

당신은 도커를 이용하여 서버를 운영하고 있다. 당분간 일이 생겨서 외부인에게 도커 실행 권한을 가진 계정을 맡겼다. 그러면 당신은 그 사람에게 루트 계정을 준 것과 다름 없다.
리눅스에서 컨테이너가 어떤 원리로 만들어지는 이해한다면 이 문제를 사전에 방지할 수 있다. 이 글이 문제 예방에 도움이 되기를 바란다.
도커로 관리할 수 있는 리눅스 컨테이너는 운영체제 수준의 가상화 기술로 리눅스 커널을 공유하면서 프로세스를 격리된 환경에서 실행하는 기술이다.
이 글은 아래 링크의 "김삼영님의 이게 돼요? 도커 없이 컨테이너 만들기"를 실습해보며 학습한 내용을 내 나름대로 재구성하여 작성하였다.


리눅스에서 간단한 컨테이너를 직접 만들기 위해 Cgroups, Namespace, 컨테이너 파일시스템을 실제 사용하고 설정해야한다. 그러면서 자원 할당, 격리, 파일시스템 구성 방법에 대해 알 수 있고 실제 리눅스 컨테이너의 동작 원리에 대해서도 이해할 수 있을 것이다.
이 글의 최종 목표는 2개의 리눅스 컨테이너를 만들어 통신시키고 여러 테스트를 통해 컨테이너의 완성을 확인하는 것이다.
자원이 잘 할당되었는지, 컨테이너의 각 요소들이 잘 격리되었는지 등을 직접 확인할 것이다.
컨테이너를 만들기 전에 위에서 말한 Cgroups, Namespace, 컨테이너 파일시스템에 대한 지식이 필요하므로 해당 지식들 부터 알아보자.
컨테이너를 만들기 위해 필요한 지식들
Cgroups - 컨테이너 자원 할당
Cgroups는 Control groups라는 의미로 리눅스에서 프로세스의 자원 할당량을 제어하는 도구다.
참고: https://kubernetes.io/docs/concepts/architecture/cgroups/
하나 또는 복수의 장치를 묶어서 그룹화하여 프로세스가 사용하는 리소스를 통제할 수 있다.
컨테이너를 만든다면 호스트의 자원을 너무 많이 사용하지 않도록 제어할 필요가 있다.
cgroups를 이용한다면 컨테이너 별로 자원을 분배하여 운용할 수 있다.
cgroups은 리눅스에서 파일시스템으로 관리할 수 있다.
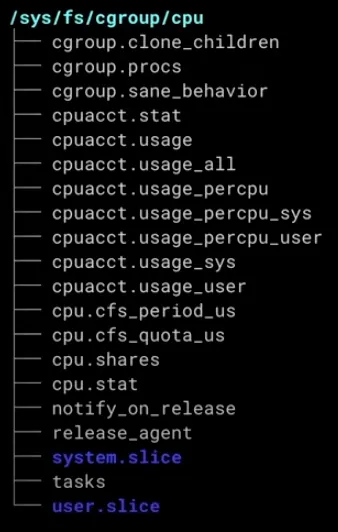
cgroup 설정하기
먼저 croups 설치를 진행하자. 그리고 설정 확인 테스트를 위한 stress 설치하자.
sudo -Es
apt install -y cgroup-tools
apt install -y stress
Plain Text
복사
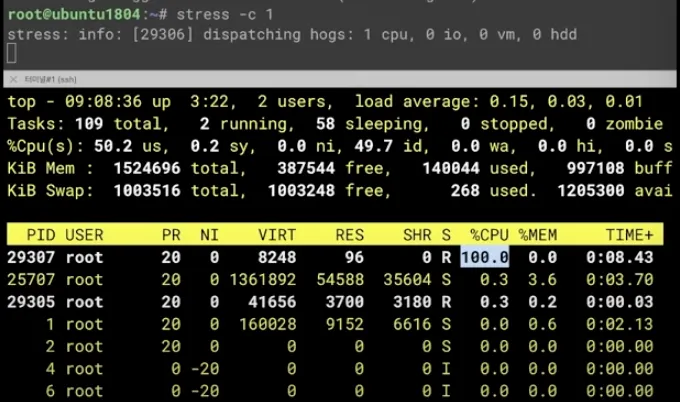
우선, croups 설정하지 않은 상태에서 stress -c 1을 실행해보자.
그리고 다른 터미널에서 top 명령어로 확인해보면 CPU 사용률 100%가 되는 것을 확인할 수 있다.
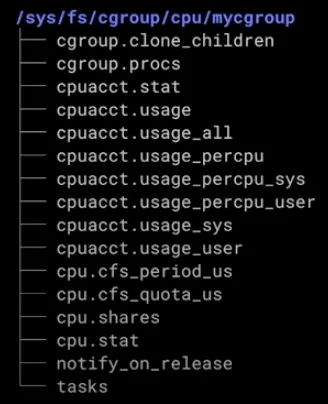
cgcreate로 mycgroup으로 cpu에 대한 cgroup을 생성해보자
cgcreate -a root -g cpu:mycgroup
tree /sys/fs/cgroup/cpu/mycgroup 으로 cgroup이 생성된 것을 확인할 수 있다.
memory에 대해서도 cgcreate -a root -g memory:mycgroup와 같이 cgroup 생성을 할 수 있다.
CPU 사용률 제어하기
/sys/fs/cgroup/cpu/mycgroup에 있는 cpu.cfs_period_us, cpu.cfs_quota_us 파일을 이용해서 CPU 사용률을 설정할 수 있다.
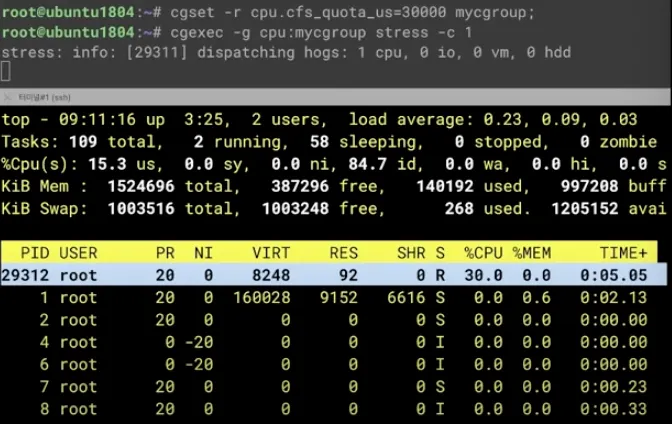
cgset으로 CPU 사용률을 30%로 설정하자
cgset -r cpu.cfs_quota_us=30000 mycgroup
이후 cgexec -g cpu:mycgroup stress -c 1 명령어로 mycgroup에서 에서 stress 테스트를 진행하자
호스트에서 top 명령어로 보면 CPU 사용률 30% 정도를 유지하는 것을 확인할 수 있다.
