


아 길고 긴 강화학습 글을 정리했더니 기분이 좋다. 이번 글은 수식은 그냥 다 빼고 내가 그냥 개념 더 정리하느라고 쓰는 글이다.
이제 강화학습 관련 여러 용어들에 대해 알게 되었으니 저런 것들을 기본으로 문제를 풀어야 한다.
여러 강화학습 알고리즘들을 카테고리화 해서 딱딱 구별하는 것은 무지무지 힘들고 구지 우겨넣어야 하나 싶기도 하지만 나의 이해를 위해서 분류를 해보자.
우선 강화학습 알고리즘들은 Model-free , Model-based 로 나눌 수 있다. 여기서 Model 이란 전 글의 MDP 에서 Reward function 과 State transition matrix 이다. 결국 이 두개를 알고 시작하면 model-based 이고 모르고 시작하면 model-free 인 것이다.
먼저 Model-based 문제를 보자.
이 Model-based 문제는 Dynamic Programming 이라는 방법을 통해 푸는 것이다. 물론 앞에서 보았던 무수한 개념과 식들을 동원해서 풀어간다. Dynamic Programming 으로 문제 푸는 것을 쓸려면 또 한 세월이기에 이 글은 그냥 좀 이놈의 강화학습의 구조에 대한 개념만 잡는 거니까 넘어가자! 히
다음은 Model-free 문제이다.
Model-free 문제는,
1. Value-based 와 Policy based 로 나눌 수 있다.
