



명령어 하나로 데이터 여러개를 동시에 처리하는 것
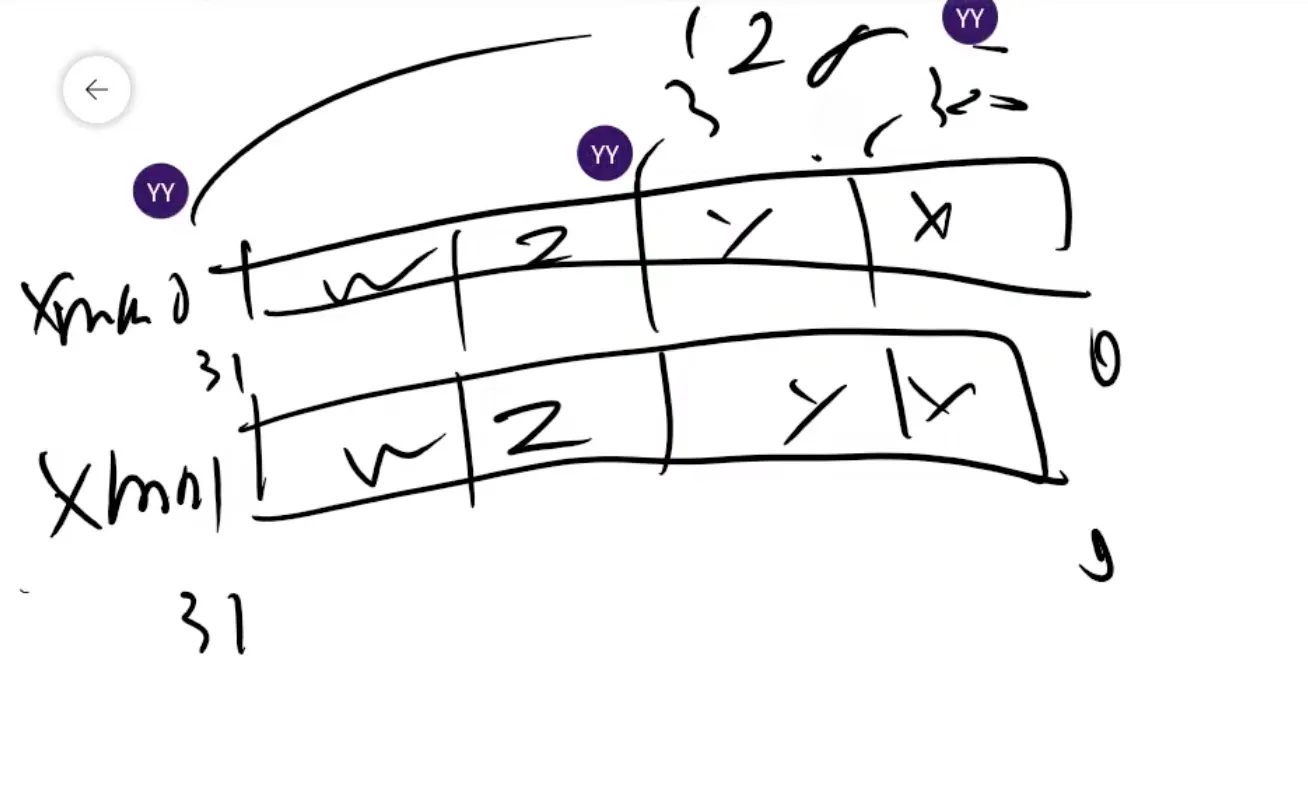
0 ~ 127 bit로 표시
각 하나는 32bit(4byte) → 4개 128bit(16byte)
그림은 SSE의 상황
AVX는 한 성분 4byte 씩 8개 → 256bit
AVX는 16개붙어서 512bit

여기서 필요한거 찾아서 공부


가장 이상적인 상황 : SSE 같은거몰라도 컴파일러가 알아서 해주는것
SSE는 표준은 아닌데 현재 사실상 표준인 상황
32bit float을 FPU대신 SSE레지스터 xmm을 사용함 → why : 레지스터 연산이 조금 더 빠름
FPU가 정밀도가 더 높지만 어지간해서 별차이없어서 그냥 xmm으로 전달함
자동으로 vectorlize까지는 못해줌(해주는 곳도 있지만 대부분 안해줌 시원찮음)
SSE짜는 법 두가지
1.
어셈, C,C++ inline 어셈 (64bit에선 사용불가)
2.
Compiler Intrinsic
현재는 os안에서도 SSE, AVX 사용중

어셈으로 짤꺼면 함수하나를 통으로 짤것 안그러면 C코드와 어셈이 만나는 부분을 최적화 할 방법이 없음(compiler가 최적화 안해주는 듯)

디버그모드에서 Compiler intrinsic으로 access한 레지스터들을 찾는데 레지스터를 C++에서 바로 노출하지 않음 그러니까 VS에서는 어셈을 레지스터이름을 watch에 치면 바로 보여주는데
실제로 메모리 어딘가에 매핑을 하고 그 메모리를 보여주는 것
디버그모드로 빌드를 돌려서 어셈을 보면 명령어 앞뒤로 굉장히 많은 카피들이 붙어있음
Tip 디버그 모드로 충분히 테스트한다음에 릴리즈로 뺄 것