메모리 할당량 제어하기
/sys/fs/cgroup/memory/mycgroup에 있는 memory.limit_in_bytes 파일을 이용해서 메모리 할당량을 제어할 수 있다.
cgset으로 메모리 사용량을 200MB로 설정하자
cgset -r memory.limit_in_bytes=209715200 mycgroup
swap 메모리를 0으로 설정하여 디스크로 swap을 방지하자. 그래야 프로세스가 설정된 메모리 사용량을 넘으면 커널이 프로세스를 종료 시키는 것을 확인할 수 있다.
cgset -r memory.swappiness=0 mycgroup
다음과 같이 stress로 메모리 사용량을 점진적으로 늘리면서 테스트해보자
cgexec -g memory:mycgroup stress --vm 1 --vm-bytes 195M
cgexec -g memory:mycgroup stress --vm 1 --vm-bytes 196M
cgexec -g memory:mycgroup stress --vm 1 --vm-bytes 200M
Plain Text
복사
점점 200M에 가깝게 테스트하다보면 프로세스가 종료된다. 이는 호스트에서 dmesg 명령어를 통해 확인할 수 있다.
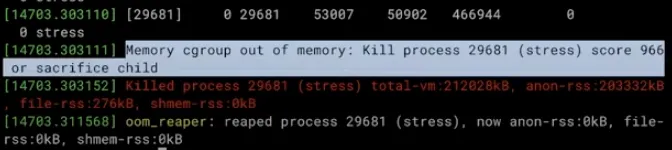
프로세스가 설정된 메모리 사용량을 넘어 커널이 종료시킨 것을 확인할 수 있다.
Namespace - 컨테이너 격리
Namespace는 리눅스에서 프로세스가 다른 프로세스들과 독립적으로 시스템의 자원을 사용할 수 있게하는 기능이다.
참고: https://www.baeldung.com/linux/list-namespaces
Namespace의 사용 방법은 unshare 명령어를 이용하는 것이다. 옵션으로 원하는 자원의 Namespace를 구분하여 설정할 수 있다.
(namespace 항목들: mount, uts, ipc, pid, neet, user)
Namespace 확인 방법은 2가지가 있다. ls -al로 /proc/{PID}/ns 를 확인하는 것이 첫번째고, lsns로 확인하는 것이 두번째다.
이 단락에서 Namespace 각 항목별 특징과 설정 방법들을 알아보자. 내가 생각하기에 중요하다고 생각하는 개념부터 차례대로 나열하였다. (그렇다고 아래있는 것들이 중요하지 않다는 것은 아니다!)
PID  ️
️
PID (Process ID) Numberspace를 격리하는 기능이다.
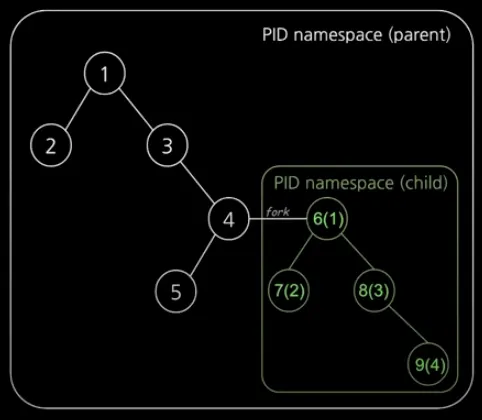
부모-자식 네임스페이스 중첩 구조이다. 이 중첩 구조로 인해 부모 Namespace에서는 자식 네임스페이스의 프로세스들을 모두 확인할 수 있다.
중첩 구조이므로 자식 Namespace는 PID 값이 2개가 있게된다. 즉, 부모 PID와 자기 자신 PID를 가진다.
PID에서는 pid 1 개념이 중요하므로 알아보자.
→ pid 1
pid 1은 init 프로세스로 1번 프로세스다. 커널이 생성한다. 운영체제는 커널과 유저 모드로 나눠져 있다.
커널 프로세스는 0번 프로세스다. 그 커널이 만든 1번 프로세스로 유저 모드에서 최상위 프로세스다.
나머지 유저 모드의 프로세스는 1번 프로세스의 자식 프로세스이다.
1번 프로세스의 특징은 다음과 같다.
•
시그널 처리 기능 (커널이 보내는 시그널을 자식 프로세스에게 전파)
•
좀비, 고아 프로세스 정리
•
1번 프로세스가 죽으면 시스템 패닉 -> reboot 으로만 해결 가능
→ 컨테이너 pid 1
컨테이너도 마찬가지로 pid 1을 가진다. unshare 할 때 fork 하여 자식 PID namespace의 pid 1 으로 실행한다. 즉, unshare 프로세스의 자식 프로세스로 포크해서 만들어진다.
그럼 컨테이너 안에서 실제 호스트의 pid 1 프로세스와 같은 기능을 한다. 컨테이너에서 시그널 처리와 좀비, 고아 프로세스 처리를 담당하게 된다.
그런데 문제는 컨테이너의 pid 1에서는 해당 기능을 구현하는 사람이 만들어줘야 한다는 것이다.
컨테이너에서 SIGTERM 과 같은 시그널을 보냈을 때 아무런 응답이 없는 경우라면, 해당 컨테이너의 pid 1번 프로세스에 시그널 처리 기능을 가지고 있지 않기 때문이다.
컨테이너의 pid 1 프로세스가 죽으면 컨테이너도 종료된다. 이렇게 해당 컨테이너의 라이프 사이클을 책임진다.
→ PID namespace 만들기
아래 명령어로 만들 수 있다.
unshare -fp --mount-proc /bin/sh
옵션 설명은 아래와 같다.
-p: pid namespace
-f: fork
--mount-proc: process file system을 mount
프로세스 확인
ps -ef
pid namespace 비교
lsns -t pid -p 1
Network ️
Network namespace는 컨테이너의 네트워크를 호스트와 격리하는 기능이다. 네트워크 스택을 격리해주는 것이다.
그리고 네트워크 가상화를 해준다. 그렇게 되면 네트워크 가상 인터페이스(장치)를 사용할 수 있다.
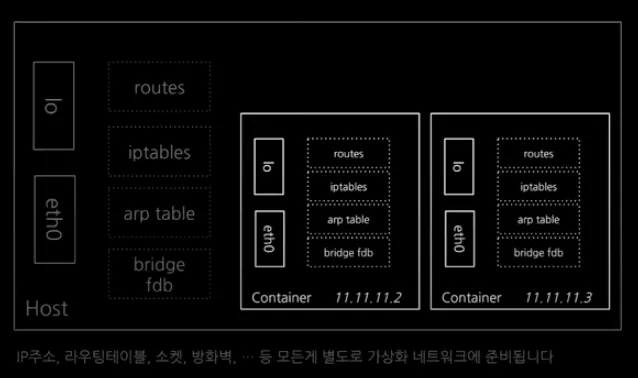
→ 네트워크 가상 인터페이스(장치)
격리된 Network namespace 안에서 물리 장치 취급하듯 다룰 수 있다.
