

size_t 의 정체는 무엇인가?
배경(관찰)
•
Libft에서 함수(calloc, memcpy 따위)를 구현하는 과정에서 의당 함수 매뉴얼을 보게 되는데, 이때 매개변수의 자료형으로 size_t를 심심치 않게 만나게 된다. 그런데 size_t가 뭔지 모르겠다.
•
Libft 평가 과정에서 size_t가 무엇인지, 왜 쓰는지 질문하기도 한다.
(이 때, 그냥 매뉴얼에 size_t로 써있어서 똑같이 썼다고 대답하면 틀림 처리될 공산도 있다. 왜냐하면 이것은 int, char, float, double 과 같은 자료형이 무엇인지 모르고 코드를 작성했다고 여겨지거나, 심한 경우 cheating 으로 간주될 수 있기 때문이다.)
•
size_t가 무엇이고 왜 쓰는지에 대한 충분하고 명확한 설명을 구하거나 찾기 어려웠다.
탐구_1
•
GNU 매뉴얼
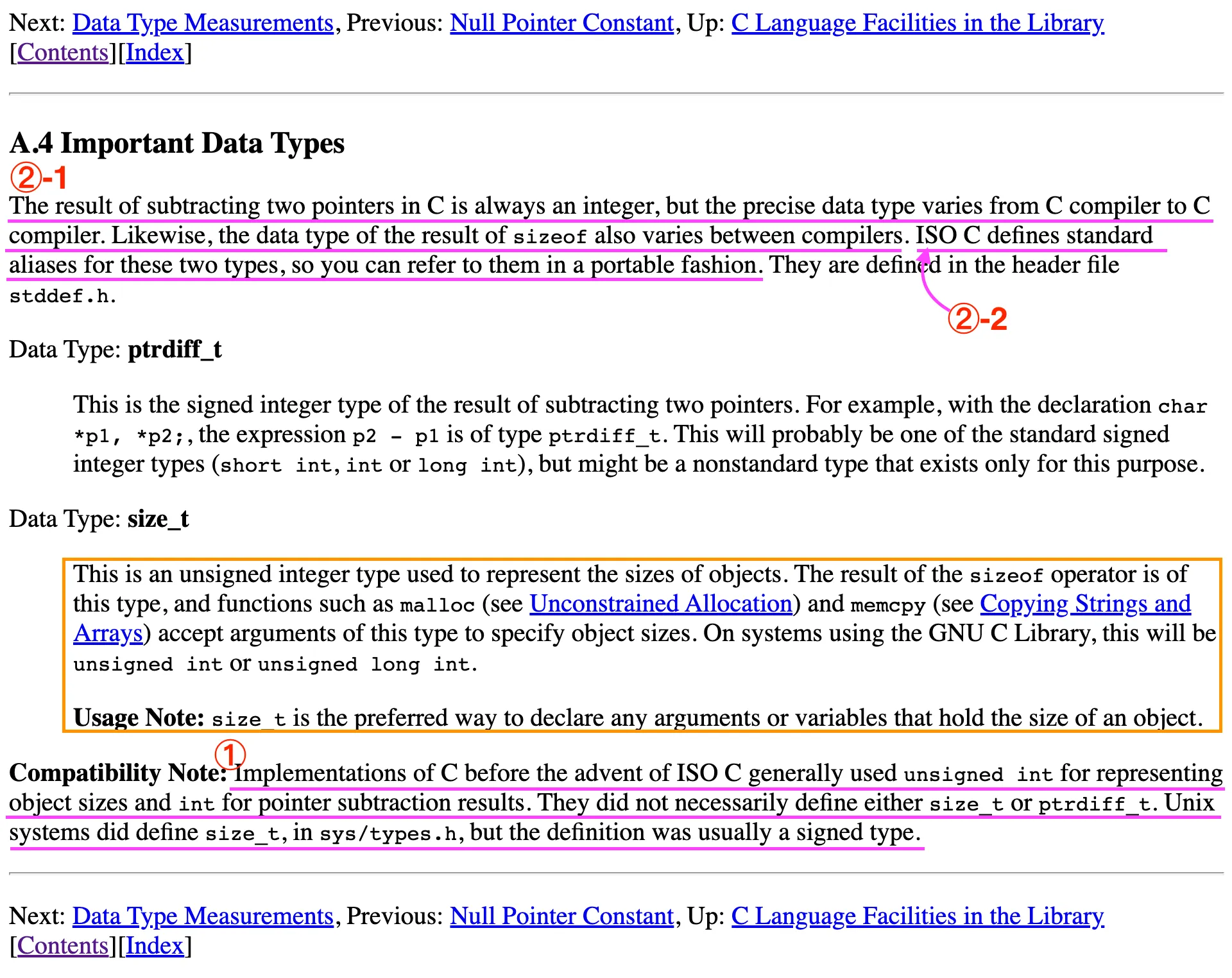
[스크린샷 출처] The GNU C Library Reference Manual, for version 2.36.
