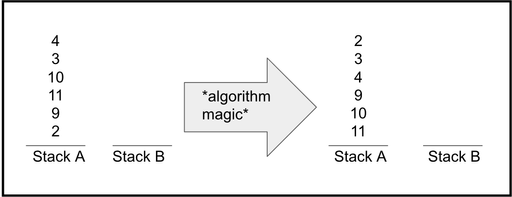
이번에 진행한 과제는 알고리즘에 대해서 공부 할 수 있는 push swap이였습니다
과제의 목표는 주어진 명령어들만을 사용하여 주어진 자료구조내에서 값들을 정렬하는것입니다
알고리즘이란...?
알고리즘(영어: algorithm), 셈법은 수학과 컴퓨터과학, 언어학 또는 엮인 분야에서 어떠한 문제를 해결하기 위해 정해진 일련의 절차이다. 계산을 실행하기 위한 단계적 절차를 의미하기도 한다. 즉, 문제 풀이에 필요한 계산절차 또는 처리과정의 순서를 뜻한다.
출처 : https://ko.wikipedia.org/wiki/%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98
라고 위키피디아에 적혀있네요
우리가 해야하는것은 '정렬', 정렬문제를 해결하기위한 절차들이 무엇들이 있는지 살펴보니...
선택정렬, 버블정렬, 병합정렬, 퀵정렬 등등...엄청 많았습니다
이번 과제에서 처음 알고리즘을 접하시는 분들은 '복잡도' 에 관해서 공부해보는것도 좋다고 생각합니다
알고리즘별 복잡도와 왜 그런 복잡도를 갖게되는지, 항상 그런 복잡도를 갖게되는지 등
그리고 이 복잡도를 표기할수있는 여러 방법들이 있는데 (big - o, big - Ω, big - Θ)
이중에서 가장 최악의 경우를 상정하는 big - o 표기법을 잘 살펴보시길 바랍니다

우리는 과제에서 스택 2개를 가지고 정렬을 하게되지만
우리가 알고있는 자료구조인 스택과는 살짝 다른 부분들이 존재합니다 (회전을 시킨다던지...최상위 값 두개를 스왑한다던지...)
그래서 진짜 스택이라고 생각하지 마시고 그냥 가상의 스택이라는 상황극이 주어졌다고 생각합시다
전 이 부분이 이해가 안가서 며칠동안 '내가 모르는 스택의 숨겨진 기능이 있나' 하고 검색하고다니는 삽질을 했습니다...
그래서 과제 진행에서 사용되는 자료구조는 주어진 명령어만 잘 수행할수있다면 어떤 자료구조를 구현해서 사용하던 상관없다고 생각합니다
저는 연결리스트를 쓰고싶었지만 이전 노드를 알수없다는 점이 불편했다는것과 마지막 노드를 가리키기위해 매번 탐색해야하는것이 번거로워서 '원형 양방향 연결리스트' 를 구현해봤습니다
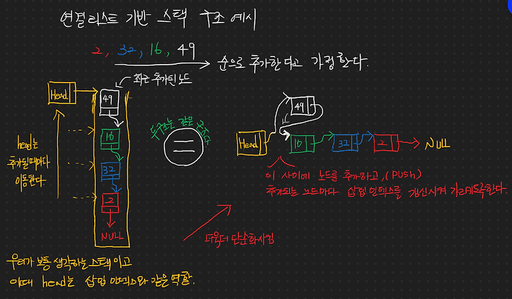
첨 써보면 좀 헛갈리긴 하지만 익숙해지면 매우 편합니다
또한 인터넷에 검색결과로 나오는 push swap에 사용되었던 정렬 알고리즘들은
실제 그 알고리즘들과는 살짝 다른, 모티브 삼기만한 알고리즘도 있다는것을 명심해두시기 바랍니다
전 이 부분에서도 다시한번 며칠동안 '내가 몰랐던 활용형이 있었나' 하고 검색하고 다니는 삽질을 했습니다....
평가를 다니면서 다양한 정렬 방식들을 봤지만 제가 가진 지능에서 가장 직관적으로 이해하고 구현할수있는건
Greedy 라 불리는 알고리즘이였습니다
Greedy(탐욕) 알고리즘이란...?