하나의 컨테이너에서 다른 컨테이너로 LAN 선을 연결해서 통신을 구현할 수 있다.
만약 Network namespace가 삭제된다면, 거기에 연결되어 있던 가상 인터페이스도 같이 삭제된다. 만약 실제 물리 인터페이스라면 기존 Namespace로 복원된다.
→ Network namespace 1:1 통신해보기
여기서 2개의 Network namespace(RED/BLUE)를 만들어 가상의 통신선으로 연결해보자. 그리고 서로 통신이 되면 성공이다.
•
veth pair 설정 (가상의 통신선 설정)
◦
ip link add veth0 type veth peer name veth1
•
Network namespace 만들기
◦
RED network namespace
▪
ip netns add RED
◦
BLUE network namespace
▪
ip netns add BLUE
•
Network namespace에 가상 통신선 연결하기
◦
veth0 -> RED
▪
ip link set veth0 netns RED
◦
veth1 -> BLUE
▪
ip link set veth1 netns BLUE
•
통신선 연결된 곳에 전원 키기
◦
veth0 UP
▪
ip netns exec RED ip link set veth0 up
◦
veth1 UP
▪
ip netns exec BLUE ip link set veth1 up
•
통신하기 위해 IP 부여
◦
veth0 IP 설정
▪
ip netns exec RED ip addr add 11.11.11.2/24 dev veth0
◦
veth1 IP 설정
▪
ip netns exec BLUE ip addr add 11.11.11.2/24 dev veth1
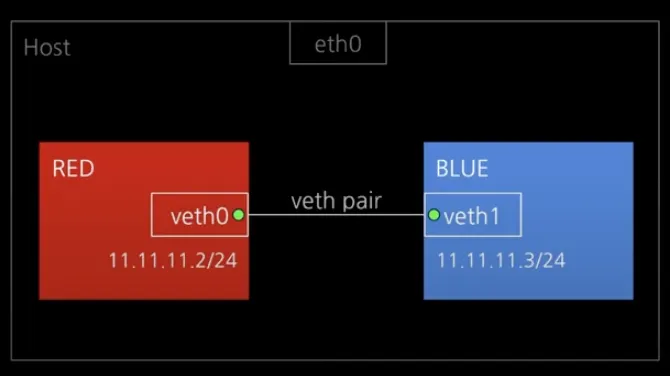
여기까지 하면 RED/BLUE 준비 완료다.
이제 Network namespace에 직접 들어가서 확인해보자.
Network namespace를 만들면 /var/run/netns 안에 만들어진 namespace 들을 볼 수 있다
ls /var/run/netns 로 확인해보자.
nsenter 명령어를 통해 원하는 Network namespace 내부로 진입할 수 있다.
nsenter --net=/var/run/netns/{NS명}
nsenter 네임스페이스 진입
--net: 네트워크 네임스페이스
nsenter --net=/var/run/netns/RED로 진입하여 확인하면 다음과 같다.
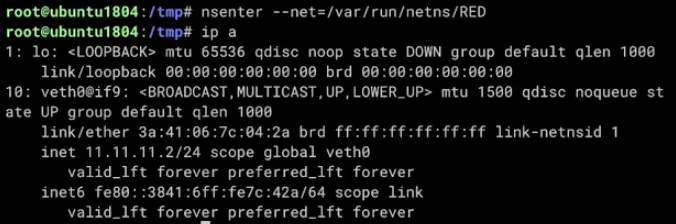
ip 명령어로 호스트와 직접 비교하면 다음과 같다.
이제 ping 명령어를 이용해서 통신이 되는지 테스트를 해보자.
RED -> BLUE
in RED
ping 11.11.11.3
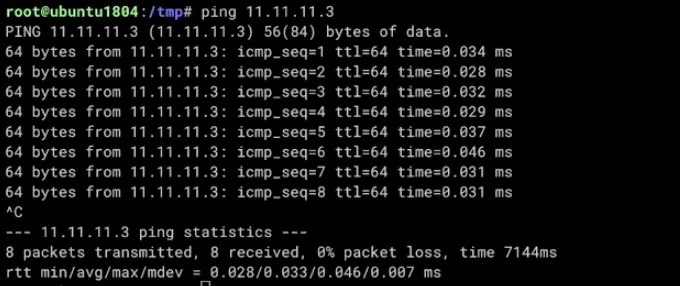
in BLUE
tcpdump -li veth1

잘 통신이 되는 것을 확인할 수 있다.
→ Network namespace 삭제
네트워크 네임스페이스를 삭제하기 위해서는 우선 exit으로 빠져나오자.
ip netns del RED 명령어로 삭제할 수 있다.
ls /var/run/netns 로 삭제됐는지 확인할 수 있다.
ip netns로도 확인이 가능하다.
User ️
User namespace로 UID/GID Numberspace를 격리할 수 있다. 해당 기능으로 컨테이너의 루트 권한 문제를 해결할 수 있다.
User namespace 역시 PID namespace와 마찬가지로 부모-자식 네임스페이스의 중첩 구조를 가진다. UID/GID remap을 통해 중첩 구조를 구현한다. 프로세스가 해당 파일을 사용할 수 있는지 UID/GID 비교를 하고 권한 결정할 때 사용된다.
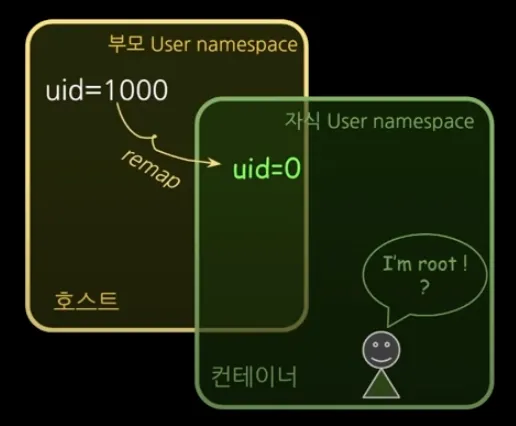
→ Docker의 보안 취약점: docker 권한을 준 것은 사실 root 권한을 준 것과 같다.
일반 계정에서 도커를 사용해보자. 우선 일반 계정에 도커 권한을 부여하자
sudo usermod -aG docker {일반 계정명}
설정 후 터미널 재접속
일반계정으로 실행해보자
docker run -it ubuntu /bin/sh
도커로 만든 컨테이너에서 root 권한을 가진다. 도커로 실행한 컨테이너 안의 root가 실제 호스트에서도 root인지 확인을 해보자
호스트에서 ps -ef | grep "/bin/sh" 로 확인하면 root로 실행된 것을 볼 수 있다.
