

Push_swap이란?

최대한 적은 명령어를 사용하여 stack을 정렬하는 과제
알고리즘
보통 정렬이라고 하면 버블, 선택, 퀵, 병합 등 그런 알고리즘을 생각하지만, 이 과제는 조금 다릅니다. 이 과제에서의 목표는 얼마나 빠르게 정렬하는 것이 목표가 아니라 얼마나 적은 명령어를 사용하여 stack을 정렬하는 과제입니다.
이 과제에서 많이들 사용하는 알고리즘은 아래와 같이 있는데:
•
병합
•
퀵
•
모래시계
•
그리디
저는 그리디 알고리즘을 택했습니다.
왜 그리디냐, 병합, 퀵, 모래시계, 그리디 이 4개의 알고리즘에 대한 설명을 들었을 때 개인적으로 모래시계와 그리디가 제일 쉬워보였습니다. 모래시계를 해보고 싶긴 했으나, 다들 모래시계 알고리즘은 너무 이 과제만을 위한 알고리즘이라고 하여 이참에 그리디도 조금 익숙해질 겸 그리디로 풀었습니다. (그리디와 모래시계 알고리즘은 명령어 개수 최적화하기 쉽습니다!)
과제 요구 사항
stack 2개를 사용하여 stack a에 있는 수를 오름차순으로 정렬하는 것
stack이란?
자료구조의 일종으로, 한쪽 끝에서만 자료를 넣거나 뺄 수 있는 선형 구조(LIFO - Last In First Out)로 이루어져 있습니다. 자료를 넣는 것을 '밀어 넣는다' 하여 push, 반대로 넣어둔 자료를 꺼내는 것을 pop이라고 하는데, 이때 꺼내지는 자료는 가장 최근에 푸쉬한 자료부터 나오게 됩니다.

명령어
먼저 넣은 값이 나중에, 나중에 넣은 값이 먼저 나오는 구조를 가진 stack을 활용하여 푸는 과제이기 때문에 우리가 사용할 수 있는 명령어는 다음과 같이 생겼습니다.
swap
sa(swap a): Swap the first 2 elements at the top of stack a. Do nothing if there is only one or no elements.
a의 제일 위에 있는 두 요소의 위치를 교환한다. 만약 한개 또는 아무 요소도 없다면 아무 동작도 하지 않는다.
sb(swap b): Swap the first 2 elements at the top of stack b. Do nothing if there is only one or no elements.
b의 제일 위에 있는 두 요소의 위치를 교환한다. 만약 한 개 또는 아무 요소도 없다면 아무 동작도 하지 않는다.
ss: sa and sb at the same time.
sa 와 sb 의 동작을 동시에 한다.
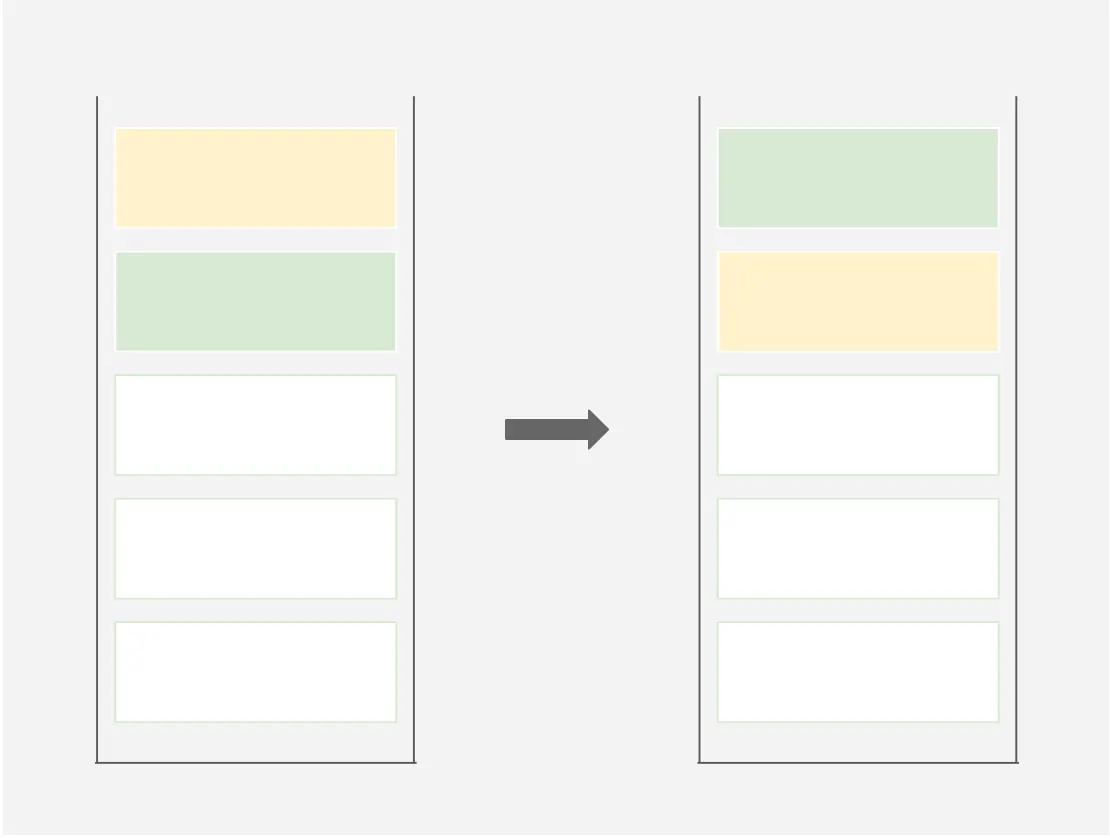
push
pa(push a): Take the first element at the top of b and put it at the top of a. Do nothing if b is empty.
pb(push b): Take the first element at the top of a and put it at the top of b. Do nothing if a is empty.
a 또는 b의 제일 상단에 있는 요소를 빼내어 다른 stack으로 옮긴다. 만약 뺄 요소가 없다면 아무 동작도 하지 않는다.