위 내용(GNU 매뉴얼)을 보다 쉽게 이해하기 위해 아래와 같이 가공하였다. (*①→②→③ 순으로 한글 가공)
① 옛날에는
ISO C(C국제표준)이 생기기 전(1989~90년 이전)에는 객체의 크기를 표현하는 자료형으로 unsigned int를 사용하고, 포인터의 연산 결과를 표현하는 자료형으로 int를 사용했다.
당시 사람들은 size_t 나 ptrdiff_t 를 정의할 필요성을 느끼지 못했다. (UNIX 시스템에서 size_t를 정의하기는 했었지만 부호가 있는 자료형이었다.)
②-1 이렇게 쓰다 보니 이식성 문제를 마주했다.
C에서 두 포인터의 차의 결과는 항상 integer(정수)이지만, 데이터 타입(자료형)은 C컴파일러마다 제각각이다. 따라서 자료형을 연산자 sizeof로 연산한 결과가 컴파일러마다 다르다. (이식성 문제가 생겼다.)
②-2 (이러한 이식성 문제를 해결하기 위해) ISO는 size_t라는 alias(별칭)를 정의했다.
의문

Q) 도대체 이식성 문제가 뭐지?
A) 아래 탐구_2와 탐구_3을 종합하면 이해할 수 있겠다.
탐구_2
•
형정의(typedef)와 호환성(이식성)
*출처 : c programming A modern approach (저자 : K. N King)
형정의는 호환성이 중요한 프로그램을 작성할 때 매우 중요하게 작용한다. 프로그램을 한 컴퓨터에서 다른 컴퓨터로 옮길 때 발생하는 가장 큰 문제중 하나는 컴퓨터별로 자료의 범위가 다르다는 것이다.
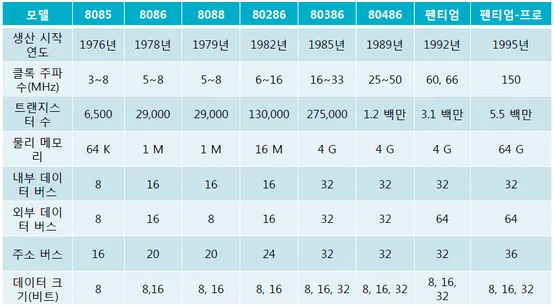
[그림] 인텔 CPU 모델별 관련 정보
*연식별 레지스터의 종류 즉, 정보 처리 방식(데이터 처리 단위)에 따라 8비트, 16비트, 32비트로 다름을 확인할 수 있다. (표의 맨 아래 항목)
int i;
i = 100000;
C
복사
위의 변수 i 정의는 32비트인 컴퓨터에서는 아무 문제 없이 돌아가지만, 정수가 16비트인 컴퓨터에서는 문제가 생긴다.
예를 들어 0에서 50,000까지의 정수를 저장해야하는 변수를 필요로 하는 프로그램을 작성한다고 가정하자. 우리는 물론 long변수(최소 2,147,483,647까지의 값을 보장할 수 있기 때문이다)를 사용할 수 있을 것이다. 하지만 우리는 int를 사용하려고 한다. 아무래도 long을 갖는 연산보다는 int로 구성된 연산이 더 빠르며, 저장공간도 덜 차지하지 않겠는가.
예를 들어 0에서 50,000까지의 정수를 저장해야하는 변수를 필요로 하는 프로그램을 작성한다고 가정하자. 우리는 물론 long변수(최소 2,147,483,647까지의 값을 보장할 수 있기 때문이다)를 사용할 수 있을 것이다. 하지만 우리는 int를 사용하려고 한다. 아무래도 long을 갖는 연산보다는 int로 구성된 연산이 더 빠르며, 저장공간도 덜 차지하지 않겠는가.표1) [16비트 기계의 정수형] *short int와 int가 사실상 같은 범위를 같는 것에 주목하라.
정수형 | 최소값 | 최대값 |
short int | -32,768 | 32,767 |
unsigned short int | 0 | 65,535 |
int | -32,768 | 32,767 |
unsigned int | 0 | 65,535 |
long int | -2,147,483,648 | 2,147,483,647 |
unsigned long int | 0 | 4,294,967,295 |
표2) [32비트 기계의 정수형] *int와 long int가 사실상 같은 범위를 갖는 것에 주목하라.
정수형 | 최소값 | 최대값 |
short int | -32,768 | 32,767 |
unsigned short int | 0 | 65,535 |
int | -2,147,483,648 | 2,147,483,647 |
unsigned int | 0 | 4,294,967,295 |
long int | -2,147,483,648 | 2,147,483,647 |
unsigned long int | 0 | 4,294,967,295 |
표3) [64비트 기계의 정수형] *최근엔 64비트 CPU가 좀 더 대중적인 CPU가 되었다. 표3)은 64비트 환경(특히 UNIX 기반의 환경)에서의 일반적인 정수형의 값의 범위이다.