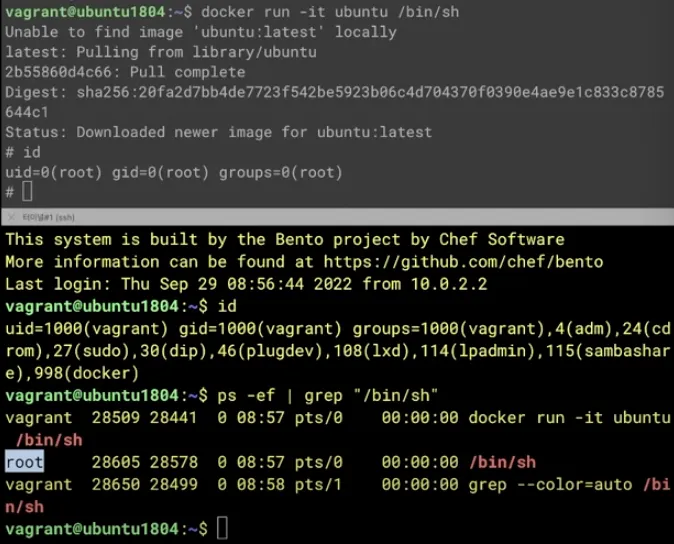
마지막으로 한 번 더 확인하기 위해 컨테이너와 호스트의 user namespace도 비교해보자
readlink /proc/$$/ns/user
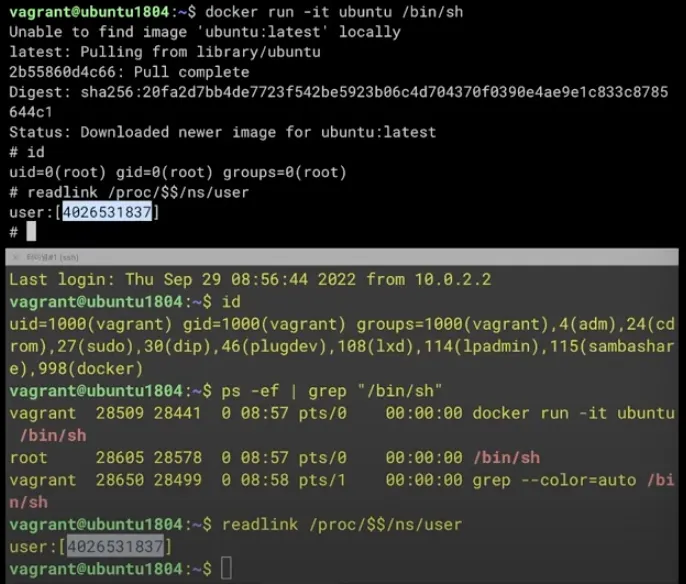
확인 결과 동일한 namespace인 것을 알 수 있다. 컨테이너에서의 root가 실제 호스트에서도 root 권한을 가진다는 것을 의미한다.
일반계정으로 도커를 실행한 이유가 root 계정을 함부러 이용하지 못하기 위한 의도이므로 이 부분은 도커의 보안 취약점이라고 할 수 있다.
도커로 시스템 주요 볼륨들을 마운트해서 컨테이너 기동을 한다면 루트 권한으로 접근이 가능하기 때문에 이는 보안상 큰 문제가 될 수 있다.
도커가 이런 취약점을 가지게 된 배경으로는 도커 초창기 원할한 도구 제공을 위해 루트 권한을 이용했기 때문이다. 루트 권한을 이용하면 권한 문제의 제약없이 패키지 인스톨과 시스템 리소스를 이용하여 빠르게 제공이 가능하기 때문이다.
→ (Docker와 다르게) User namespace 격리하기
unshare -U --map-root-user /bin/sh
-U: user namespace isolation(격리)
--map-root-user: user id를 remap해서 root 유저 생성
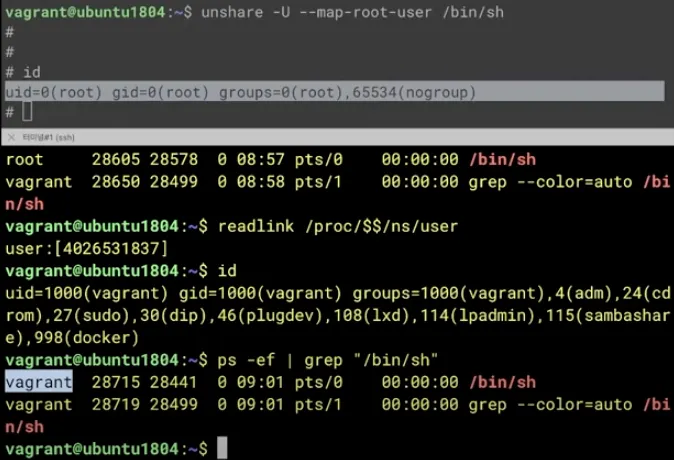
앞에 도커에서와 마찬가지로 컨테이너와 호스트에서 계정을 비교해보자
호스트에서 ps -ef | grep "/bin/sh" 을 이용하면 일반 계정으로 실행한 것을 확인할 수 있다.
User namespace도 비교해보면 다른 것을 볼 수 있다.
readlink /proc/$$/ns/user
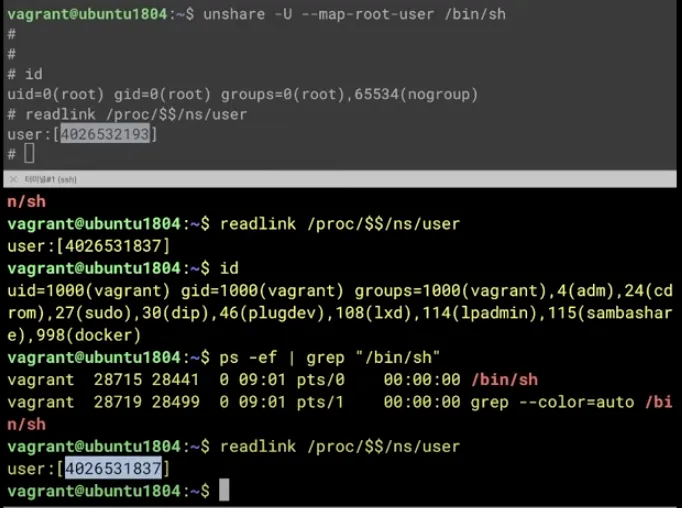
이는 remap을 통해서 컨테이너 안에서만 root 계정으로 보인다는 의미이다. 호스트에서는 일반 계정으로 실행한 것과 같다.
컨테이너 내부 자원들에 대해서는 root 권한을 가지고 다룰 수 있지만, 볼륨을 통해 호스트의 자원을 이용한다면 그 컨테이너를 실행한 일반 계정으로 다룰 것이다.
→ Docker로도 User namespace 격리하고 싶다면?
다행히 도커 v1.10+에서 UID/GID를 Remap 하는 기능을 추가해줬다.
하지만 따로 옵션을 넣어 설정을 하지 않는다면 기본적으로 remap을 하지 않아 실제 호스트의 root 권한을 가지게 된다.
해당 옵션은 -uroot 옵션으로 아래와 같이 실행하면 된다고 한다.