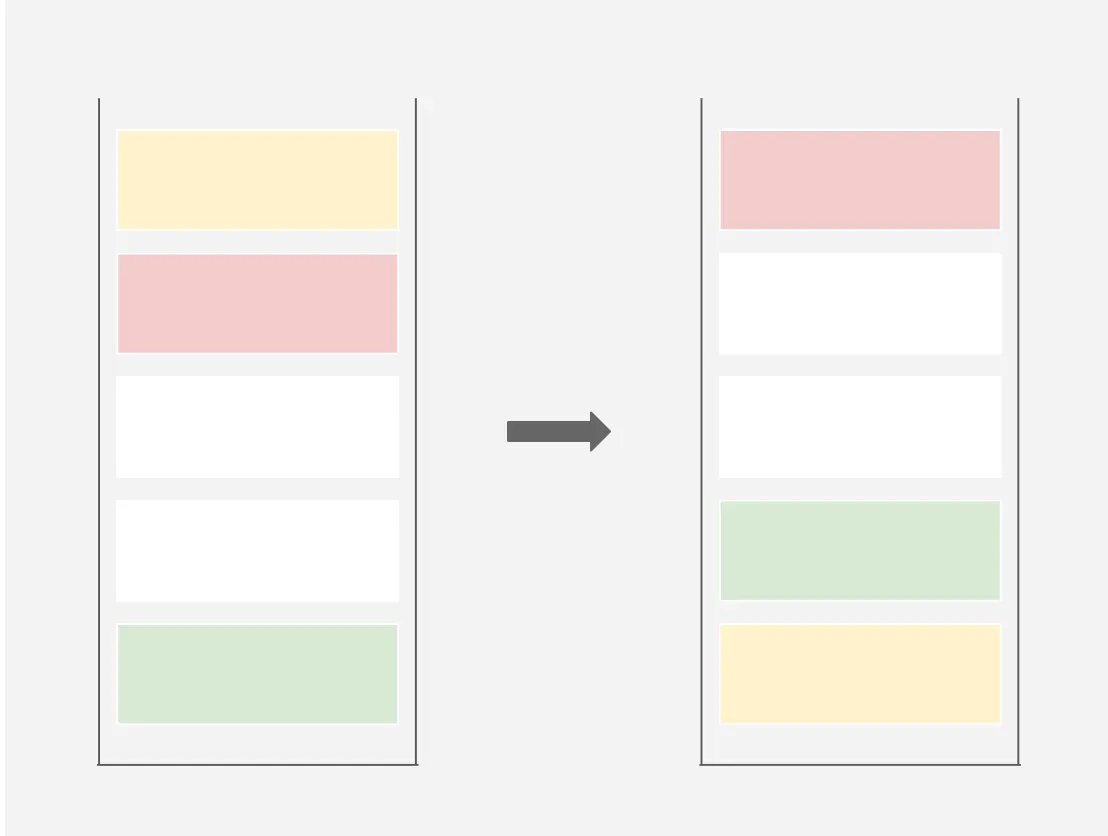
rotate
ra(rotate a): Shift up all elements of stack a by 1. The first element becomes the last one.
rb(rotate b): Shift up all elements of stack b by 1. The first element becomes the last one.
rr: ra and rb at the same time.
제일 상단에 있는 요소를 아래로 내린다. 첫 번째 요소가 마지막 요소가 된다.
rra(reverse rotate a): Shift down all elements of stack a by 1. The last element becomes the first one.
rrb(reverse rotate b): Shift down all elements of stack b by 1. The last element becomes the first one.