movaps align된 메모리를 읽고 씀
SSE 16byte align
AVX 32byte align
이유 : 메모리 버스
어셈코드에서는 moveaps하난데 컴파일러 인트린식 구현을 할때는 load store로 구분되어있음
정렬되어있지않으면 exception 크래시남
movups : 정렬되어있지 않은 메모리를 가져올때 사용
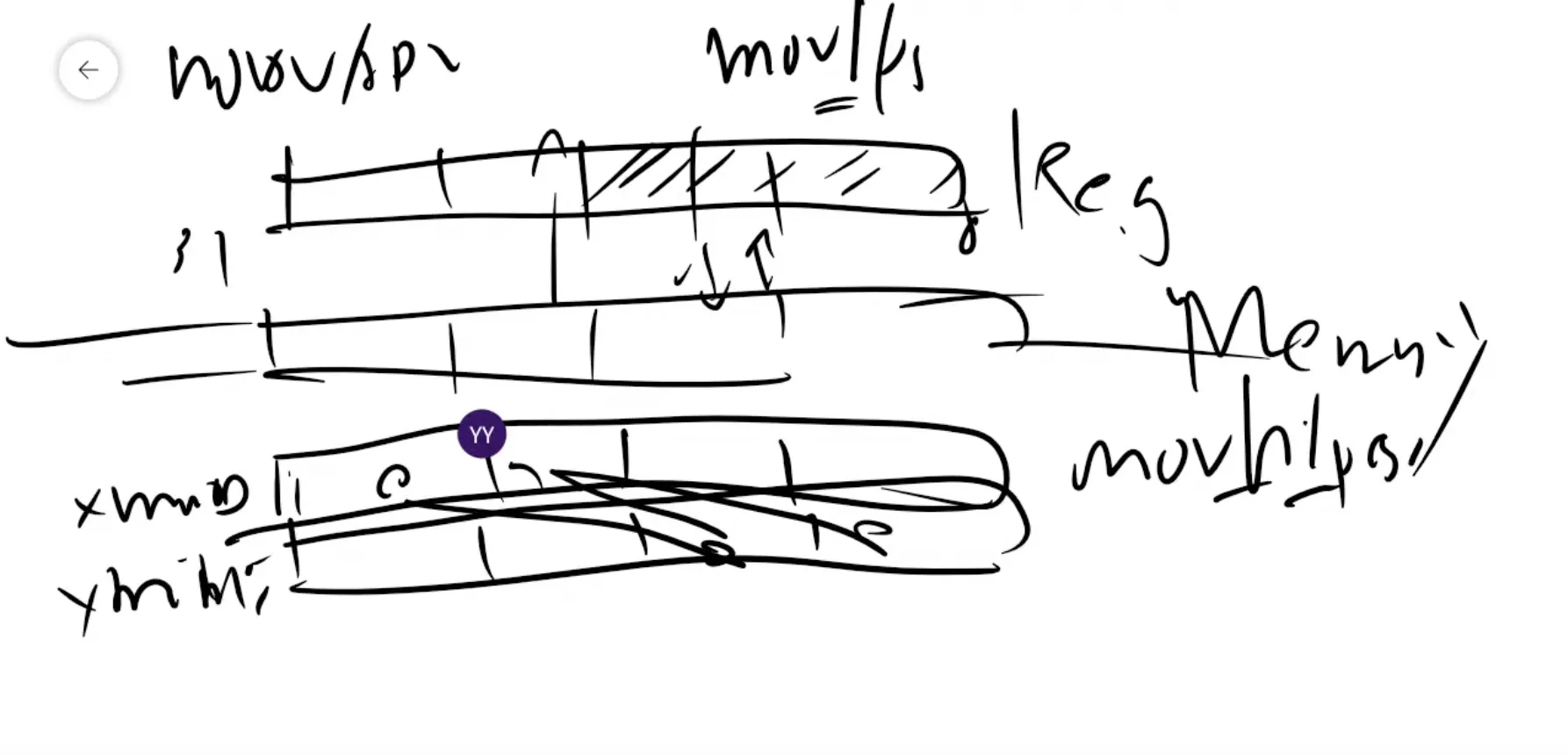
movhlps : 레지스터간 높은 주소 반을 낮은 주소 반으로 옮김
movlhps : 레지스터간 낮은 주소 반을 높은 주소 반으로 옮김
movlps : 하위 8byte 성분을 읽고 쓰는것
movss : 싱글단위
ps : 네개짜리 동시에 억세스
ss : single scalar
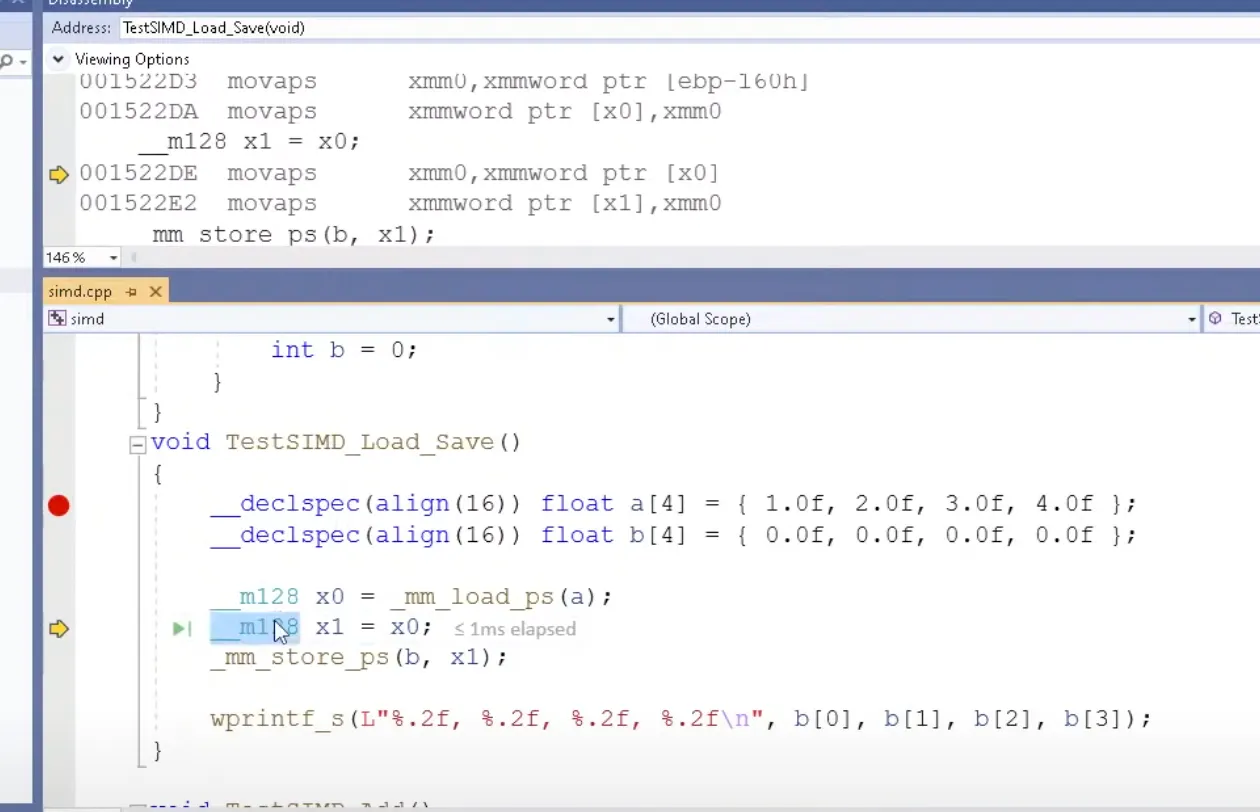
x1 = x0 대입한게 movaps로 바뀌진 않는데
builtin type으로 _m128 SSE를 위한 타입이라 컴파일러가 인식함 레지스터로 매핑되어있으면 movaps로 최적화해버림
align되어있으니 이렇고 align안 시키면 movups로 바뀜

