

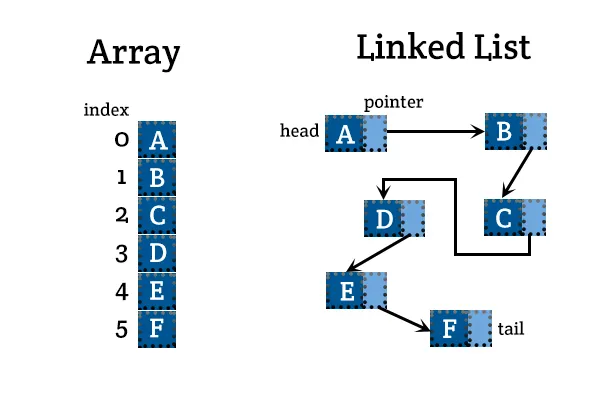
배열 vs 연결리스트
가장 심플하고 어려운 질문.
사람마다 전부 다 다른 대답을 한다.
(그러므로 부족하거나 보충할만한 내용이 있다면 댓글을 달아주세요  )
)
)어느쪽이 이기는가?
배열과 리스트중에 무조건 좋은 쪽이 존재하진 않는다.
프로그래밍에서 많은 선택지들은 트레이드-오프 관계를 띈다.
성능 - 안정성 같은 관계가 하나의 예시이다.
하나를 고르면 하나는 적당히 포기해야 한다.
배열 vs 리스트도 비슷하다.
배열의 장점, 리스트의 장점 중 어느것을 고르고 포기할것인지 선택해야 한다.
어떤 상황에서 어떠한 데이터를 다루냐에 따라 유리한 선택지가 달라지므로
유리한 선택지를 결정하기 위해선 각 기능들의 차이와 장단점을 이해하고 있어야 한다.
어느쪽이 이기냐 라는 질문에서
”배열과 연결리스트의 장단점과 차이” 라는 질문으로 바꾸고
차이점을 나열해보자.
1. 시간복잡도
가장 먼저 접근할 수 있는 차이는 시간복잡도일 것이다.
랜덤 엑세스
- 배열 O(1), 리스트 O(n)
중간 삽입
- 배열 O(n), 리스트 O(1)
후방 삽입
- 배열 O(1), 리스트 O(1)
액세스가 많은 상황의 경우 배열을,
삽입/제거가 많은 경우는 리스트를 선택해야 한다.
2. 메모리 지역성
시간복잡도가 같더라도 여러 요인에 따라 성능이 몇 배씩 차이가 난다.
예를 들어 배열과 리스트의 원소 삽입/삭제 에서
배열은 O(n), 리스트는 O(1) 의 시간복잡도를 가지지만
원소의 개수가 15개 정도 이하인 경우에는 배열이 훨씬 빠르다.
2-1. 메모리 용량
배열은 추가적인 메타데이터를 거의 필요로 하지 않는다,
하지만 리스트는 각 노드마다 next같은 포인터가 필요하다.
즉 리스트는 최대 2~3배의 더 많은 메모리를 소비해야 한다.
2-2. 메모리 연속성
배열의 메모리 배치는 연속적이다.
(바로 다음 주소에 다음 값이 존재함)
하지만 리스트의 메모리 배치는 비연속적이다.
(다음 값이 어느 위치에 존재할지 알 수 없음)
메모리 배치가 연속적이고, 비연속적이면 뭐가 다를까?
2-2-1. 캐시 라인
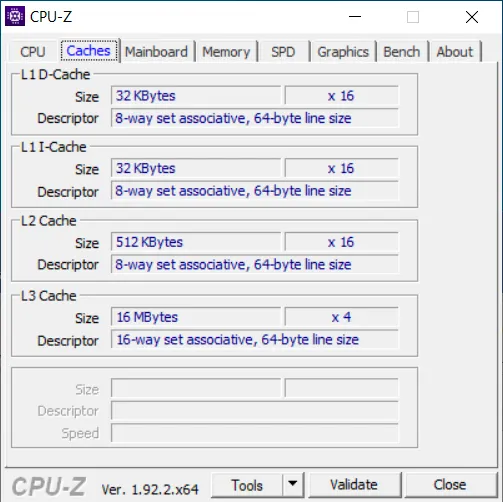
위는 cpu-z 라는 cpu의 스펙을 보는 프로그램이다.
Cache의 descript를 보면 “64-byte line size” 라는 글귀를 볼 수 있다.
이것이 캐시 라인 이라고 부르는 것인데,
저 cpu의 캐시는 데이터를 쓰고 읽어올 때 1바이트, 4바이트씩 읽고 쓰는것이 아닌
무조건 64바이트씩 쓰고 읽는다는 것이다.
거의 대부분 개인용 cpu가 저렇다.
다시 메모리 연속성으로 돌아와서,
메모리가 연속적으로 배치되어 있다면, 무엇이 좋을까?
만약 내가 4바이트 int로 된 배열을 사용한다고 생각해보자.
arr[0] 칸을 읽는다.
cpu는 한 칸인 4바이트를 캐시에서 가져와 읽을 것이다.