rrr: rra and rrb at the same time
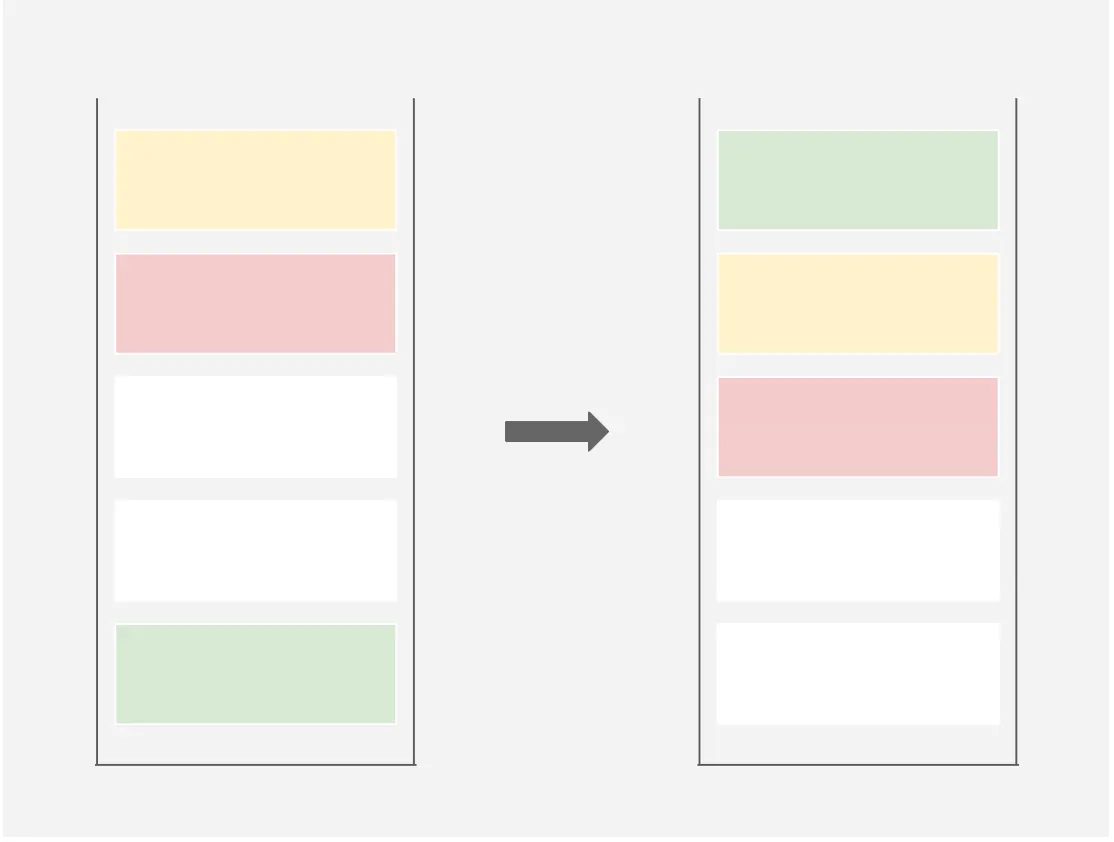
제일 아래에 있는 요소를 꺼내 상단에 놓는다. 마지막 요소가 첫 번째 요소가 된다.
parsing

argc, argv 로 들어오는 인자들을 받아 먼저 stack a에 저장해야 합니다. 이때, stack을 리스트로 만들지 단순 배열로 만들지 결정해야 하는데, 계속 stack에서 요소를 뺐다가 넣었다가 해야 하니 저는 양방향 연결 리스트로 짰습니다.
그리디 알고리즘
그리디 알고리즘은 굉장히 간단합니다!
우선 push_swap 과제에서 그리디를 사용하려면 pivot 값을 정하여 값의 크기에 따라서 partitioning 해준 뒤, 그것을 그대로 정렬하면 되는 것입니다.
pivot 구하기
갑자기 웬 pivot? 설마 퀵에서 사용하는 pivot? 네, 맞습니다. 우선 stack a에 있는 수들을 정렬하여 최적의 pivot 값을 구할 것입니다. 그렇다면 이 pivot들을 가지고 무엇을 할 것이냐, 바로 partitioning 해줄 것입니다.
partitioning
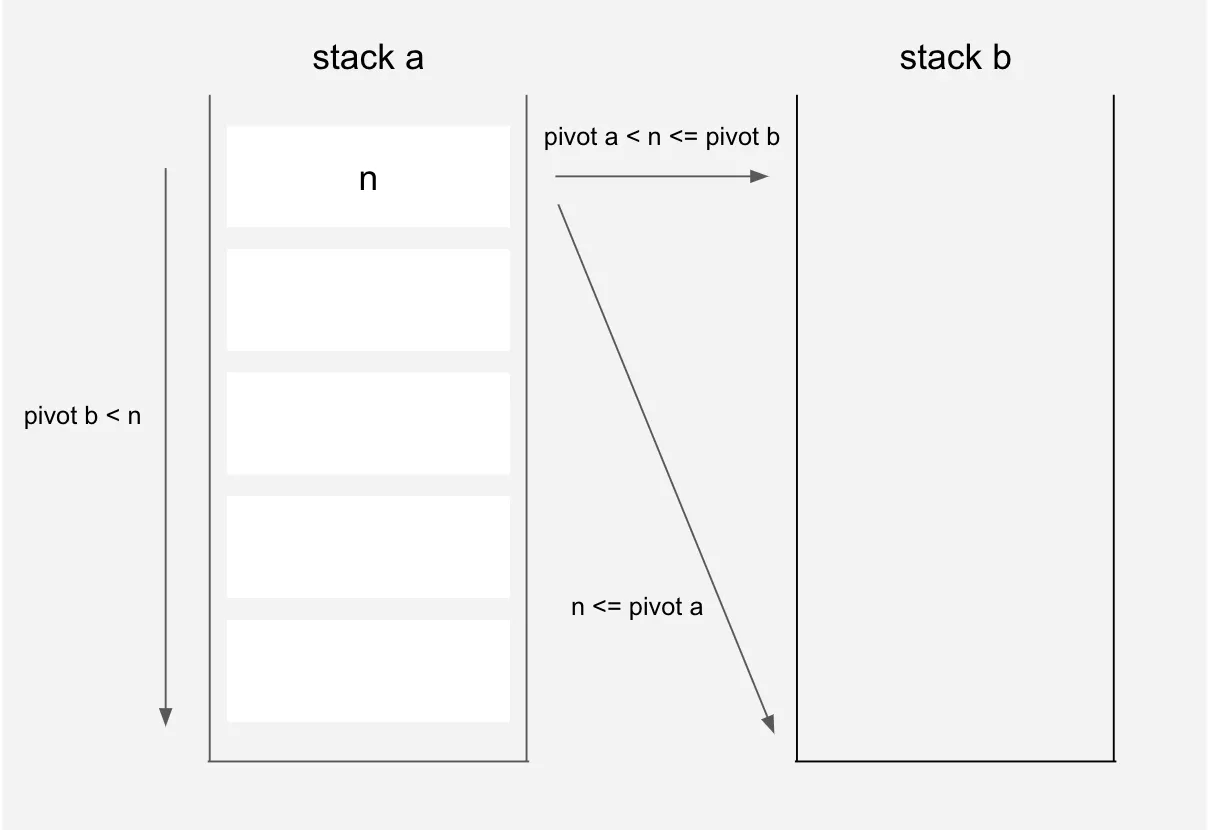
우선 피봇을 기준으로 나눈 뒤, a에 남아있는 수들을 b로 옮기면 다음과 같은 모양이 됩니다.