굉장히 많은데 그 중 극히 일부만 가져옴

rcpps : 네 성분을 동시에 역수 취해줌
sqrtps : 네 성분 동시에 각각 제곱근을 구함
rsqrtss : 제곱근의 역수 ( 벡터 노말라이즈할때 많이 사용)
x,y,z,w
2차원의 경우 SIMD 느릴수도있음
벡터 놈을 노멀라이즈할때 벡터 길이가 0이 되는 경우
0으로 나눔 → nan으로 세팅됨
크래시가 안남
노멀라이즈 함수만들때 길이가 0인경우 실패 리턴 or 0으로 채워줄것 나누기전에 한번 검사해볼것!
__m128i : 정수형
__mm_cvttps_epi32 : 실수형 벡터 받아서 정수형 벡터로 컨버팅
(cvt converting. t : 버림 안붙이면 반올림함)

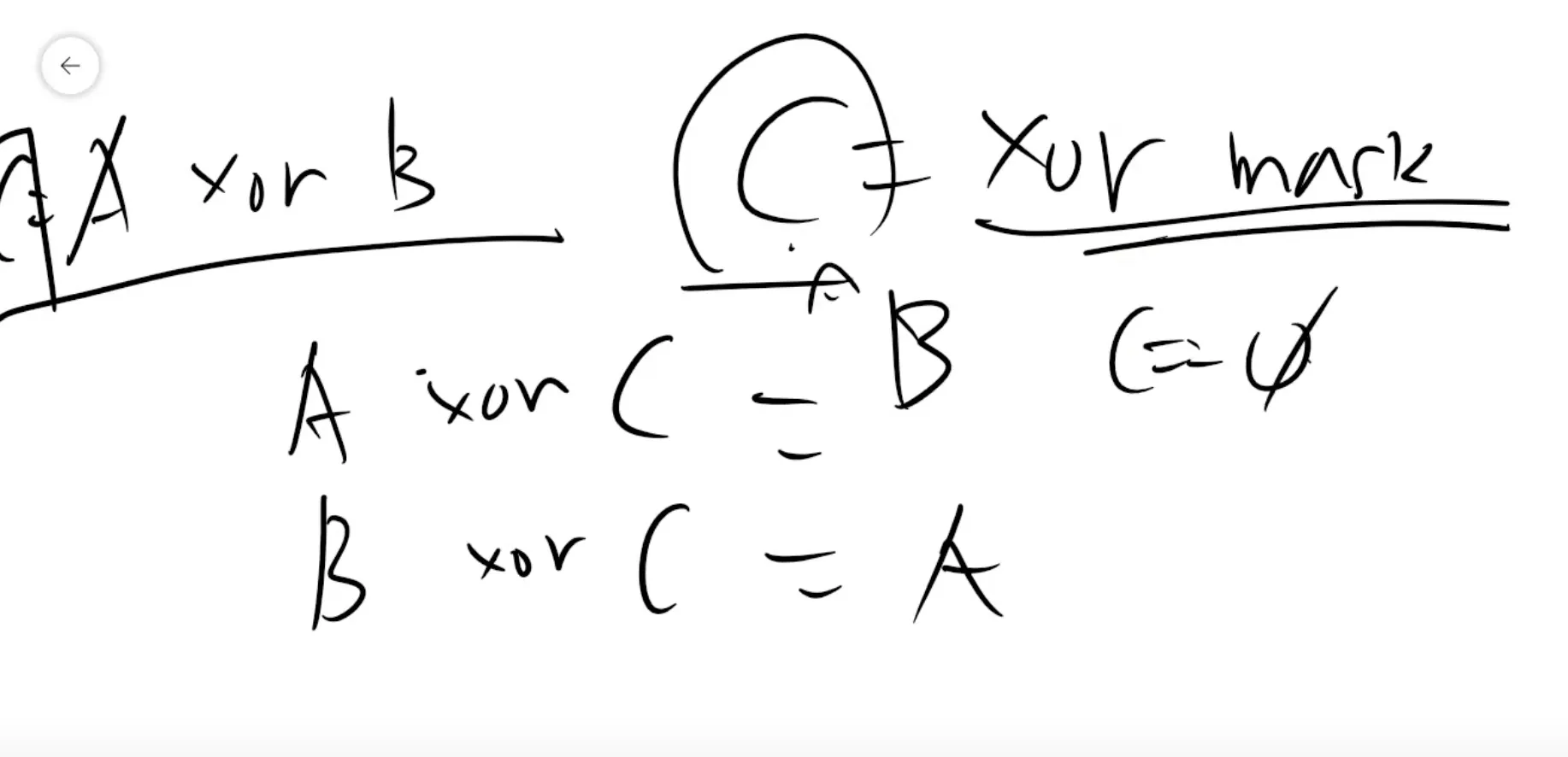


합구하기 아래는 같은 asm코드
내적구할때 유용
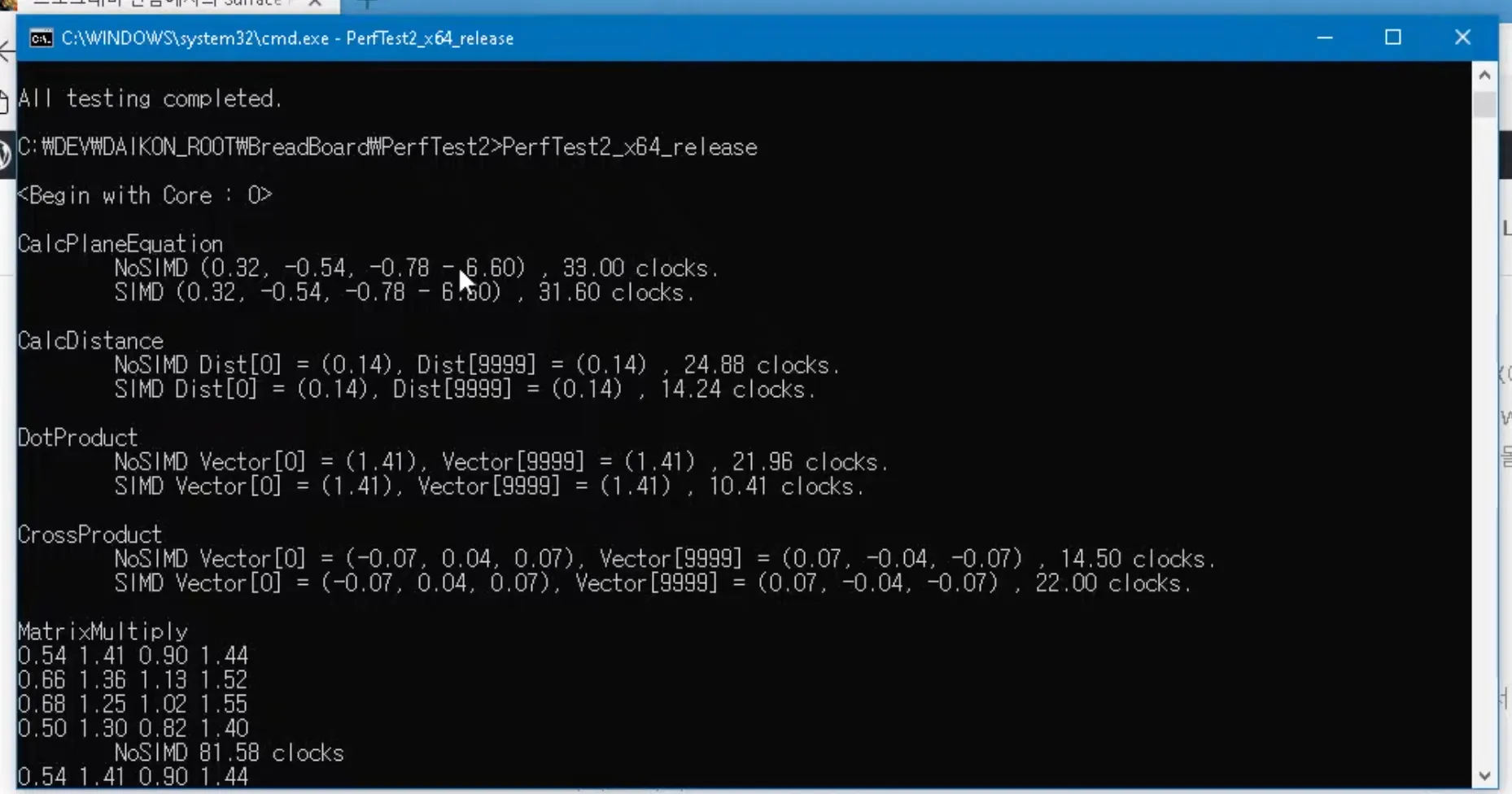
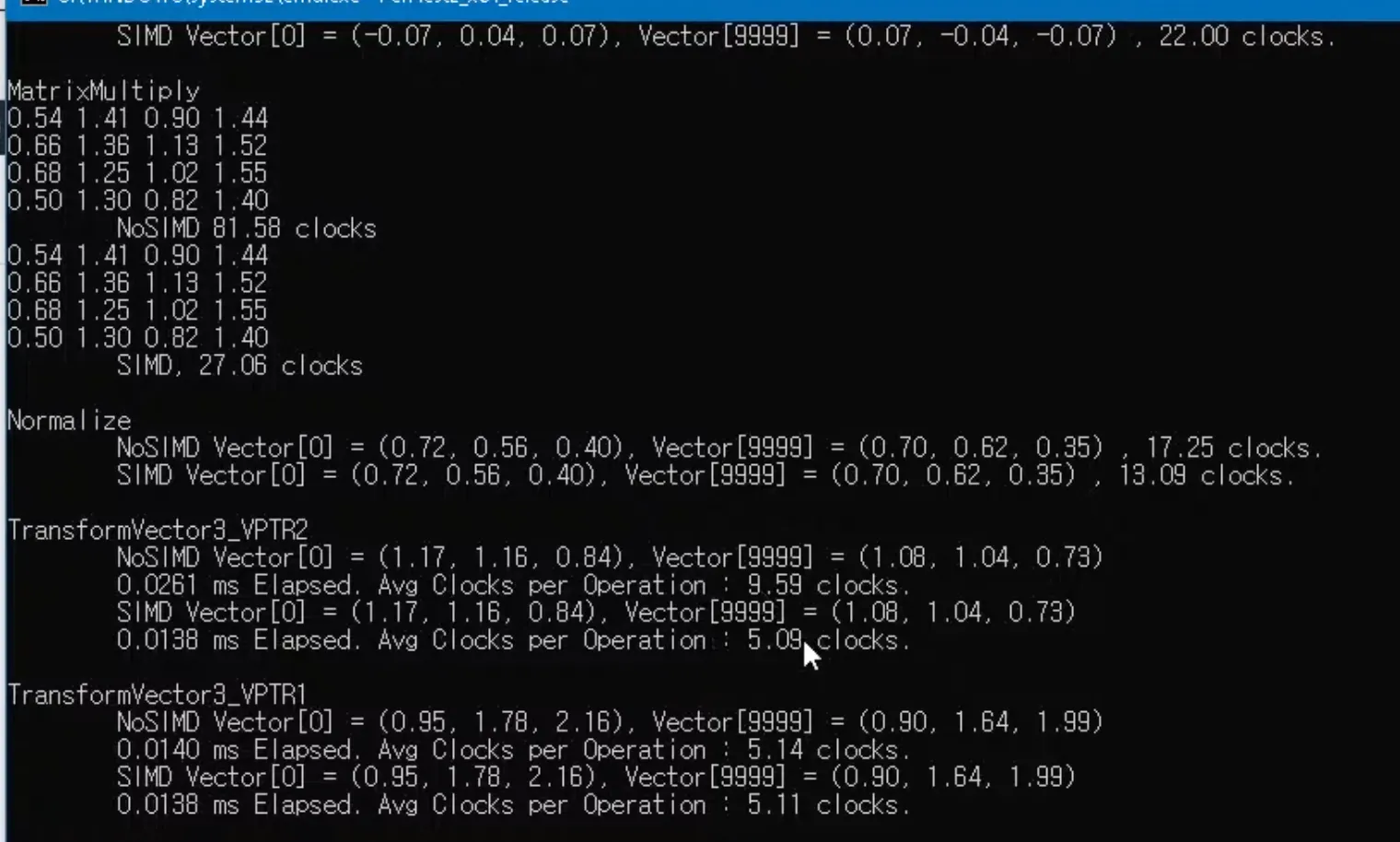
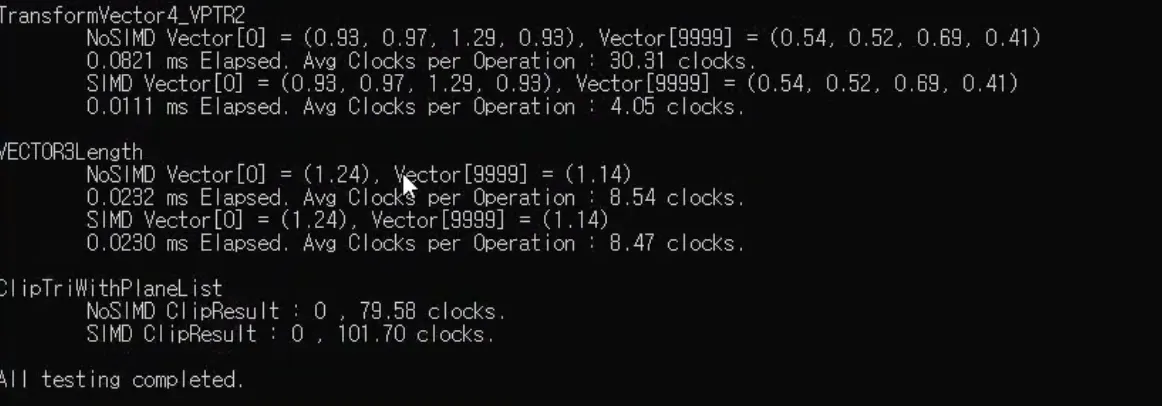
clock 테스트는 해당 방법을 이용
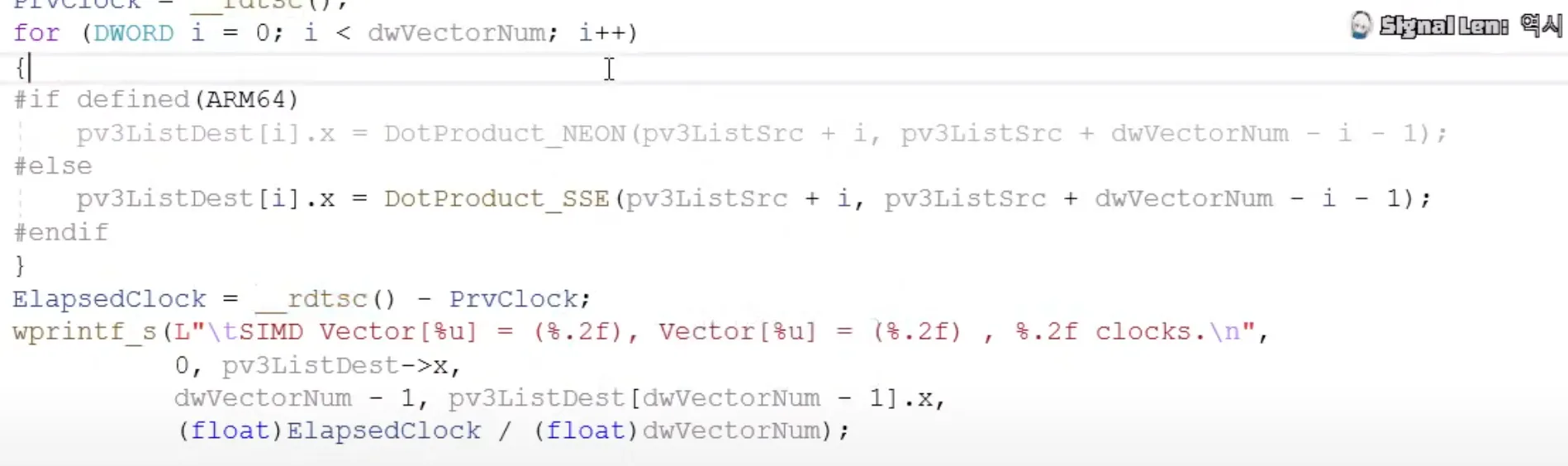
__rdtsc() : 클럭카운터