탐욕 알고리즘은 최적해를 구하는 데에 사용되는 근사적인 방법으로, 여러 경우 중 하나를 결정해야 할 때마다 그 순간에 최적이라고 생각되는 것을 선택해 나가는 방식으로 진행하여 최종적인 해답에 도달한다. 순간마다 하는 선택은 그 순간에 대해 지역적으로는 최적이지만, 그 선택들을 계속 수집하여 최종적(전역적)인 해답을 만들었다고 해서, 그것이 최적이라는 보장은 없다. 하지만 탐욕알고리즘을 적용할 수 있는 문제들은 지역적으로 최적이면서 전역적으로 최적인 문제들이다.
https://ko.wikipedia.org/wiki/%ED%83%90%EC%9A%95_%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98
우선 stack b로 정렬할 숫자들을 모두 보내놓고 stack b에 있는 숫자들을 순회하며
현재 stack a로 보낼때 가장 적게 명령어를 사용하는 친구를 골라내서 그 친구를 보내주는 방식입니다
여기서 명령들은 전부 회전과 관련되니 명령들이니 회전수를 구해주는것이
곧 명령수를 구해주는것과 같다고 할 수 있겠습니다
회전수 구하는 방법
1.
현재 노드가 stack_a에서 적절한 위치에 있으려면 어떤 노드가 top에 와야하는지 찾는다
2.
그 노드가 top까지 오기위한 stack_a의 회전수를 구한다
3.
현재 노드를 stack_b의 top으로 보내기위한 회전수를 구한다
stack_b를 한바퀴 돌때까지 위의 과정을 반복하며 가장 회전수가 적은 친구를 골라주면 됩니다
하지만 그리디 알고리즘의 치명적인 약점이 존재했으니...
탐욕 알고리즘이 잘 작동하는 문제는 대부분 탐욕스런 선택 조건(greedy choice property)과 최적 부분 구조 조건(optimal substructure)이라는 두 가지 조건이 만족된다. 탐욕스런 선택 조건은 앞의 선택이 이후의 선택에 영향을 주지 않는다는 것이며, 최적 부분 구조 조건은 문제에 대한 최적해가 부분문제에 대해서도 역시 최적해라는 것이다.
이러한 조건이 성립하지 않는 경우에는 탐욕 알고리즘은 최적해를 구하지 못한다.
https://ko.wikipedia.org/wiki/탐욕_알고리즘
쉽게 말해서 매순간의 최선의 선택이 전체적인 상황에서도 최선의 선택인가...?
이것이 지켜지지 않으면 최선의 선택을 보장 할 수 없다는것입니다
지금 당장 a라는 노드가 회전수가 가장 적다곤 하지만 b라는 노드를 먼저 보냄으로써
나머지 노드들의 전체적인 회전수가 줄어드는 경우도 분명 존재할것입니다
하지만 전 그런 방법까지 계산할수있는 실력이 아직 없으니 스터디 팀원의 힘을 빌려
다른 방법을 추가로 섞어보기로 합니다
최장 증가 부분 수열 LIS (Longest Increasing Subsequence)이란...?
컴퓨터 공학에서 최장 증가 부분 수열(Longest Increasing Subsequence) 문제는, 주어진 수열에서 오름차순으로 정렬된 가장 긴 부분수열을 찾는 문제이다. 여기서의 부분 수열은 연속적이거나 유일할 필요는 없다.