제일 큰 수들은 제일 위에, 중간은 그 아래, 작은 수 들은 더 아래에 있는 것이죠. 작은 수부터 옮긴다면 점점 더 큰 수를 옮길 때 rotate 명령어를 많이 사용해야 함으로 큰 수들부터 옮기는 것입니다.
정렬
이제 정렬만 하면 됩니다.
크게 세 가지 규칙이 있는데:
1.
stack a는 항상 정렬된 상태다.
2.
stack a에 넘어간 것은 stack b로 돌아오지 않는다.
3.
stack b의 요소마다 stack a에 정렬되려면 몇 개의 명령어를 사용하는지 계산한 뒤, 가장 적은 명령어를 사용하는 요소를 stack a에 넘긴다.
여기서 stack a가 어떻게 항상 정렬된 상태인지 궁금하신 분들이 있으실 겁니다. 그리고 가장 적은 명령어를 어떻게 구하는지 감이 안 오실 겁니다. 아래의 예시를 보시죠.
step by step
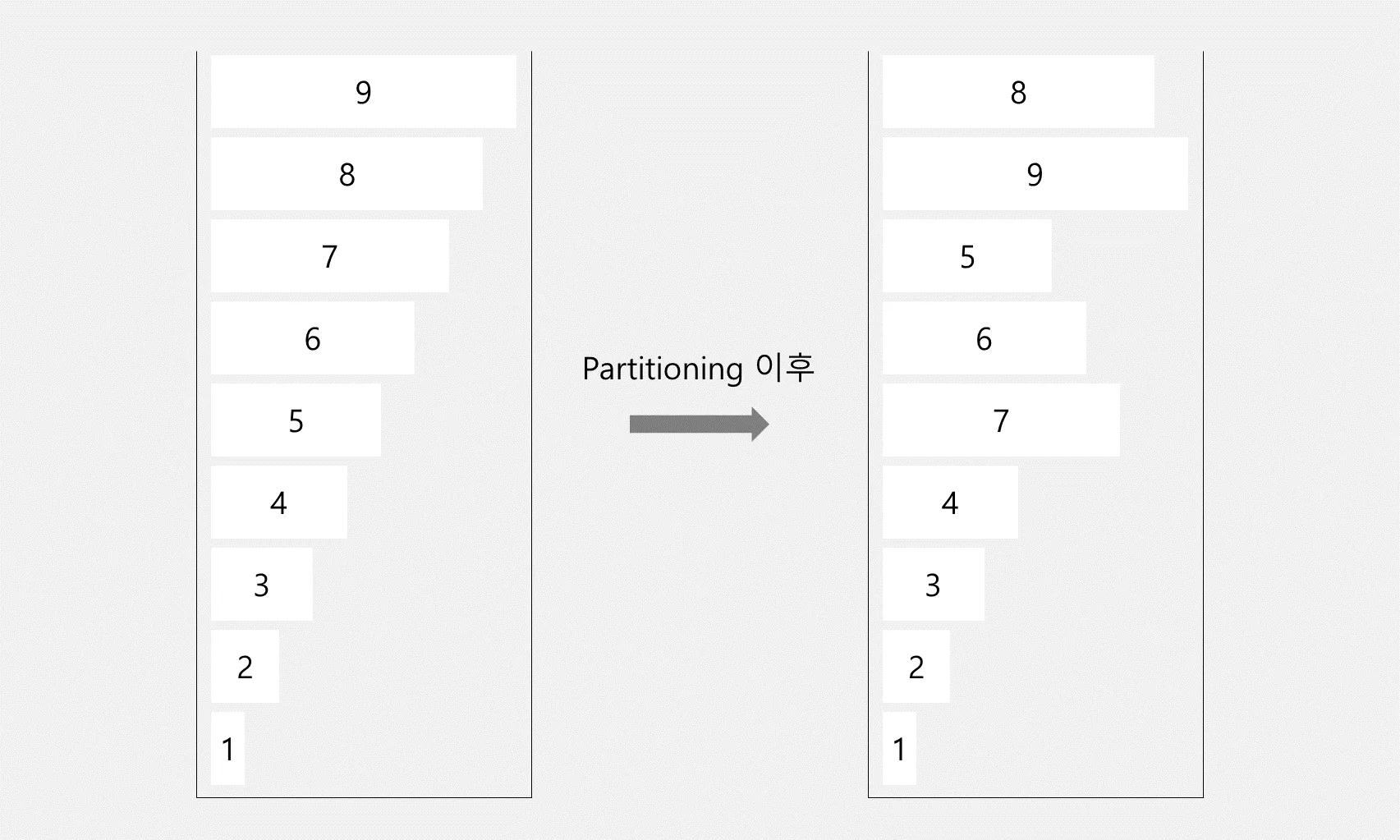
우선 stack a에 아래와 같이 들어왔다면 partitioning 이후에는 stack b에 저런 모습으로 담겨있을 것입니다. (pivot을 구하는 기준은 조금씩 다르기 때문에 아래 예시와 완벽히 같은 모습이 아니어도 괜찮습니다.)
partitioning을 완료했다면 이제 정렬을 할 차례입니다. stack b 옆에 각각의 요소가 stack a로 넘어가려면 몇 개의 명령어를 사용해야 하는지 정리하였습니다. 이때 우리가 알 수 있는 점은 각 요소의 인덱스 번호와 rb 명령어의 개수가 동일하다는 점입니다.