이런식으로 클럭카운트를 구함

일반적인 내적
SSE로 짠 내적
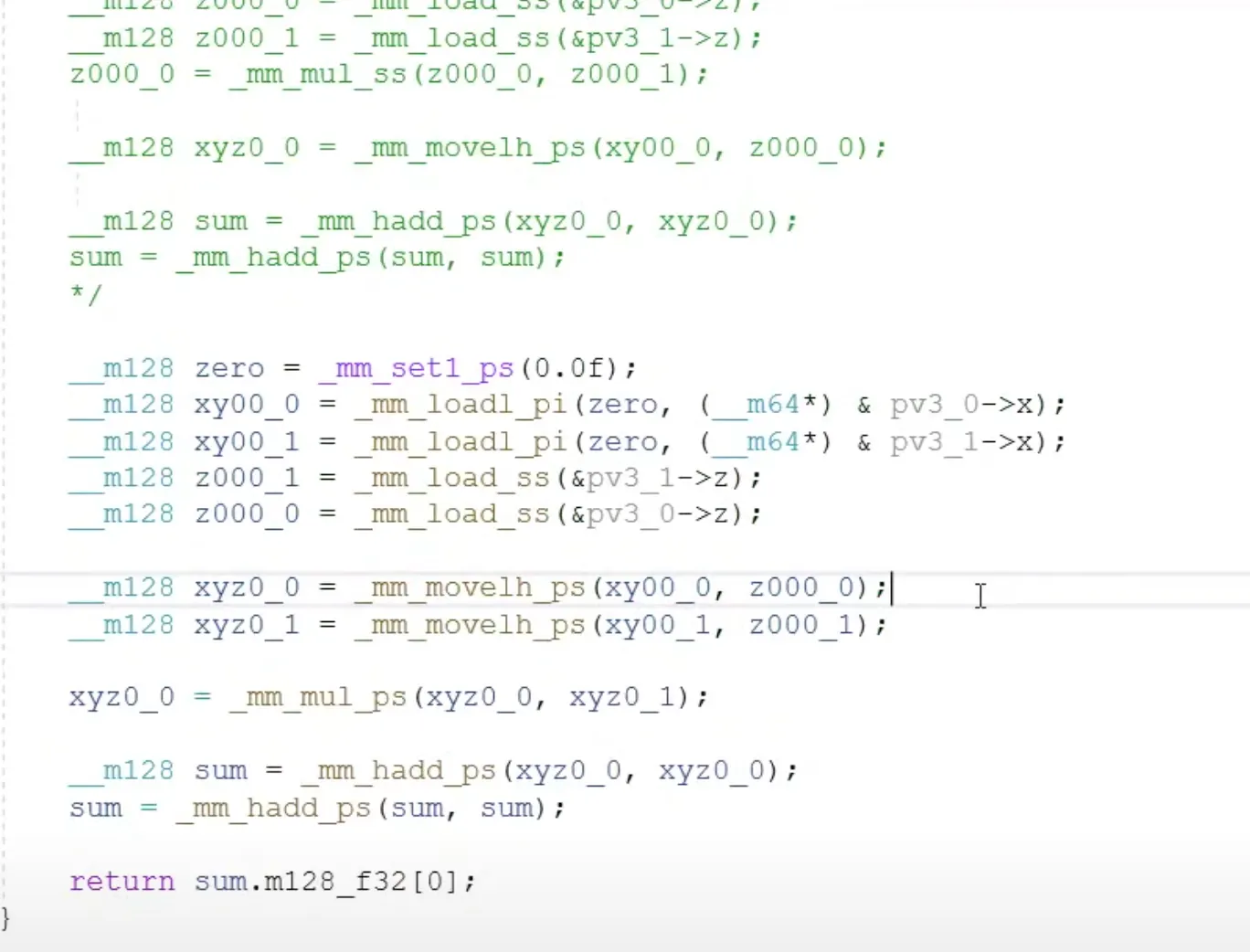
asm안쓰고 intrinsic만 사용
test 코드에서는 벡터가 3개짜리라
_mm_loadl_pi 로 xy성분 추출
_ss 로 z 성분 추출
한번에 안받은 이유.
heap으로 할당받을때 debug모드에서는 뒤에 패딩을 넉넉하게 놓지만 release모드에서는 칼같이 할당함 따라서 vector 위치를 벗어난 주소가 uncommited 메모리 일 수있음 이경우 memory fault 발생
왜 vector 0을 순서대로 안하고
0 = xy
0 = z
1 = xy
1 = z
이렇게 안하고
0 = xy
1 = xy
0 = z
1 = z
로했는가
어셈으로 짤때는 파이프라인 효율을 위해서 의존성이 적게 순서로 짰는데 그 버릇으로 함
(현재는 보통 compiler에서 최적화 처리해주는 부분)
## 벡터 매트릭스 곱
기본