https://ko.wikipedia.org/wiki/%EC%B5%9C%EC%9E%A5_%EC%A6%9D%EA%B0%80_%EB%B6%80%EB%B6%84_%EC%88%98%EC%97%B4
쉽게 말해서 stack_b로 모든 숫자를 보내주는게 아니라 처음 입력받을때
어느정도 정렬되어있는 친구들을 따로 구해서 이 친구들은 stack_a에 그대로 놔두는 방법입니다
그리고 stack_b로 보낼때도 그냥 보내는게 아니라 들어온 숫자들중 평균에 있는 친구를 기준점 삼아
stack_b의 위 아래로 나누어 정렬을 한다면, stack_b에서 회전수가 적은 노드를 구할때
크기가 최대한 비슷비슷한 범위 안에서 먼저 탐색을 시도하게 되니 stack_a가 불필요하게 큰 회전을 할 필요가 없습니다
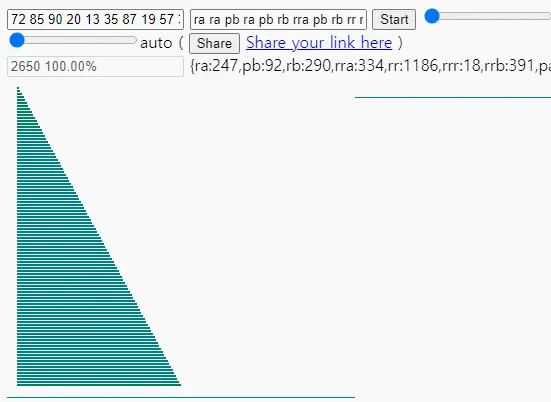
어째선지 거꾸로 stack_b에다가 정렬을 해버리는 모습이지만
기준점 없이 그냥 썡으로 정렬해버리면 이렇게 불필요한 회전을 너무 많이 해버립니다
명령어 수도 2600개가 넘어버리네요
그리고 기준점을 가지고 정렬을 해준다면
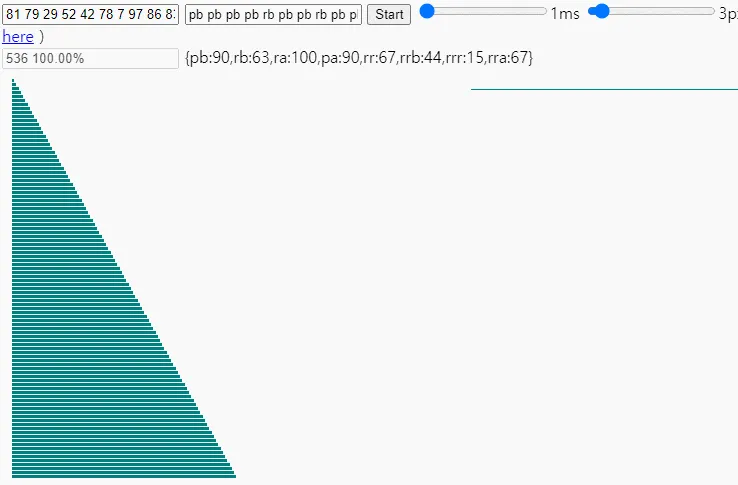
짠 이렇게 금방 끝나는 모습을 볼 수 있습니다
물론 위의 gif가 기준점 뿐만 아니라 산수를 실수한 부분도 있어서
불필요한 회전을 많이 하게 된것이기도 합니다 ㅎㅎ;
물론 입력값을 완전히 내림차순으로 넣어버리면 LIS가 아무런 힘을 못쓰겠죠....
하지만 평가표에서 요구하는 명령어수를 넘는 케이스가 나오자마자 바로 fail을 받아들이기보단
여러번 수행해보고 나온 명령어 수들을 평균잡아서 평가받는 쪽으로 디펜스를 해보시는게 좋다고 생각합니다
최악의 케이스가 항상 등장하는건 아니잖아요?
가장 최악의 케이스를 가지고 평가받느냐, 평균적인 케이스를 가지고 평가받느냐
이건 평가자와 피평가자 사이의 토론을 통해서 결정되어야 한다고 생각합니다
이 과제에서 했던 실수들
•
회전수 구하거나 합칠때 사칙연산 헛갈린것
•
값을 비교할때 조건이 비교적 간단하면 더 빠름 (이유는 모르겠습니다 전 디테일한게 좋을거같아서 디테일하게 했었는데 오히려 간단하게 수정하면서 명령어 수가 줄었습니다)
•
너무 많은 알고리즘을 섞지 말것 (처음에 LIS에 없는 숫자를 stack_b로 보내주는것도 그리디를 적용시켰지만 오히려 명령어 수가 폭발적으로 일어났습니다...)
참고할만한 자료들