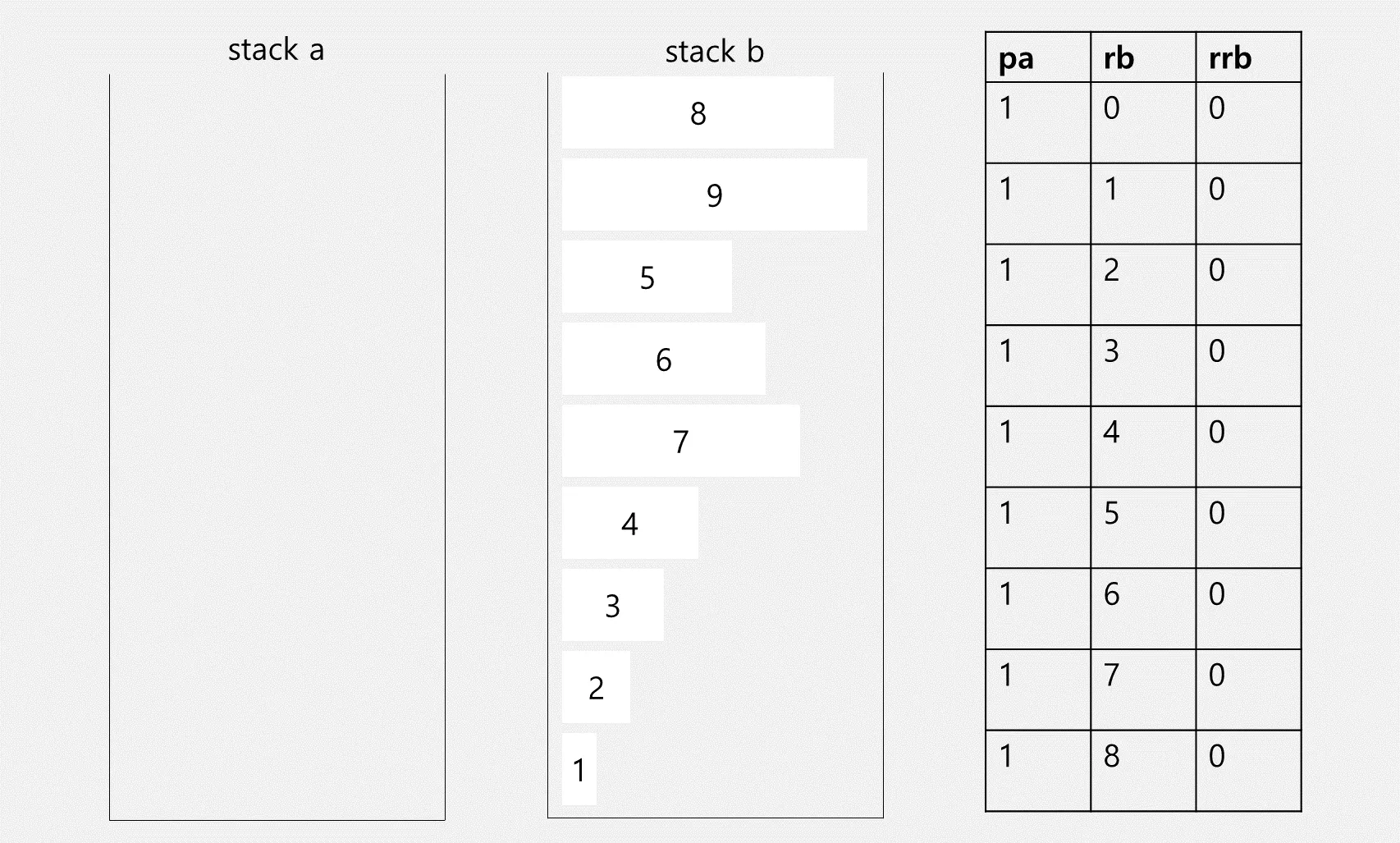
인덱스 순서가 중간이 넘는 5~8까지의 요소들은 rb를 하는 것보다 rrb를 하는 것이 더 효율적입니다. 이 규칙에 따라서 표를 수정하면 아래와 같이 됩니다.