코드에서 vector를 배열로 받음.
바꿀 점이 100개일때 함수 콜을 100번을 하면 너무 느리니까 한번에 받도록 처리함.
보통 점을 변환할때 점하나만 변환하지않고 여러개를 변환을 함.
SSE
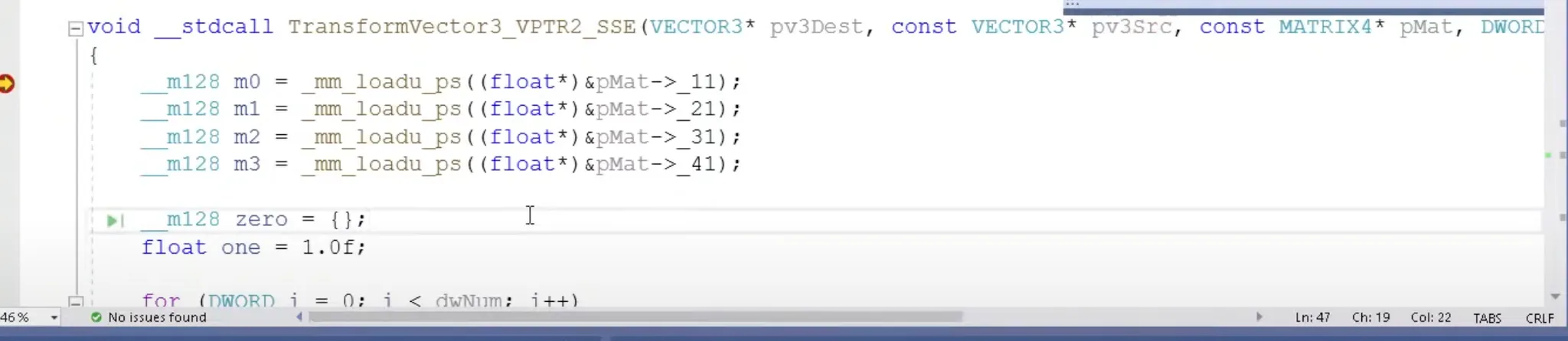
loadu : unaligned
파일에서 읽거나 패킷으로 날라올때는 매트릭스의 경우 unaligned 될 수. 있다고 함.
4x4 매트릭스간의 곱은 전치를하면 간단함
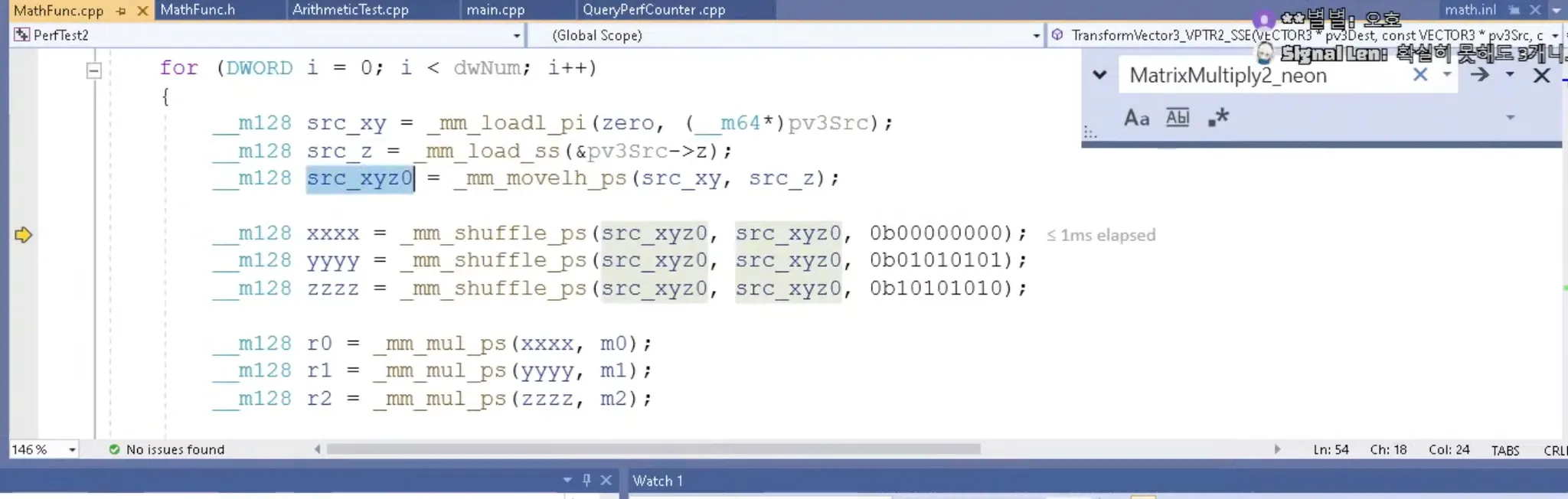
__mm_shuffle_ps