Value-based 는 Q 라는 action-value function 에 초점을 맞추어서 Q function 을 구하고 그것을 토대로 policy 를 구하는 방식이다. 여기서는 그 유명한 Montel-Carlo learning 방법과 Temporal Difference Learning 방법이 있다. Monte-Carlo 방식은 episode 마다 update 하는 방법이고 temporal difference 방식은 step 마다 update 하는 방식이다.
사실 value-based 와 policy based 특성을 둘 다 가지는 actor-critic 방식도 있다. 이래서 경계가 애매해지고 구분짓기 참 애매해 지는 것이다.
2. On-policy 와 Off-policy 로 나눌 수 있다.
이거에 대해서 좀 더 공부하고 써야 할 거 같다. 간단하게 말해서 외부 policy 를 쓰냐 안쓰냐 인데 좀 더 구체적으로 업데이트 하겠다.
이런 분류를 보아서 구우우지 구분을 해보자면
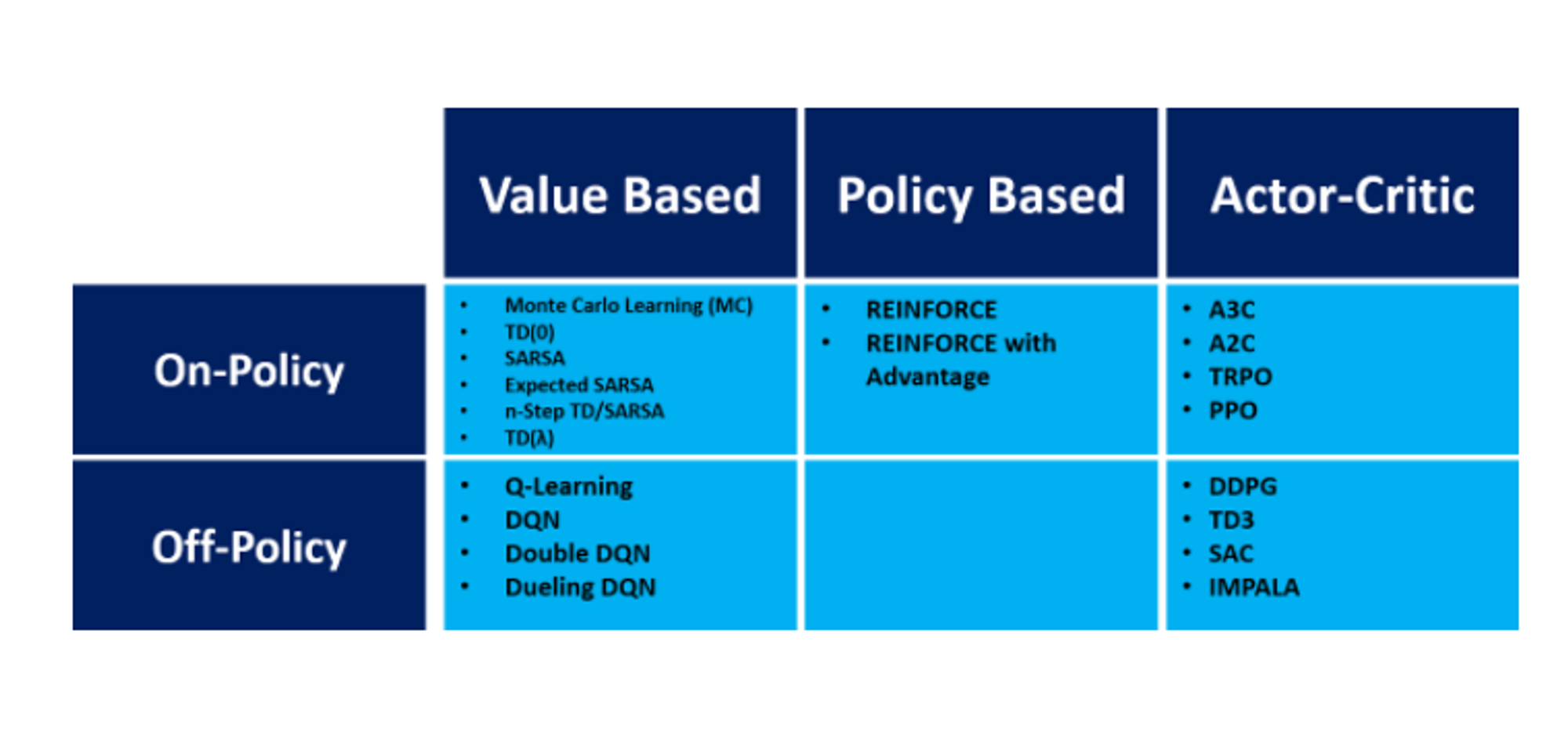
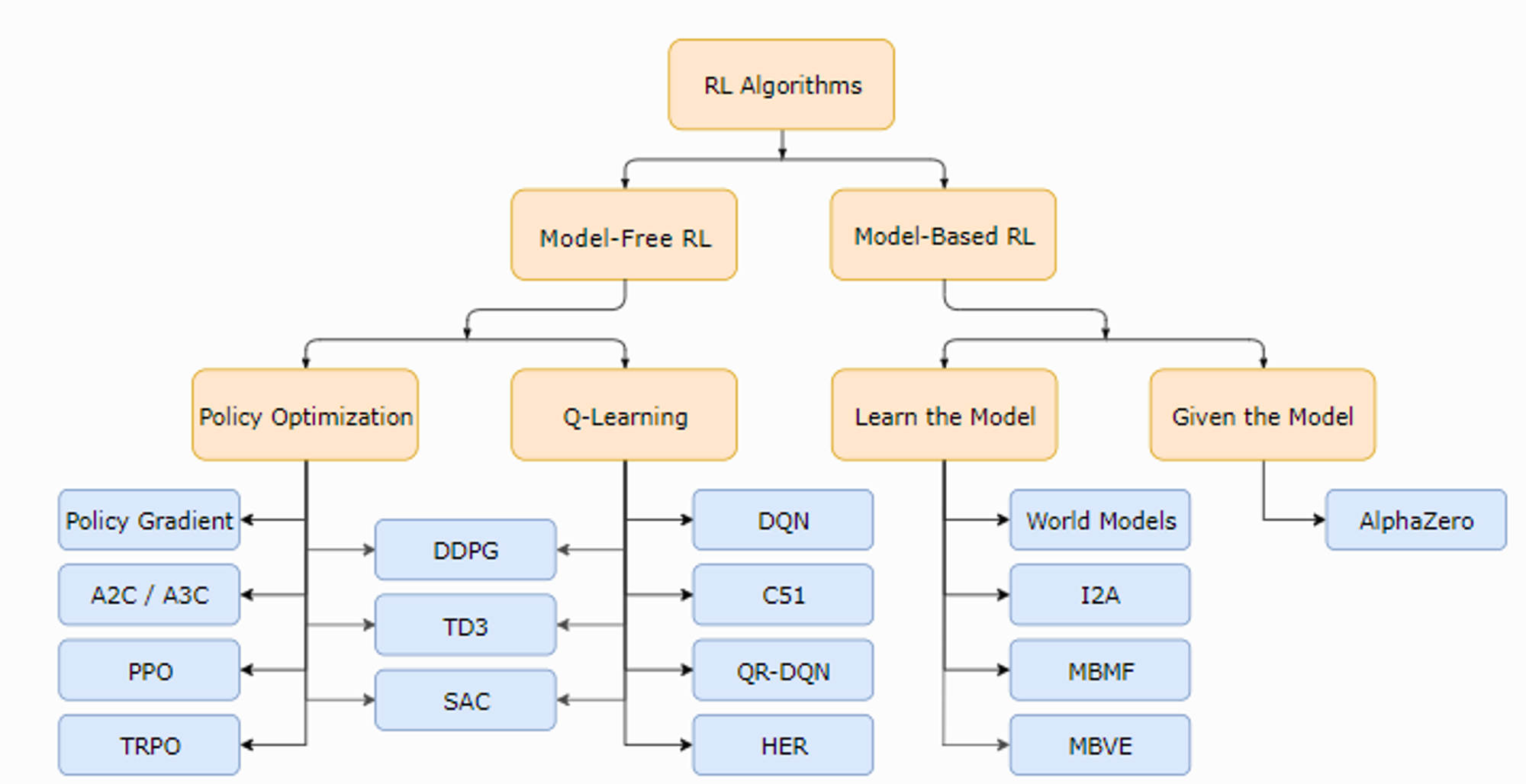
두 표가 애초에 조금씩 분류를 다르게 해놓는다. 약간씩 애매해서 겹치는 부분이 있어서 그러니 이렇게 참고만 하고
앞으로 여러 알고리즘들을 공부해 나가면 된다.
앞으로 OPENAI 의 gym 라이브러리를 불러와서 이 알고리즘들을 코딩하는 거를 해보겠다.
또 unity 에서 ml-agent 라이브러리를 이용하는 예제도 해볼 예정이다!