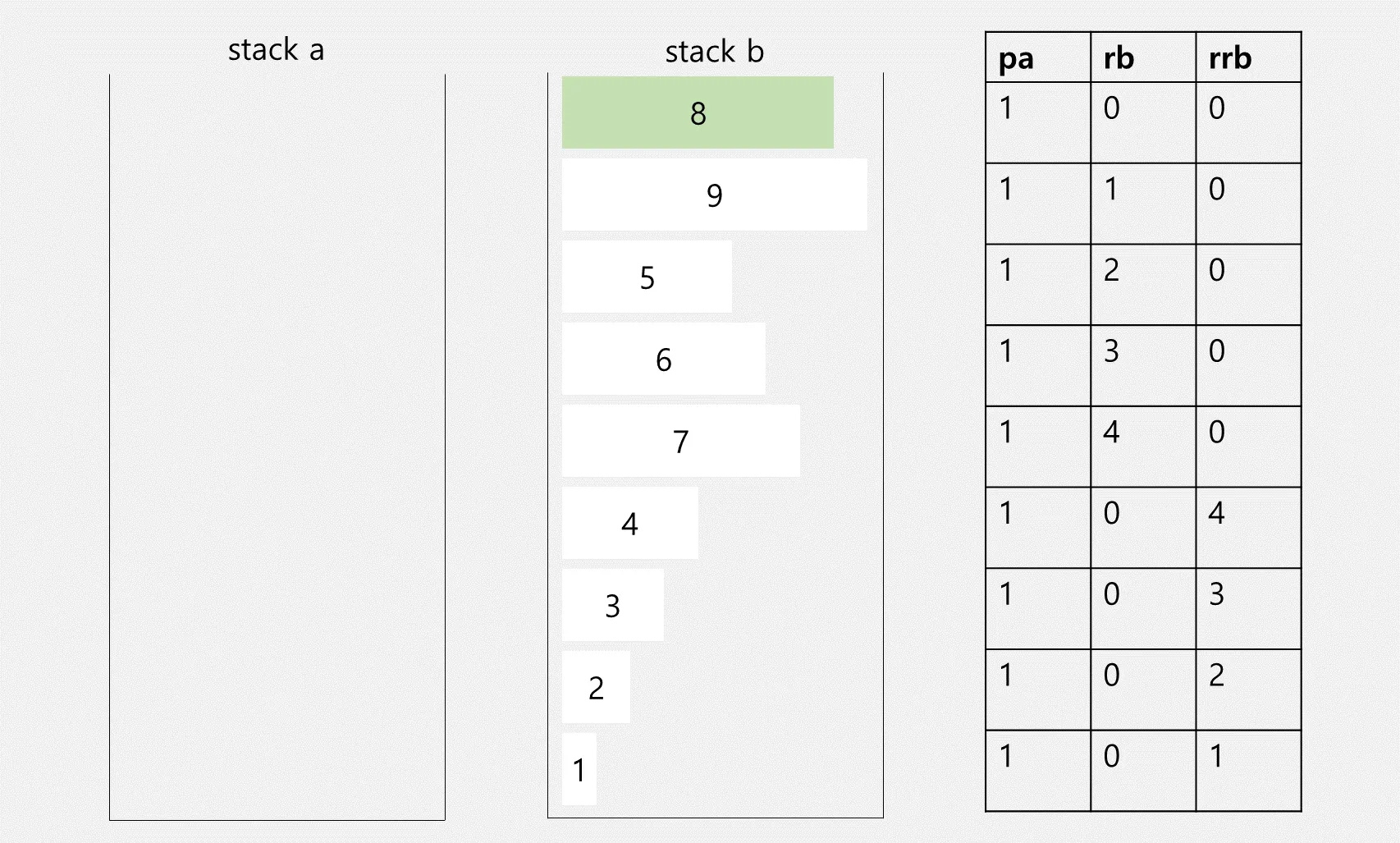
stack b의 요소마다 stack a에 정렬되려면 몇 개의 명령어를 사용하는지 계산한 뒤, 가장 적은 명령어를 사용하는 요소를 stack a에 넘긴다.
라는 규칙에 따라서 가장 적은 명령어를 사용하는 8을 stack a에 넘깁니다.
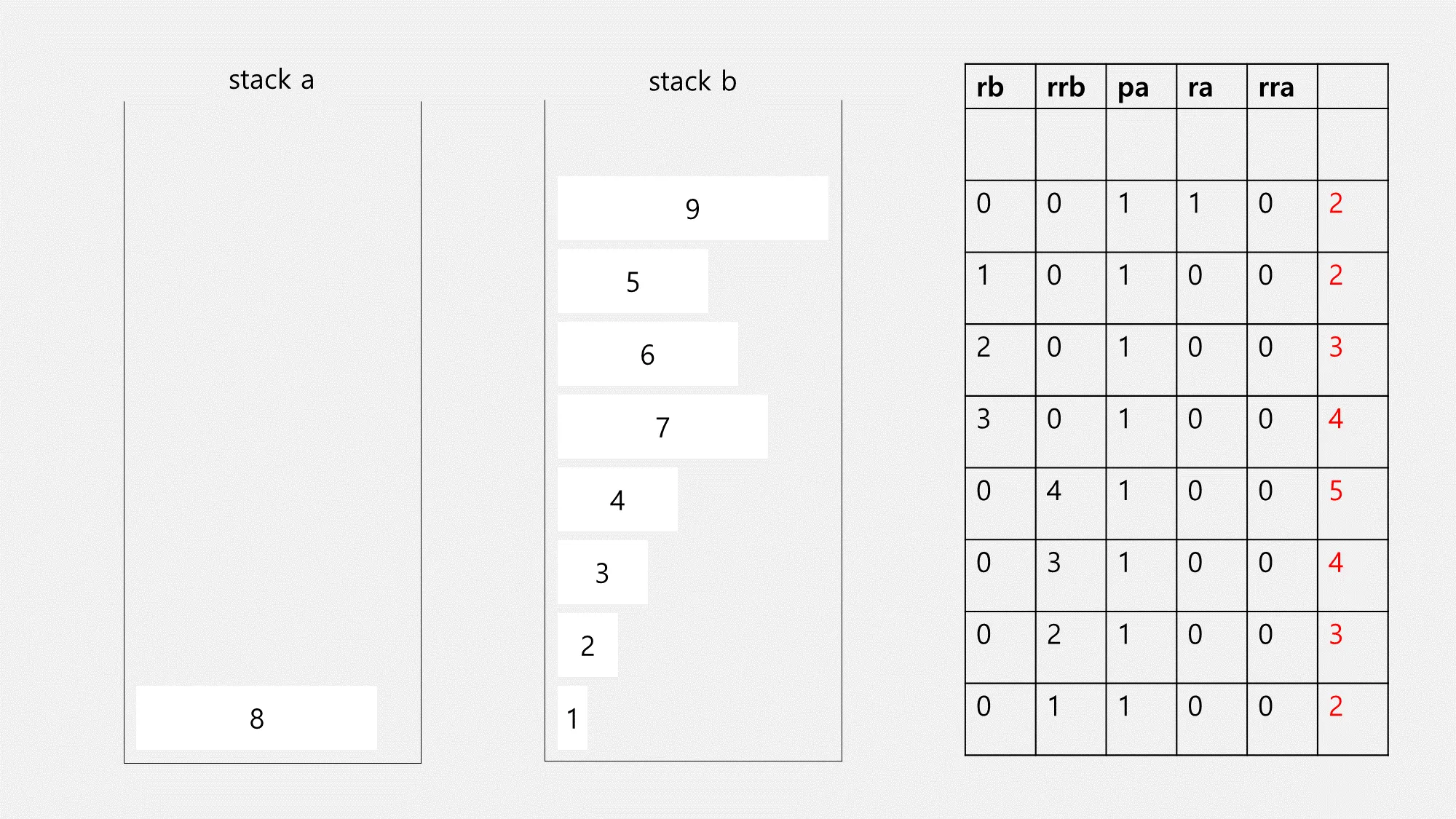
이제 다음 넘길 요소를 찾아야 합니다.
stack a는 항상 정렬된 상태다.