정수형 | 최소값 | 최대값 |
short int | -32,768 | 32,767 |
unsigned short int | 0 | 65,535 |
int | -2,147,483,648 | 2,147,483,647 |
unsigned int | 0 | 4,294,967,295 |
long int | -9,223,372,036,854,775,808 | 9,223,372,036,854,775,807 |
unsigned long int | 0 | 18,446,744,073,709,551,615 |
다시 한 번 강조하지만 표 1), 2), 3)에 명시된 범위는 모든 컴파일러나 컴퓨터에서 반드시 적용되는 범위가 아니다. 해당 환경에서의 최대값과 최소값을 확인하려면 표준 라이브러리 중 하나인 <limits.h> 헤더 파일을 이용하면 된다. 이 헤더 파일은 각 정수값의 최소/최대값을 나타내는 매크로를 정의해놓았다.
[호환성 팁] 호환성을 중시한다면, typedef를 사용해 정수형들을 다른 이름으로 정의해보자
C 라이브러리 자체도 typedef를 사용하여 여러 형 이름을 만드는데, 이는 각 C 구현부마다 다를 수 있다. 이러한 형들은 보통 t로 이름이 끝나는데, 대표적으로 ptrdiff_t , size_t, wchar_t 등이 있다.
typedef long int ptrdiff_t;
typedef unsigned long int size_t;
typedef int wchar_t;
C
복사
[C99] C99에서는 <stdint.h> 헤더에서 특정 비트를 갖는 정수형들을 typedef 를 이용해 정의해놓았다. 예를 들어 int32_t는 정확하게 32비트인 유부호정수형이다. 이러한 형들을 사용하면 프로그램의 호환성을 훨씬 높여줄 것이다.
탐구_3
•
memcpy의 구조의 대략은 다음과 같다.
memcpy(void *s1, void *s2, n);
C
복사
표준 C에서 자료형 중 long(부호가 있든 없든)은 적어도 32비트를 차지해야 한다. 따라서 표준 C를 지원하는 IP16 플랫폼은 실제로 IP16L32 플랫폼이어야 한다. 이러한 플랫폼들은 일반적으로 각각의 32비트 길이를 16비트 단어 쌍으로 구현한다. 이 경우 32비트 길이를 이동하려면 일반적으로 두 개의 기계 명령어가 필요한데, 하나는 각각의 16비트 청크를 이동하는 명령어다. 실제로 이러한 플랫폼의 거의 모든 32비트 작업에는 그 이상은 아니더라도 적어도 두 개의 명령어가 필요하다.
위의 작동 원리 때문에 memcpy의 세 번째 매개 변수를 이식성을 위해 unsigned long으로 선언하는 것은 일부 플랫폼에서 성능 저하를 초래한다. 이것은 우리가 원치 않는 것이다. size_t를 사용하면 이러한 부담을 피할 수 있다.
Type size_t is a s typedef that's an alias for some unsigned integer type, typically unsigned int or unsigned long , but possibly even unsigned long long . Each Standard C implementation is supposed to choose the unsigned integer that's big enough–but no bigger than needed–to represent the size of the largest possible object on the target platform.
(type size_t는 부호 없는 정수형의 별칭으로, 일반적으로 부호 없는 int 또는 부호 없는 long이지만, 부호 없는 long long일 수도 있다. 각 표준 C 구현체는 대상 플랫폼에서 가능한 가장 큰 객체의 크기를 나타내기에 충분히 크지만 필요 이상으로 크지 않은 부호 없는 정수를 선택하도록 되어 있다.)
결론
•
size_t가 없던 시절에는 다음과 같은 이식성 문제가 있었다.
◦
문제① cpu(레지스터) 종류에 따라 정수형의 표현 범위가 달라져 프로그램이 오작동하는 문제가 발생했다.
◦
문제② 문제①을 해결하기 위해 무조건 자료형을 크게 unsigned long int나 unsigned long long int로 선언할 경우 연산 효율 저하, 필요를 훨씬 초과하는 메모리 과다 사용 문제가 발생했다.
•
이러한 이식성(호환성)문제를 해결하기 위해 ISO C(표준 C)는 size_t 라는 표준 alias(별칭)를 정의했다.
•
이로써 각 표준 C 구현체(컴파일러 및 라이브러리 따위)는 size_t를 통해 대상 플랫폼에서 가능한 가장 큰 객체의 크기를 나타내기에 충분히 크지만 필요 이상으로 크지 않은 부호 없는 정수를 선택하도록 해준다.
-끝-