예시:
docker run -uroot -it -p 3000:3000 -v "$(pwd):/home/project:cached" theiaide/theia:next
Plain Text
복사
docker daemon으로 설정하는 것은 아래 링크를 참고하자.
https://docs.docker.com/engine/security/userns-remap/
Mount
Mount namespace는 마운트 포인트 격리하는 기능이다. unshare -m 으로 설정할 수 있다.
최초의 namespace이기도 한데, pivot_root로 루프 파일시스템 변경 시에 호스트에 영향이 가는 것을 막기위해 만들어졌다.
이후 단락인 컨테이너 루트 파일시스템 구성과 레이어 구성 쪽에서 중요하게 다뤄진다. 해당 단락에서 구체적으로 알아보자.
IPC
IPC(Inter-Process Communication) namespace를 설정하여 해당 namespace를 공유하는 프로세스 끼리만 IPC 통신을 할 수 있게해주는 기능이다.
IPC를 하기 위해 Shared Memory, Pipe, Message Queue 등을 이용하는데 해당 기능을 격리하는데 사용한다.
unshare -i를 통해 설정할 수 있다.
UTS
UTS namespace는 호스트명(hostname)을 격리하는 기능이다.
UTS는 Unix Time Sharing의 약자로 서버를 나눠쓴다는 의미를 담고 있다.
호스트명을 바꾸어 서버를 나눠 쓸 때 사용한다.
UTS 격리, 확인
unshare -u
lsns -p $$
호스트 변경, 확인
hostname to_change
hostname
pivot_root와 Mount namespace - 컨테이너 루트 파일시스템 구성하기
여기서 컨테이너 프로세스가 필요한 파일들을 패키징하고 파일 시스템을 호스트와 격리하는 방법을 알아보자.
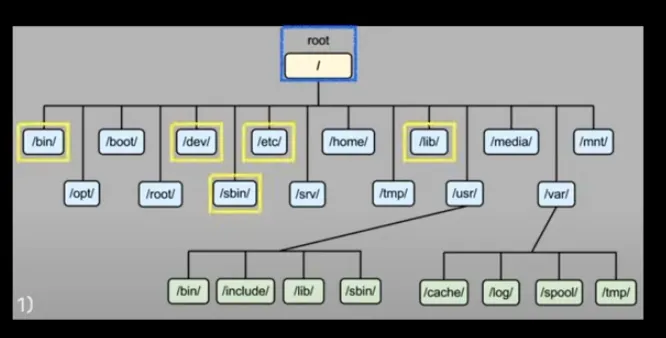
컨테이너 프로세스를 호스트와 격리하기 위해서 컨테이너 자체적인 루트 파일시스템을 구성할 필요가 있다.
그러기 위해서는 컨테이너의 루트가 될 디렉토리에 필요한 바이너리와 의존성 라이브러리들을 복사하여 패키징 해야한다.
그리고 컨테이너 프로세스 입장에서 해당 디렉토리를 실제로 루트 파일시스템으로 변경하도록 해야한다.
여기서 루트 파일시스템을 변경할 때 쓰는 명령어가 pivot_root다.
pivot_root는 루트 파일시스템을 피봇하여 원하는 디렉토리를 루트 디렉토리로 설정할 수 있는 도구다.
참고: https://man7.org/linux/man-pages/man8/pivot_root.8.html
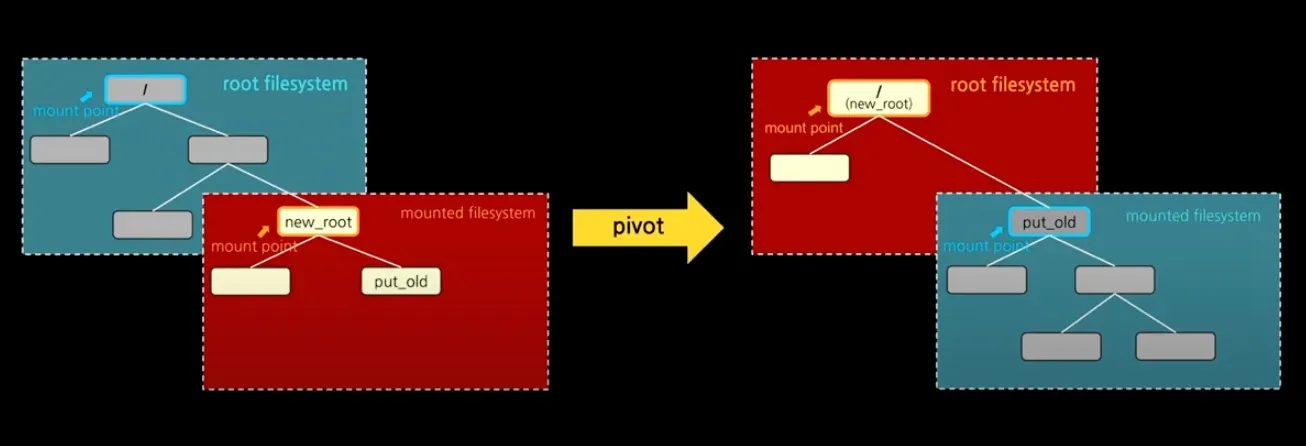
하지만 pivot_root를 바로 사용하면 호스트에도 영향이 간다. 여기서 필요한 것이 Mount namespace다.
Mount namespace로 Mount point 격리
Mount namespace는 Mount point를 격리할 수 있는 기능이다.
위에서 Mount namespace를 간략하게 설명했다. 위에서 간략하게 설명한 것 치고는 상당히 중요한 역할을 한다.
Mount namespace를 이용하여 컨테이너 프로세스에서만 Mount point 변경이 보이게 할 수 있다.
그러면 컨테이너 프로세스에서 pivot_root를 이용해 루트 파일시스템이 변경되어도 실제 호스트에는 영향이 가지 않는다.