라는 1번 규칙에 따라, 9는 8 다음으로 가기만 하면 되니 8의 인덱스 + 1만큼 ra를 하면 됩니다. 이런 식으로 명령어 개수를 구하고, 만약 동일한 명령어 개수를 쓰는 요소가 여럿이라면 인덱스순으로 우선순위가 정해집니다.
가장 앞쪽에 있는 요소가 9이니, 이제 9를 구한 명령어만큼(pa 1번, ra 1번) 실행하면 됩니다. 이제 규칙을 알았으니 반복하면 됩니다. (실은 pa는 언제나 한 번만 하므로 명령어 개수 계산할 때 pa를 빼놓고 구합니다만… 그림을 잘못 그렸습니다.)
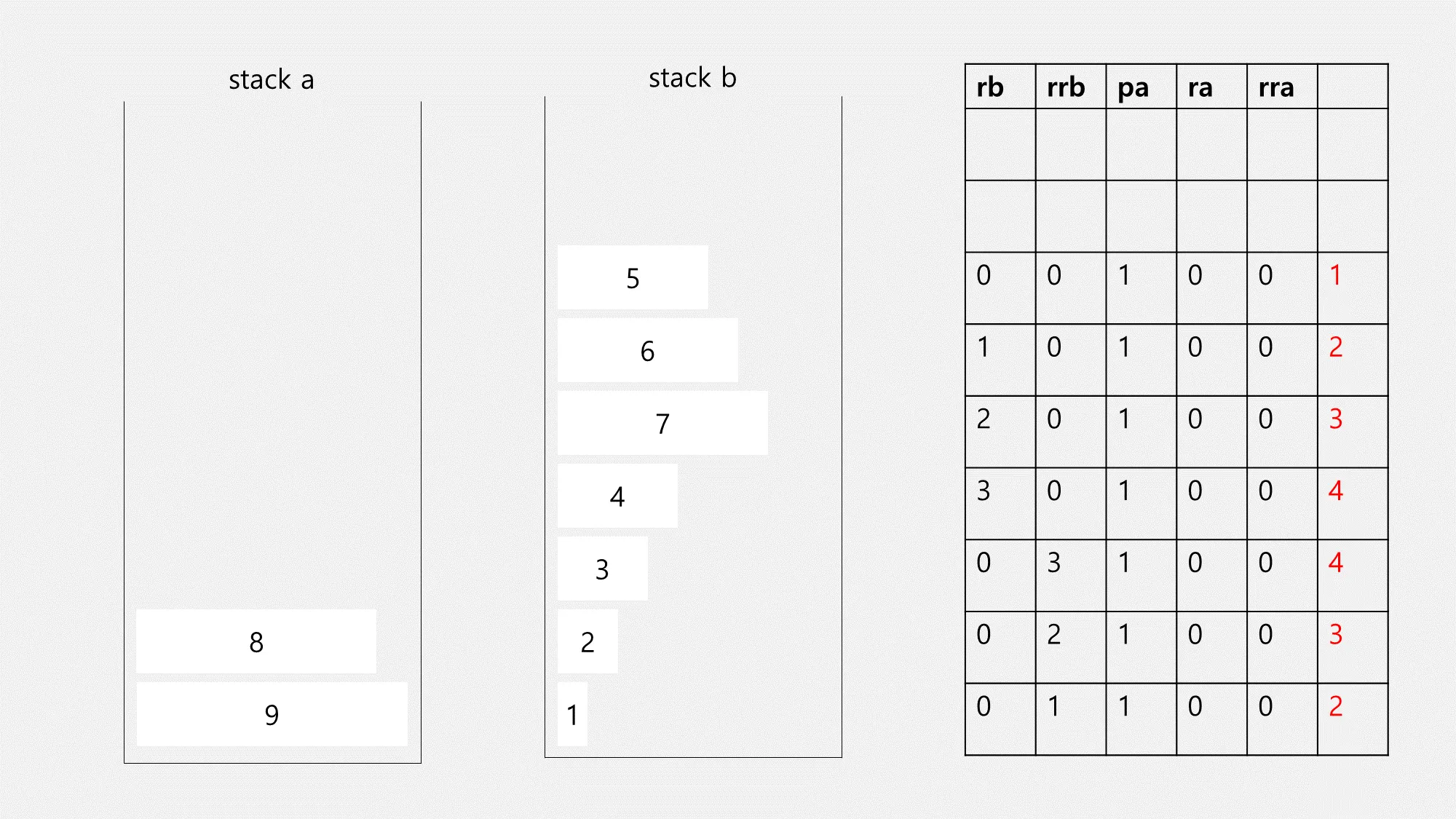
이걸 계속 반복하면 마지막에는 아래와 같이 정렬됩니다!
