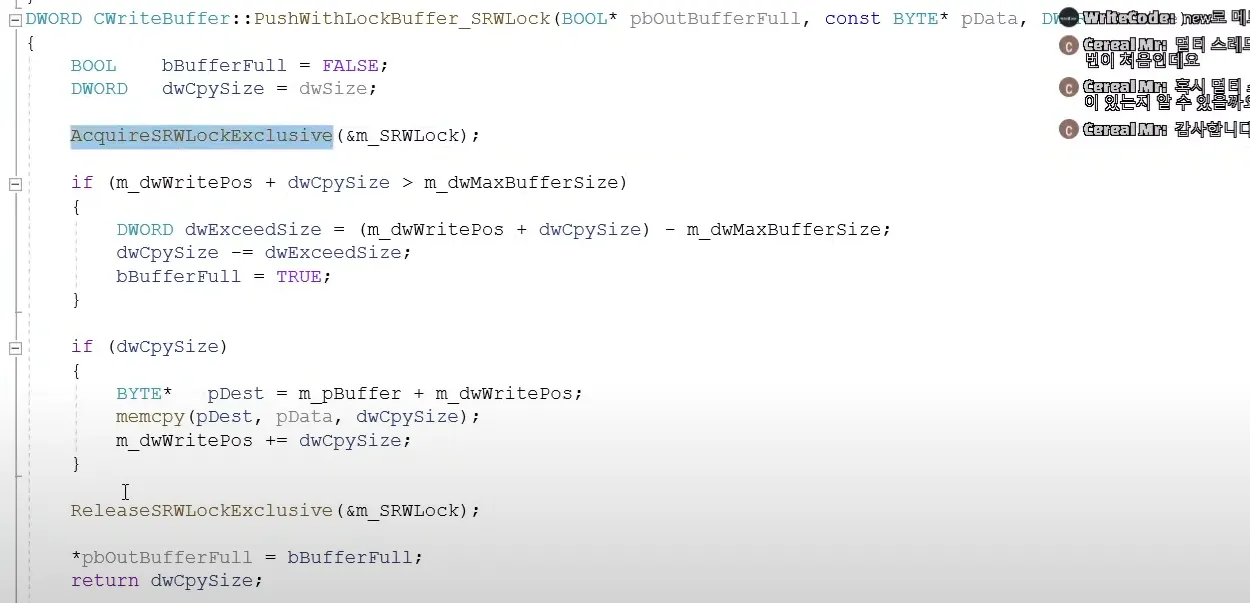
2.
srwlock
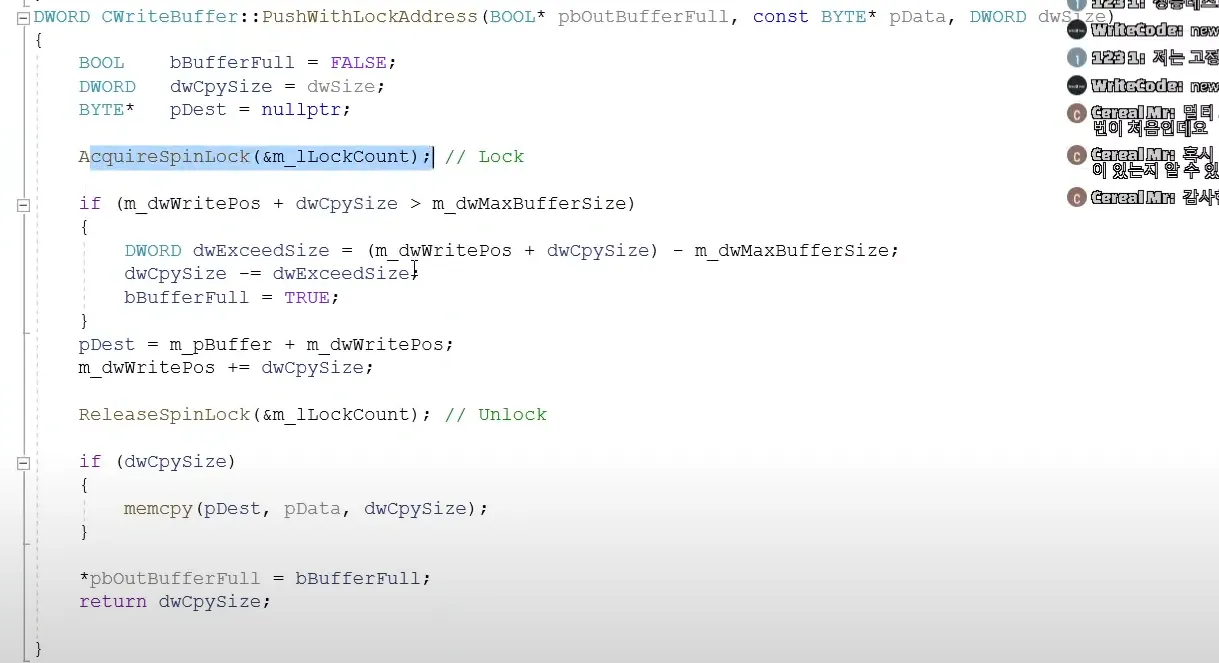
3.
spinlock
위치를 얻어오고 위치계산만. 해당 부분은 몇 십클럭이내에 끝남
copy작업은 따로
발표끝