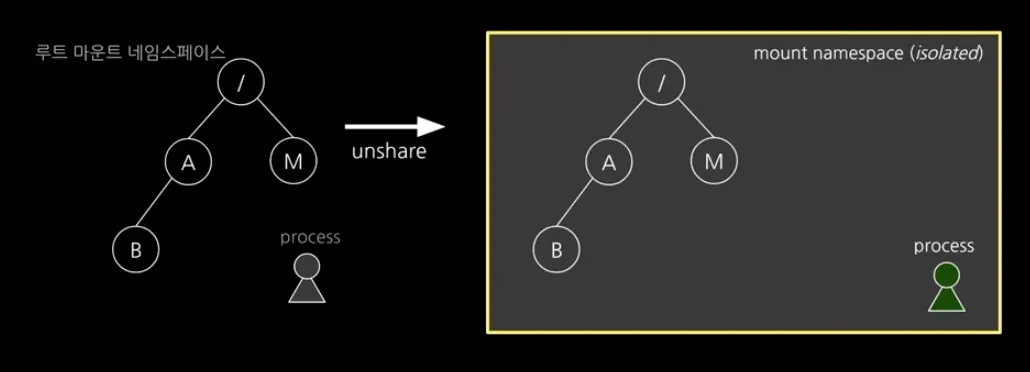
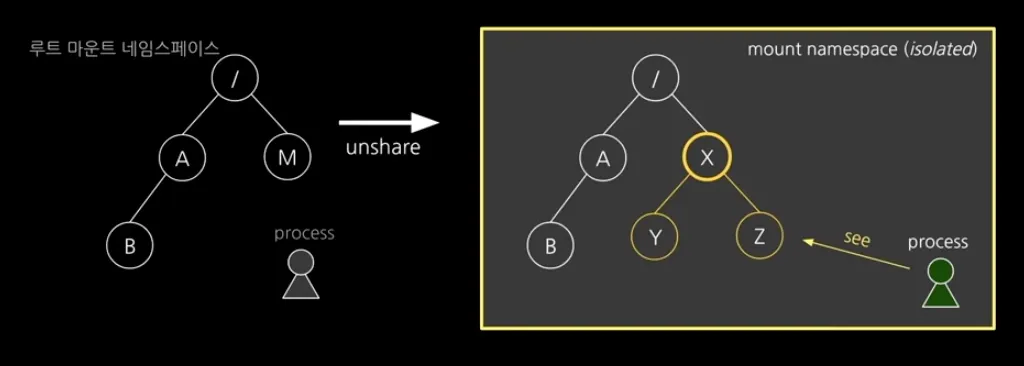
그럼 이제 Mount namespace로 마운트 환경을 격리한 다음, 호스트에 영향을 주지 않고 pivot_root로 컨테이너 프로세스의 루트 디렉토리를 변경하는 방법을 알아보자.
unshare --mount /bin/sh
unshare에 --mount 옵션으로 mount 환경을 격리하여 프로세스를 실행한다.
뒤에 명령어는 프로세스로 실행할 명령어이다.
우선 부모 프로세스의 마운트된 네임스페이스 정보를 복사해서 자식 네임스페이스로 만들게 된다.
df -h을 이용해서 호스트와 컨테이너(자식 프로세스)에서 각각 확인해보면 mount 정보가 같은 것을 확인할 수 있다.
하지만 부모 프로세스와 unshare로 실행된 자식 프로세스(컨테이너)의 Mount namespace가 분리 되었다.
자식 프로세스에서 일어나는 mount 변경은 부모 프로세스에 영향이 가지 않는다.
즉, 컨테이너에서 일어나는 pivot_root가 호스트에 영향이 가지 않는다.
확인을 위해 new_root 디렉토리를 만들고 mount 해보자.
mkdir new_rootmount -t tmpfs none new_root
컨테이너와 호스트에서 각각 마운트 정보를 확인해보면 다른 것을 확인할 수 있다.
mount | grep new_root
컨테이너에서는 new_root의 mount 정보가 인식 되지만 호스트에서는 new_root의 mount 정보가 보이지 않는다.
그렇게 되면 컨테이너에서 new_root에 파일을 복사해도 호스트에서는 보이지 않는다.
이렇게 Mount namespace로 컨테이너와 호스트의 마운트 환경을 분리했다. 이제 pivot_root를 사용할 환경을 만든 것이다.
pivot_root로 해당 위치를 루트 파일시스템으로 세팅
컨테이너에서 pivot_root를 사용하면 기존 루트 파일시스템을 원하는 디렉토리로 설정하여 옮기고 루트 디렉토리를 새로 설정할 수 있다.
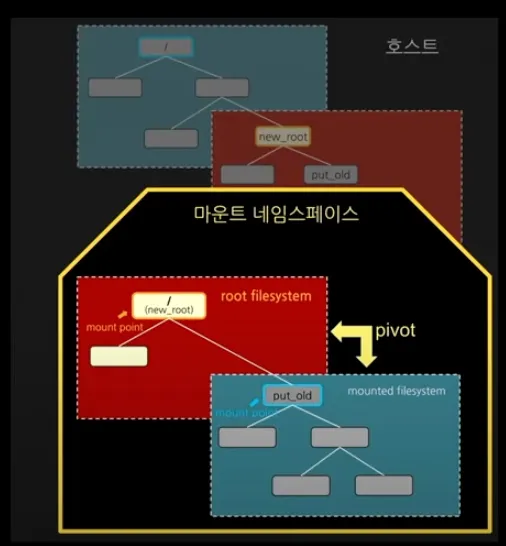
우선 기존 파일 시스템이 부착될 위치 폴더를 만들어 주자.
mkdir new_root/put_old
그리고 새로운 루트 파일 시스템이 될 위치로 이동하자.
pivot_root는 컨테이너 프로세스 입장에서 실제로 파일 시스템을 바꿔버리는 것이기 때문에 새로 루트 디렉토리가 될 위치에서 실행해야 한다.
cd new_root
현재 위치를 새로 루트 디렉토리가 될 곳으로 설정하고 기존 루트 파일 시스템을 넣을 위치를 설정해서 아래와 같이 실행하자.
pivot_root . put_old
그리고 ls /로 확인해보면 기존의 루트 파일시스템과 다른 것을 확인할 수 있다. cd ../../ 등으로 나가보려해도 나가지지 않는다.
ls put_old 확인하면 호스트의 루트 파일 시스템 보이고 실제 호스트에서 확인해보면 같은 것을 알 수 있다.
여기서 put_old 폴더를 삭제하면 아예 host의 파일 시스템을 사용할 수 없게 만들 수 있다.
이렇게 성공적으로 컨테이너의 루트 파일 시스템을 구성했다.
요약하면, Mount namespace로 마운트 환경을 호스트와 격리하고 pivot_root를 이용해서 원하는 디렉토리 위치로 루트 파일 시스템을 변경하였다.
Overlay Mount - 컨테이너 레이어 구성하기
위에서 원하는 디렉토리에 필요한 파일들을 패키징하고 자체 루트 파일시스템을 구성하였다.
여기서 한가지 해결할게 더 있다.
만약 여러 종류의 컨테이너를 만들기 위해서 여러개의 디렉토리에 필요한 파일들을 각자 패키징한다고 가정하자.
그러면 각 컨테이너 프로세스가 필요한 바이너리나 라이브러리들이 같아도 각자 디렉토리에 패키징해야한다.
이렇게되면 똑같은 기능을 하는 파일들이 중복으로 저장된다.
참으로 손실이 아닐 수 없다.
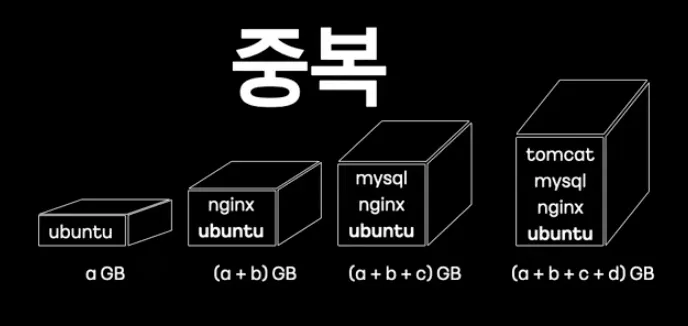
중복되는 파일들을 각자 패키징 하는게 아니라 한 곳에만 패키징하여 이를 여러 컨테이너가 사용하도록 해야한다.
