


미로찾기 알고리즘
그래프 탐색 알고리즘에는 대표적으로 깊이 우선 탐색과 너비우선 탐색이 있습니다.
깊이 우선 탐색(DFS)
너비 우선 탐색(BFS)
비교
1. DFS
깊이 우선 탐색(Depth First Search)으로 해당 노드의 자식 노드를 먼저 탐색하는 알고리즘입니다.
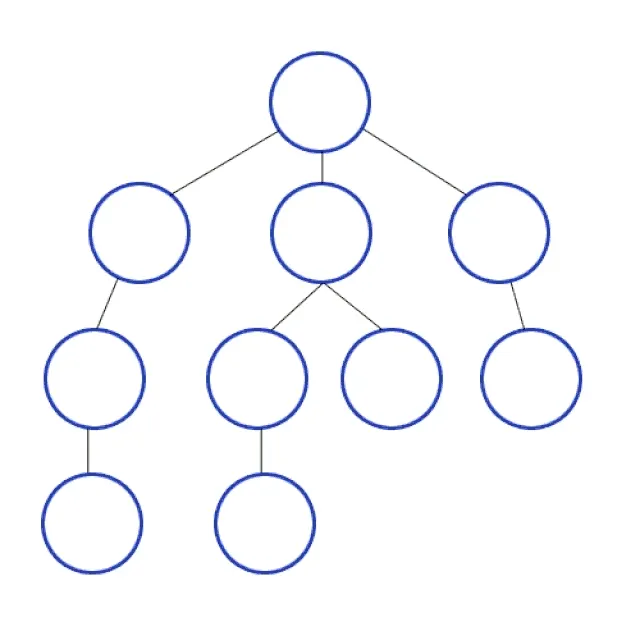
wikimedia commons
1) 스택 사용
DFS를 스택을 사용하게되면 재귀 없이 구현할 수 있게 됩니다. 방문이 필요한 노드를 스택에 저장하고 스택 구조를 활용하여 그 중 가장 마지막 데이터를 추출합니다.
2) 코드
def dfs(graph, start_node):
visited = []
stack = [start_node]
while stack:
node = stack.pop()
if node not in visited:
visited.append(node)
stack.extend(graph[node])
return visited
Python
복사
graph = {
1: [2, 5, 9],
2: [3],
3: [4],
4: [],
5: [6, 8],
6: [7],
7: [],
8: [],
9: [10],
10: []
}
print(dfs(graph, 1))
# output : [1, 9, 10, 5, 8, 6, 7, 2, 3, 4]
Python
복사
코드가 재귀적이기 때문에 재귀함수로도 구현할 수 있습니다.
def dfs_recursive(graph, start, visited = []):
visited.append(start)
for n in graph[start]:
if n not in visited:
dfs_recursive(graph, n, visited)
return visited
print(dfs_recursive(graph, 1))
# output : [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
Python
복사
2. BFS
너비 우선 탐색(Breadth First Search)으로 해당 노드와 같은 레벨의 노드를 먼저 탐색하는 알고리즘입니다.
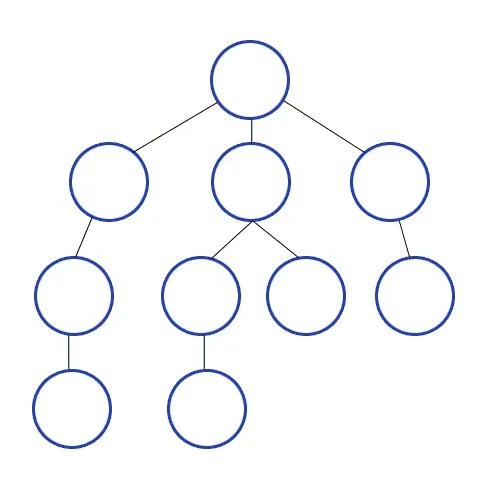
wikimedia commons
1) 큐 사용
파이썬에서 큐를 list 타입을 사용하게되면 pop을 할때 시간복잡도가 O(N)으로 비효율적이게됩니다. 그래서 collections 라이브러리의 deque를 사용해서 시간을 절약할 합니다.
아래 링크에서 자세한 내용을 확인 할 수 있습니다.
2) 코드
from collections import deque
def bfs(graph, start_node):
visited = []
que = deque()
que.append(start_node)
while que:
node = que.popleft()
if node not in visited:
visited.append(node)
que.extend(graph[node])
return visited
Python
복사
graph = {
1: [2, 3, 4],
2: [5],
3: [6, 7],
4: [8],
5: [9],
6: [10],
7: [],
8: [],
9: [],
10: []
}
print(bfs(graph, 1))
# output : [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
Python
복사
3. DFS와 BFS 비교
•
DFS
◦
현재 정점에서 갈 수 있는 자식노드에 들어가면서 탐색을하고 스택 또는 재귀함수로 구현을 합니다.
◦
경로마다 특징을 저장해둬야 하는 경우 유리합니다.
◦
검색 대상 그래프가 크다면 DFS 사용하는 것을 고려해 볼 수 있습니다.
•
BFS
◦
현재 정점에서 연결된 같은 레벨의 노드부터 탐색하며 큐를 이용해서 구현합니다.
◦
최단거리를 구해야하는 경우 유리합니다.
◦
검색 대상의 규모가 크지 않을 때 BFS 사용하는 것을 고려해 볼 수 있습니다.
DFS와 BFS의 시간 복잡도는 모든 노드를 검색한다는 점에서 동일합니다.