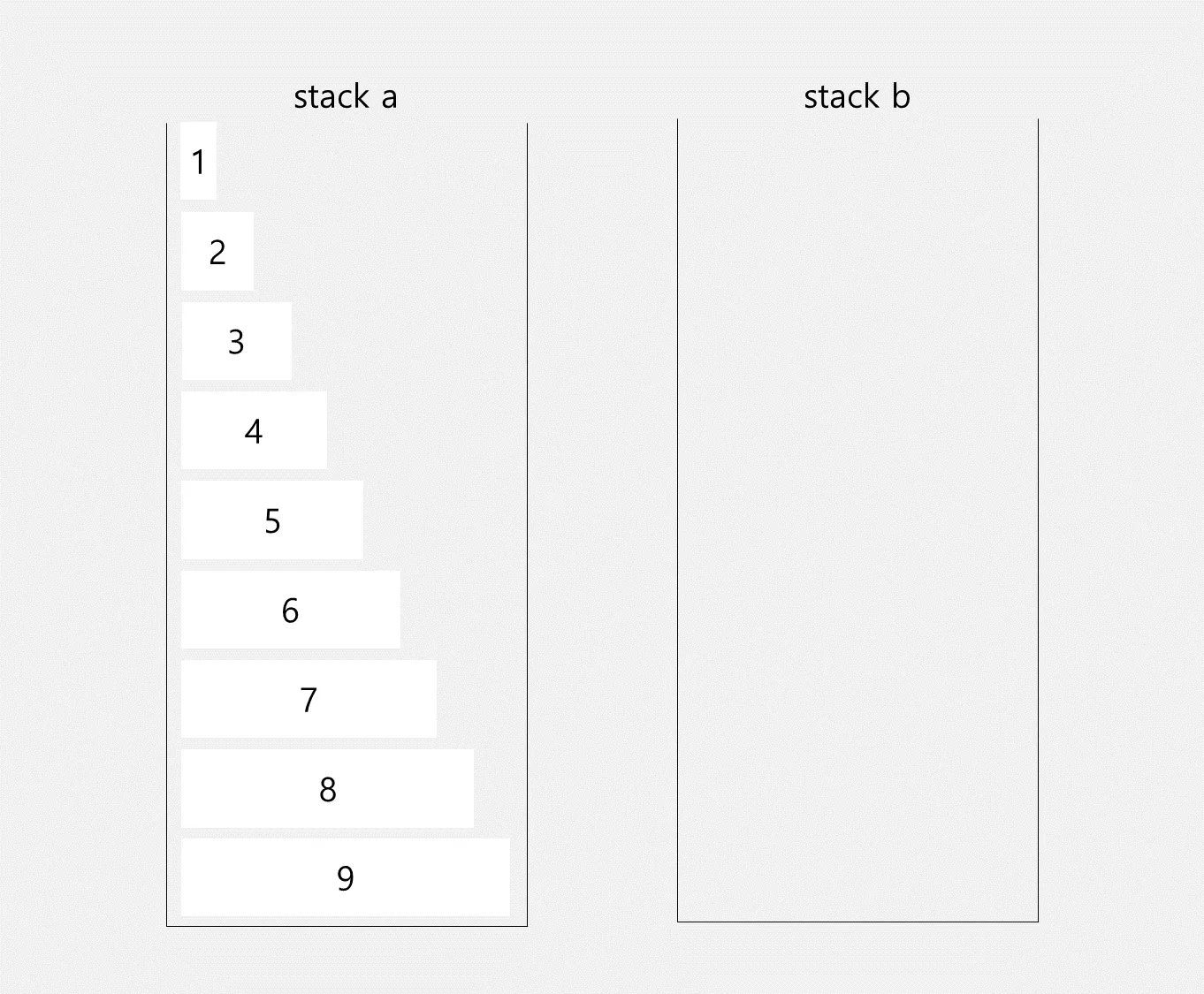
이렇게 해서 욕심 많은 push_swap은 끝났습니다.
정리
•
이 3가지 규칙만 기억하면 그리디는 끝입니다.
1.
stack a는 항상 정렬된 상태다.
2.
stack a에 넘어간 것은 stack b로 돌아오지 않는다.
3.
stack b의 요소마다 stack a에 정렬되려면 몇 개의 명령어를 사용하는지 계산한 뒤, 가장 적은 명령어를 사용하는 요소를 stack a에 넘긴다.