어려워서 잘 이해못함.. 아무튼 위 코드를 통해서
각 성분만 네개씩 채운 m128을 구할 수가 있음
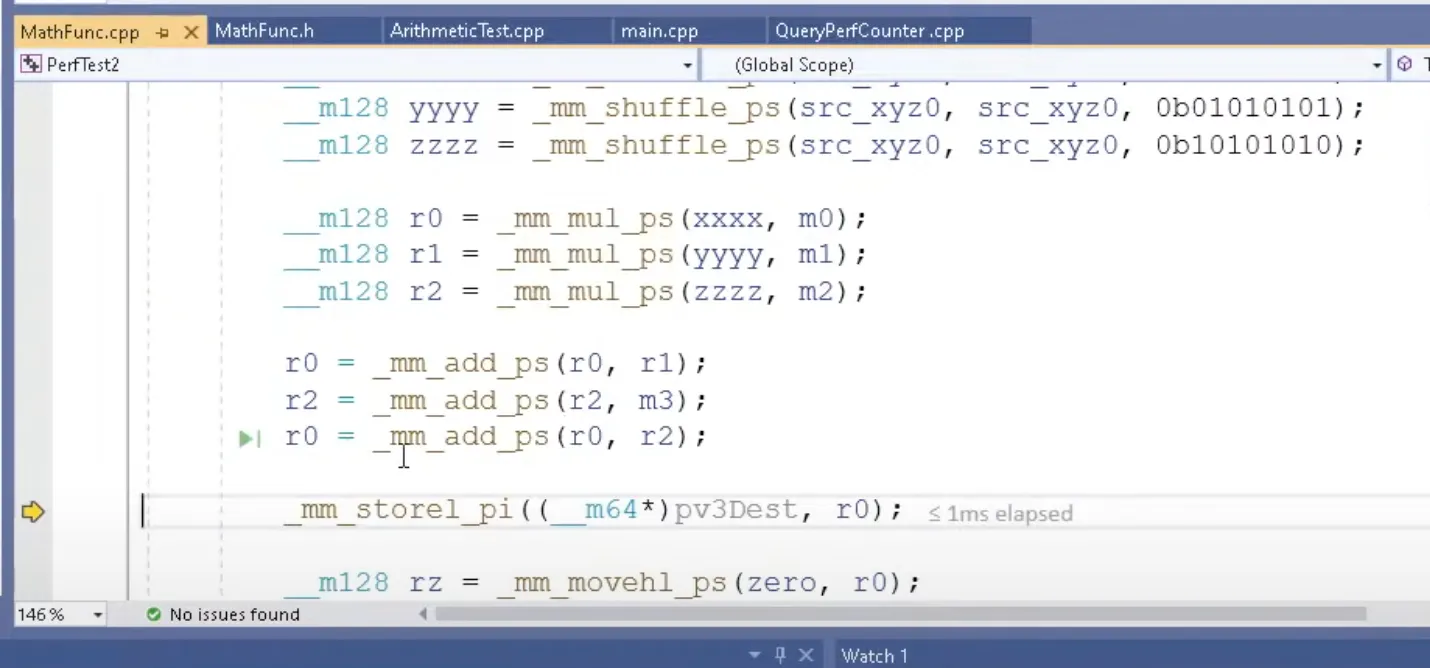
구한다음에 한줄씩 각각 곱함 r0, r1, r2
벡터 길이 구하기

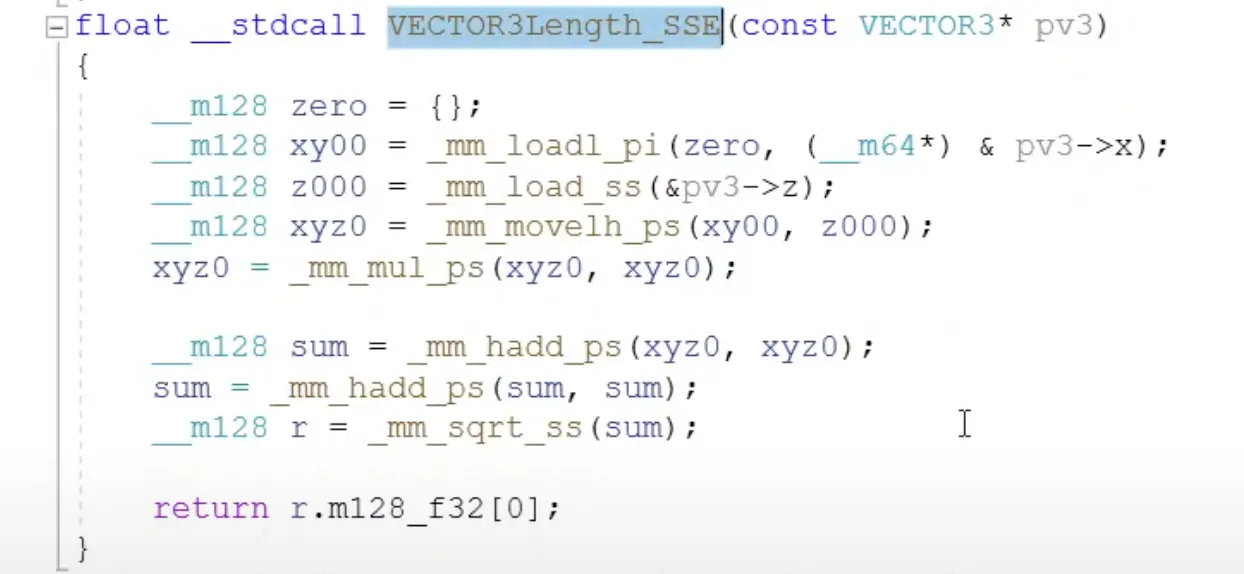
막상 해보면 느릴이유가 없는데 막상 해보면 nosimd보다 막 빠르지는 않음 오히려 느린경우도 있을거고..
추측하기로
각 연산에 추가적인 클럭을 먹거나 simd를 썼을때 클럭이 떨어지는 이슈가 있을것으로 추측
외적