중복 문제를 해결하여 컨테이너를 구성하기 위해 여러 이미지를 하나로 마운트할 필요가 있다.
중복 패키지 문제를 해결하기 위해 나온 것이 바로 'Overlay Mount' 기능이다.
패키징된 디렉토리들을 계층적으로 쌓아 최종적으로 마치 하나의 디렉토리 안에 패키징 되어 있는 것처럼 보이게 만드는 것이다.
이를 Overlay File System이라고 한다.
Overlay File System의 구조
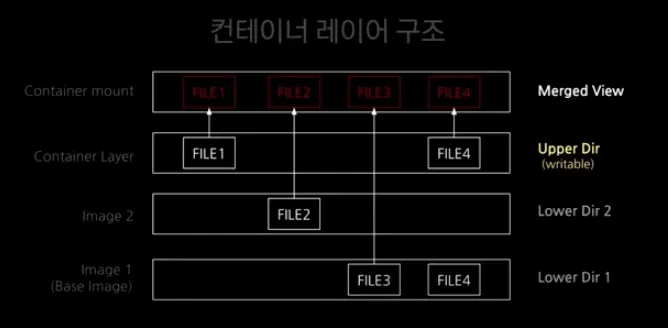
Overlay File System은 다음과 같이 아래에서 부터 Lower Layer, Upper Layer, Merged View로 구성되어 있다.
→ Lower Layer
여기서 Lower Layer는 여러개일 수 있다.
즉, 도커 컨테이너를 사용할 때 pull로 가져오는 이미지가 여기에 해당한다.
Lower Layer는 Read Only 이므로 Overlay File System을 가진 컨테이너에서 해당 파일을 변경해도 영향을 받지 않는다.
→ Upper Layer
Upper Layer는 Writable으로 실제 컨테이너에서 변경한 부분들이 반영되는 곳이다.
이 Upper Layer를 이용해서 CoW(Copy-on-Write)가 가능하다.
즉, 원본 유지가 가능하다는 의미다.
컨테이너에서 Lower Layer에 해당하는 파일을 변경했을 때, Upper Layer에서 기록하여 원본이 수정되지 않도록 해준다.
→ Merged View
Merged View는 Lower Layer와 Upper Layer가 중첩된 파일시스템이다.
최종적으로 컨테이너에서 확인할 수 있는 전체 파일 시스템이 Merged View다.
Overlay File System을 구성하는 방법
여기서 구성해 볼 Overlay File System은 다음과 같다.
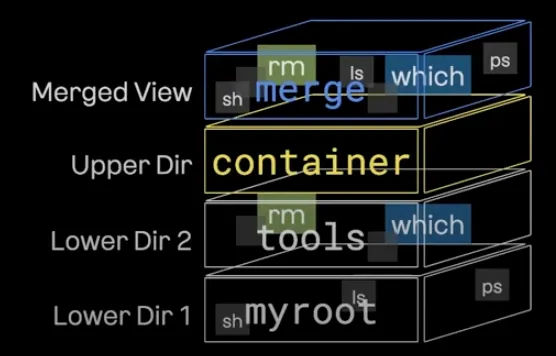
구성
Merged View : merge
Upper Dir : container
Lower Dir 2 : tools
Lower Dir 1 : myroot
즉, tools와 myroot를 이미지 레이어로 구성한 컨테이너를 만드는 것이다.
tools과 myroot를 다음과 같이 패키징하여 준비가 된 상태다.
이제 오버레이 마운트 할 경로를 만들어주자.
mkdir -p rootfs/{container,work,merge}
여기서 만든 각 디렉토리 역할을 설명하면 다음과 같다.
•
container
◦
upper layer로 변경 사항이 반영되는 영역
•
merge
◦
merged View로 실제 overlay mount point 영역 ️
️•
work
◦
실제 컨테이너 조회할 때는 보이지 않는다.
◦
upper layer의 atomic한 write update를 보장하기 위해서 존재
다음과 같은 명령어로 각 layer 정보를 넣어 Overlay Mount를 해주자.
mount -t overlay overlay -o lowerdir=tools:myroot,upperdir=rootfs/container,workdir=rootfs/work rootfs/merge
tree -L 2 merge로 확인해보면 각 layer들이 중첩되어 보이는 것을 알 수 있다.
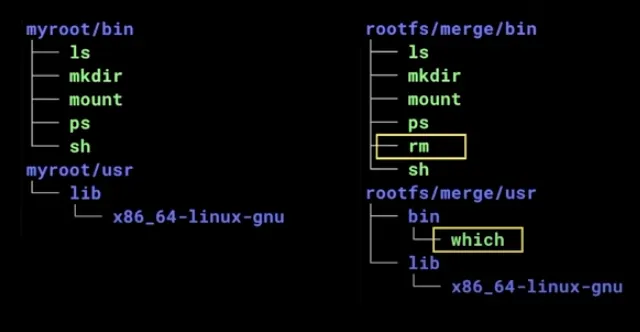
myroot와 merge를 확인해보고 비교해볼 수도 있다.
tree -L 2 myroot/{bin,user}
tree -L 2 rootfs/merge/{bin,user}
컨테이너 내에서 파일을 변경하여 CoW가 보장되는지 확인해보자
미리 myroot의 dumb 파일을 만들어 놓았다.
merge에서 dumb를 삭제해보자.
그리고 myroot를 확인해보면 여전히 dumb가 남아있는 것을 볼 수 있다.
container를 확인해보면 dumb가 노란색 표시가 되어 생성된 것을 확인할 수 있다.
이는 write out이라는 의미로 '삭제 마킹'을 한 것이다.
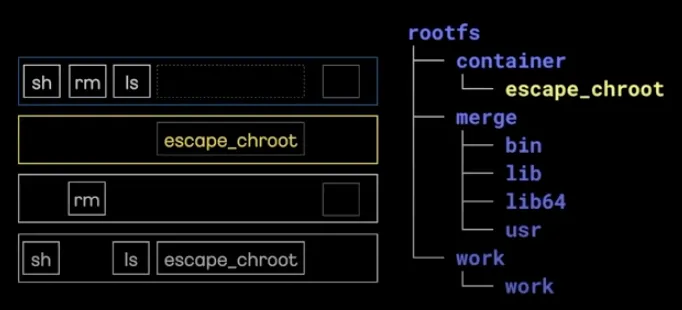
이렇게 Upper Layer에서 변경된 정보를 관리해 주어 '원본 보장'을 가능케한다.