하지만 캐시는 4바이트만 읽는것이 아니다.
캐시라인 범위인 64바이트, 즉 arr[0] ~ arr[15] 범위를 모조리 한 번에 읽는다.
배열은 한 번 읽으면 16칸을 한 번에 읽고,
리스트는 비-연속적이므로 한 번 읽으면 훨씬 적은 칸을 읽는다.
배열과 리스트의 시간복잡도가 같다고 하더라도
메모리가 연속적인 배열이 훨씬 빠르게 되는 것이다.
2-2-2. 메모리 접근 패턴
비연속적인 메모리는 접근 패턴이 일정하지 않다.
연속적인 배열은 첫 칸부터 마지막 칸 까지 순회한다면 접근 패턴이 일정하다.
현대 Hardware Cache Prefetcher는 메모리 접근 패턴이 일정하다면
다음 접근할 메모리를 예측해 미리 가져올 수 있다.
3. 메모리 할당
연결리스트는 하나의 문제가 더 있다.
노드 하나 당 malloc과 free를 수행해야 하는 것이다.
3-1. malloc/free
동적할당은 매우매우매우 느리다.
내부 로직 자체가 느리고, syscall로 들어가야해서 엄청 느리다.
배열은 한 번만 malloc/free 하면 되는데,
리스트는 매 노드마다 malloc/free 해야하니 더 느려진다.
3-1-1. 메모리 단편화
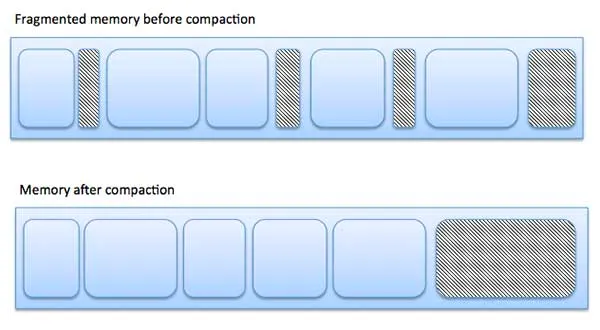
malloc/free를 반복하면 발생하는 문제가 있다.
바로 메모리 단편화 현상이다.
리스트의 노드같이 작은 사이즈를 반복해서 동적할당을 하게 되면,
메모리에 구멍이 숭숭숭 뚫리며 메모리 단편화가 심해진다.
컴퓨터에 남은 메모리가 충분한데
malloc이 실패한다면, 메모리 단편화를 의심해볼 수 있다.
(위 그림처럼 메모리를 압축하는 방법도 있지만, 런타임에서 메모리 압축은 매우 힘들다.
C#의 경우 pinned memory, non-pinned memory를 분리하는 방식으로 해결했지만…
우리는 VM이 없으므로 거의 불가)
3-2. 동적할당 문제의 해결 방법
메모리 풀을 직접 만들어 사용하거나,
[https://github.com/Ria9993/PlayGround/blob/main/Static Memory Pool/Variable Static Memory Pool/main.c]
LFH(Low Fragmentation Heap)등을 사용하여 해결할 수 있다.
메모리 풀을 직접 만들면 경험상 최소 3배에서 100배까지 속도가 빨라지고,
노드는 어차피 고정사이즈이므로 메모리 단편화도 발생하지 않도록 해결할 수 있다.
(windows CRT의 경우 malloc의 크기가 작은경우 자동으로 LFH를 사용한다. (기억상으로 16kb 이하?))
4. 포인터 연산 실행 속도
이외에도 코드 실행 속도에서 포인터 연산으로 인한 간접참조로 리스트가 실행속도에서 뒤떨어진다.
또 다음 노드로 jmp 할 때,
cpu가 다음 노드가 어디일지 예측하는데
이 예측도에 따라서도 성능이 달라지므로 예측도도 고려해야 한다
(Indirect Branch Prediction)
+ 연결리스트 내의 코드 비교
배열과 리스트를 구분하는 것 만이 아니라
리스트 내부에서도 여러 선택지가 생길 수 있다.
다음은 리스트에서 특정 노드를 제거하는 코드이다.
코드 길이만 보지 말고 여러 요인에 따라 어떤 코드가 빠를지 생각해보자.
void remove_cs101_1(list *l, list_item *target)
{
list_item *cur = l->head, *prev = NULL;
while (cur != target) {
prev = cur;
cur = cur->next;
}
if (prev)
prev->next = cur->next;
else
l->head = cur->next;
}
C++
복사
void remove_cs101_2(list *l, list_item *target)
{
list_item **p = &l->head;
while (*p != target)
p = &(*p)->next;
*p = target->next;
}
C++
복사
정리.
정말 많은 요인에 따라 어떤 선택지가 유리한지가 달라진다.
자신이 개발하는것이 임베디드인지, 모바일인지, PC인지.
어떤 OS와 cpu와 메모리를 사용하는지
어떠한 상황에서 어떤 데이터를 다루는지
충분히 고려한 뒤 결정하도록 하자.