simd로 짜기 좋지가 않음..
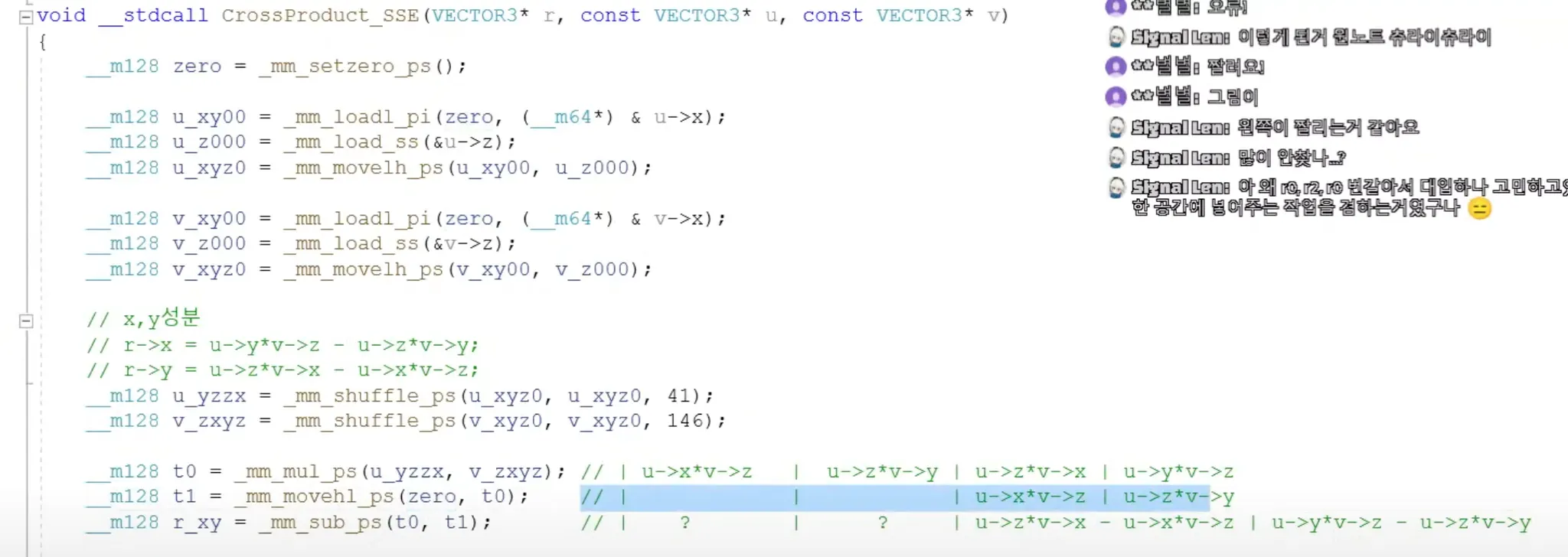

성능도 잘 안나옴
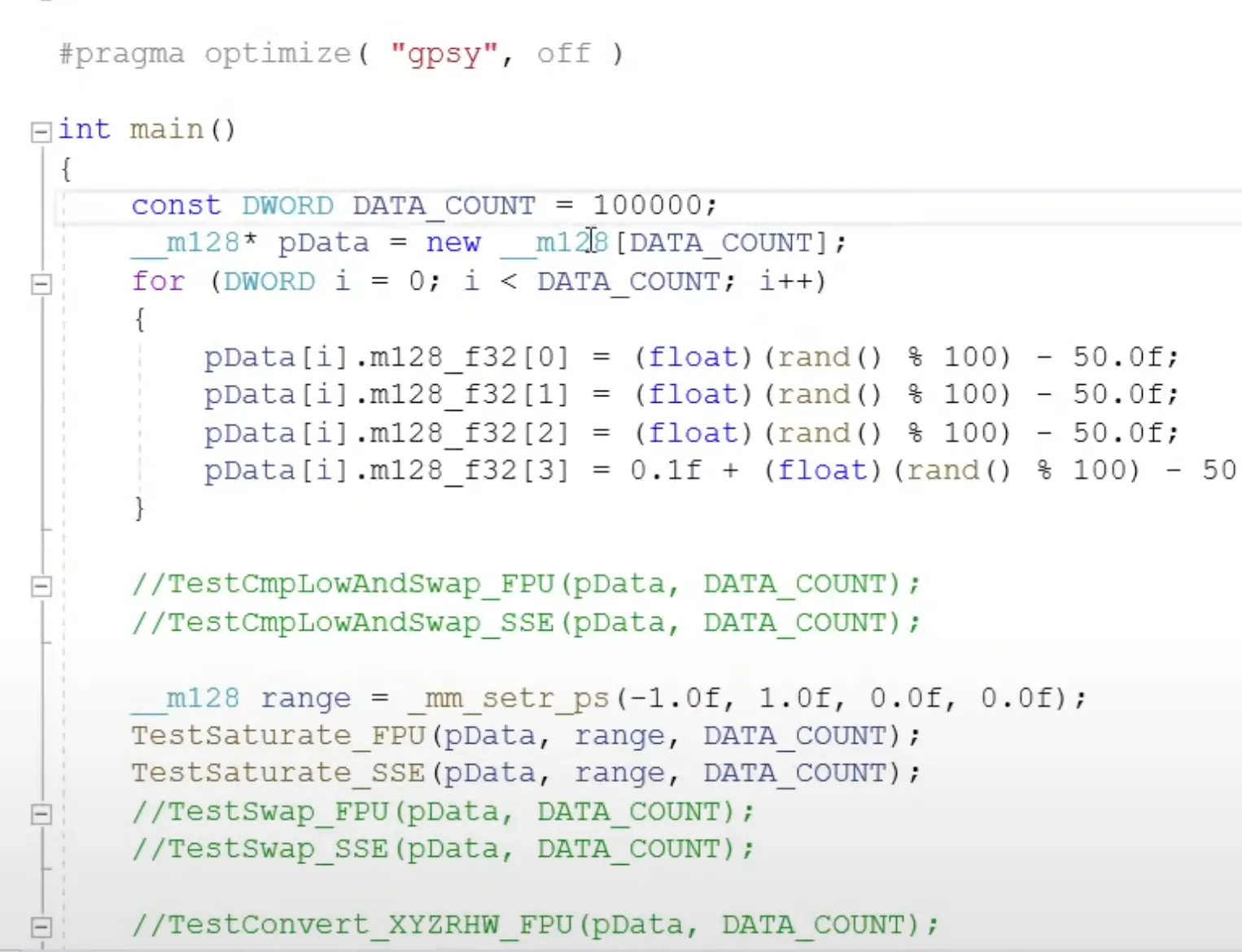
옵티마이즈를 껐는데 intrinsic을 쓰면 디버그모드에선 엄청 느려서 릴리즈 모드에서 테스트를 해야하는데
릴리즈 모드에서 테스트를 할때 문제점이 테스트 데이터 모아서 테스트를 하기 전인 메인 문도 최적화를 해버림 10000번 호출하고싶은데 한번만 함수호출하거나 상수레벨의 연산으로 끝내 놓을 수가 있음
벤치마크 프로그램 짤때는 caller쪽은 opt를 꺼줄것
디버깅할때 편함.
릴리즈모드에서만 일어나는 버그같은거 이거 걸어보면서 버그가 나는지 안나는지 테스트가 가능

align 되어있는지 체크하는 코드
