본론으로 들어가기 전에 include guard가 뭔지 간단하게 알아보자...!
일단 실행파일이 만들어지는 과정을 살펴보자
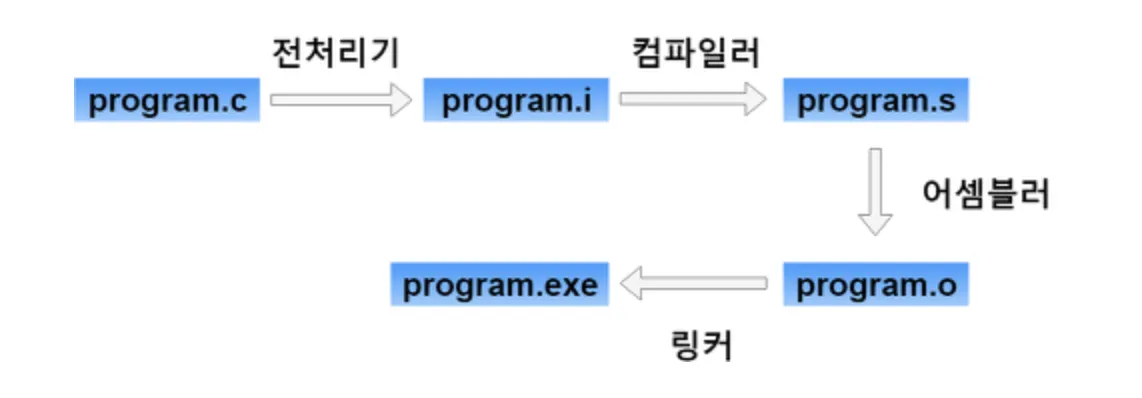
여기서에서 우리는 전처리기가 무엇을 하는지 조금 더 알아볼 필요가 있다.
전처리기는 뭐하는 녀석이니~~?
1.
헤더 파일 삽입
전처리기는 #include 구문을 만나면 해당하는 헤더파일을 찾아서 그 파일의 내용을 순차적으로 삽입합니다.
2.
매크로 치환 및 적용
#define 된 부분은, 심볼 테이블에 저장되고, 심볼 테이블에 들어있는 문자열과 같은 문자열을 만나면 #define 된 내용으로 치환합니다.
이제 드디어 여기서 include guard 의 필요성이 나오게 된다.
#include를 통해서 헤더파일을 선언하다보면 헤더파일이 중복되는 경우가 발생된다.
헤더 파일의 경우, 전처리기에서 파일의 내용을 순차적으로 삽입을 하기 때문에 중복을 하기 되면 메모리 낭비가 일어날 수 있고, 구조체를 중복 정의하게 되면 컴파일시 에러가 뜨는 모습을 확인할 수 있다. (아래 예시 참고)
/*
test.h 파일
*/
//#ifndef TEST_H
//# define TEST_H
struct test{
int a;
int b;
};
//#endif
C
복사
/*
test.c 파일
*/
#include "test.h"
#include "test.h"
int main()
{
return (0);
}
C
복사
위의 두 파일을 컴파일 하게 되면 아래와 같은 오류가 뜨게 된다.
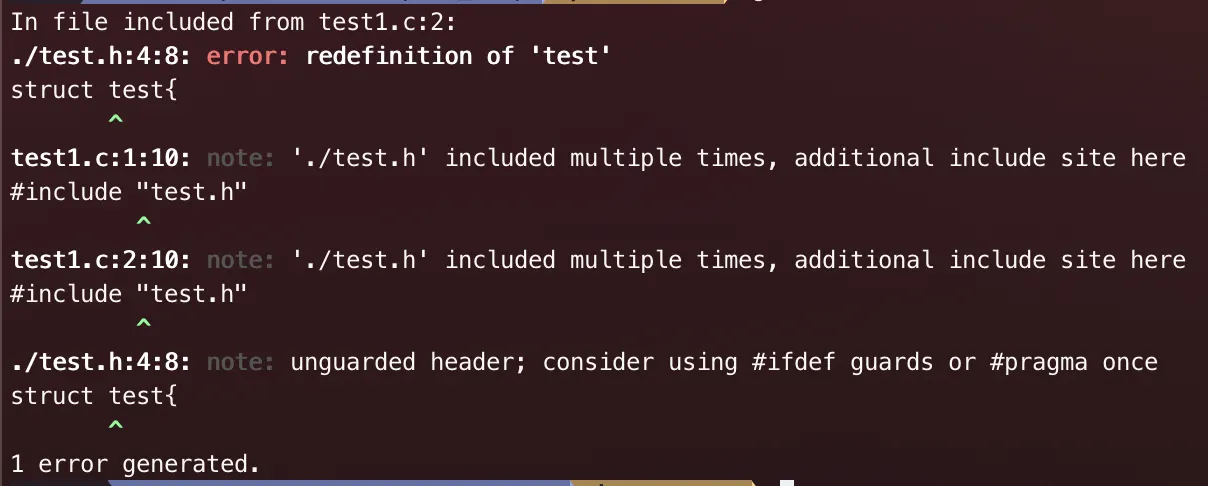
이런 문제를 피하기 위해서는 우리는 include guard가 필요하다.
include guard를 어떤식으로 할건데
•
#ifndef ~ #endif
아까의 예시에서 다음과 같이 사용을 하면 된다.
/*
test.h 파일
*/
#ifndef TEST_H
# define TEST_H
struct test{
int a;
int b;
};
#endif
C
복사
전처리기 과정에서 TEST_H가 정의가 되어있지 않으면 정의를 하게 되는 것이고 정의가 되어 있으면 다시 재정의를 하지 않기 때문에 중복 정의를 피할 수 있다.
•
#programa once
한번만 include 해라 라는 옵션으로 재정의를 피할 수 있다.
•
그렇다면 두 녀석의 차이는 무엇일까?
#ifndef를 사용하면, include시마다 코드를 삽입하면서 코드를 확인하기 때문에 컴파일 속도가 느려진다
그에 반면, #programa once 는 한번만 정의를 하기 때문에 컴파일 속도가 빠르다.
하지만, 컴파일러에 따라 제공을 안 할 수 있기 때문에 호환성 문제가 생기게 된다.
따라서, 호환성을 고려하면 #ifndef가 좋은 선택이 될 것이고 컴파일러가 제공을 한다면 컴파일 속도가 빠른 #programa once 가 또 하나의 선택이 될 수 있다.
include guard naming convention
사실..나만 몰랐던 이야기를 하고 싶어서 서론이 길었다..
위의 예시에서 알 수 있듯이
/*
test.h 파일
*/
#ifndef TEST_H
# define TEST_H
struct test{
int a;
int b;
};
#endif
C
복사
#ifndef 뒤의 이름이 파일이름의 영어부분을 대문자로 바꾸고 .을 _로 바꾸는 모습을 볼 수 있다.
대부분의 예시들도 이런 식이라는 것을 확인할 수 있을 것이다.
그래서....저런식으로 파일명이랑 #ifndef 뒷부분을 맞춰야 전처리기가 되는줄 알았다..ㅎㅎ
근데 이것은 그냥 관행(Naming Convention)일 뿐이라는 것을 알게 되었다.
내가 제일 수치스러웠던건...결국엔 TEST_H 대신 예를 들어 #ifndef a를 써도 컴파일이 잘 된다는 것이었다..
나만 몰랐던 이야기를 조금 더 듣고 싶다면..여기로...
참고