직접 컨테이너 만들기
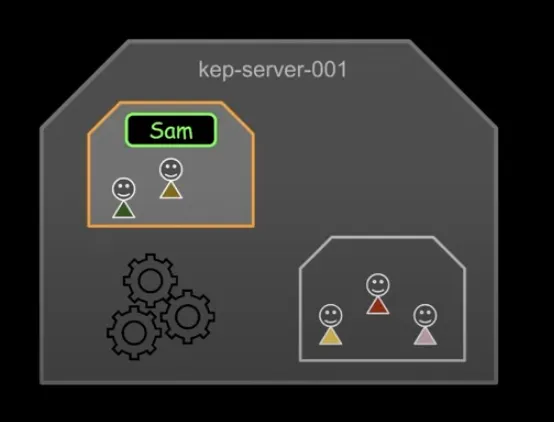
이제 위에서 알게된 지식들로 직접 컨테이너를 만들어보자.
여기서 목표는 아래 이미지와 같다.
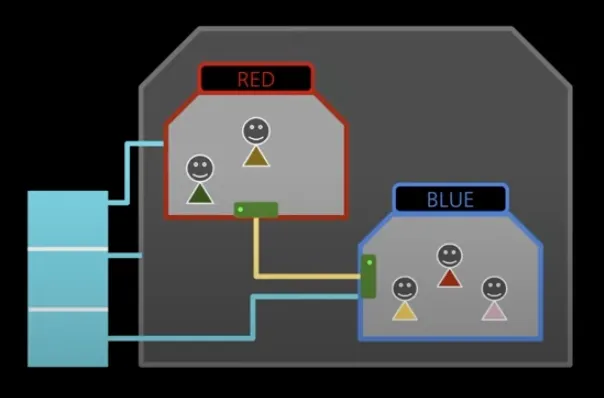
RED와 BLUE 컨테이너를 구성하여 네트워크 연결을 통해 서로 통신하는 것이 목표다.
각 컨테이너는 Cgroups로 자원이 자원이 할당된다.
그리고 위에서 사용했던 tools, myroot를 이미지로 사용할 것이다.
tools는 다음과 같은 기능을 가지고 있다.
ping: 컨테이너 통신 테스트
stress: 컨테이너 부하 테스트
hostname: 호스트네임 변경
umount: put_old 제거
컨테이너 네트워크 구성
Network namespace로 컨테이너를 만들어주자
ip netns add REDip netns add BLUE
가상 네트워크 인터페이스를 만들어 컨테이너끼리 연결해주자.
네트워크 인터페이스를 add 하고 바로 netns 옵션을 넣으면 바로 해당 컨테이너에 연결할 수 있다.
ip link add veth0 netns RED type veth peer name veth1 netns BLUE
아래 명령어들을 입력하여 각각 veth0과 veth1 이 보이면 잘 연결된 것이다.
ip netns exec RED ip lip netns exec BLUE ip l
IP를 부여하고 전원을 켜주자
RED 본체
ip netns exec RED ip addr add dev veth0 11.11.11.2/24ip netns exec RED ip link set veth0 up
BLUE 본체
ip netns exec BLUE ip addr add dev veth1 11.11.11.3/24ip netns exec BLUE ip link set veth1 up
이제 컨테이너 네트워크 구성을 완료하였다.
ls /var/run/netns로 파일로 관리되는 것을 확인할 수 있다.
아직 프로세스 형태는 아니고 파일로 네트워크 정보만 관리되고 있는 상태다.
RED 컨테이너 만들기
RED 컨테이너 자원 할당
자원을 할당 위해 RED Cgroups를 생성하자
Cgroups tools를 안 쓰고 Croups 파일 시스템을 직접 제어해서 설정할 수도 있다. 여기서는 그 방법으로 진행해보자.
mkdir /sys/fs/cgroup/cpu/redmkdir /sys/fs/cgroup/memory/red
ls /sys/fs/cgroup/cpu/red로 이미 cpu 관련 파일들이 만들어진 것을 확인할 수 있다.
이것은 커널이 만들어준다. 메모리도 마찬가지다.
만들어진 Cgroups에 자원 할당량을 설정해보자
echo 40000 > /sys/fs/cgroup/cpu/red/cpu.cfs_quota_us; # CPU 40% 제한
echo 209715200 > /sys/fs/cgroup/memory/red/memory.limit_in_bytes; # 메모리 200MB 제한
echo 0 > /sys/fs/cgroup/memory/red/memory.swappiness; # 메모리 swap off 설정
Plain Text
복사
CPU 사용률을 40%로 설정하였다.
cpu.cfs_period_us를 확인해보면 100000 인 것을 알 수 있다. 그러므로 cpu.cfs_quota_us를 40000으로 설정하면 비율 상 40%가 된다.
메모리 사용량을 200MB로 제한하도록 설정하였다.
또한, swap off를 설정하여 메모리 부족 시에 커널이 프로세스를 종료 시키도록 하였다.
RED 컨테이너 격리
다음과 같이 unshare 뒤에 옵션들을 넣어 namespace들을 설정해주었다.
unshare -m -u -i -fp nsenter --net=/var/run/netns/RED /bin/sh
옵션 상세 설명은 다음과 같다.
•
m: Mount namespace
u: UPS namespace
i: IPC namespace
fp: fork해서 PID namespace
nsenter --net=/var/run/netns/RED: Network namespace
/bin/sh: 실행할 컨테이너 프로세스
명령어를 실행하면 격리된 상태로 RED 컨테이너를 만들 수 있다.
하지만 아직 cgroup이 제한되지 않은 상태다.
다음과 같이 입력해서 cgroup을 제한하자.
echo "1" > /sys/fs/cgroup/cpu/red/cgroup.procs;
echo "1" > /sys/fs/cgroup/memory/red/cgroup.procs;
Plain Text
복사
1번 프로세스로 설정한 이유는 현재 RED 컨테이너는 격리된 상태이기 때문이다.
방금 실행한 프로세스는 컨테이너 안에서 1번이다.
RED 컨테이너 파일시스템
Overlay File System으로 pivot_root를 해줘야 한다.
→ Overlay Mount
우선, RED 컨테이너의 Overlay File System을 위한 디렉토리를 구성해주자.
mkdir /redfs;
mkdir /redfs/container;
mkdir /redfs/work;
mkdir /redfs/merge;
Plain Text
복사
그리고 다음 명령어로 Overlay Mount를 진행하자.
mount -t overlay overlay -o lowerdir=/tmp/tools:/tmp/myroot,upperdir=/redfs/container,workdir=/redfs/work /redfs/merge
Plain Text
복사
tree /redfs/merge 로 확인하면 Overlay File System이 제대로 만들어 진 것을 볼 수 있다.
→ pivot_root
Overlay Mount를 통해 새로운 루트 파일시스템이 될 곳을 구축했으니 이제 put_old를 만들어 pivot_root를 준비하자.
put_old는 Mount point가 될 merge 디렉토리 안에 만들어야 한다는 것을 유의하자.
mkdir -p /redfs/merge/put_old
이제 merge 디렉토리로 이동해서 pivot_root를 진행하자.
cd /redfs/merge
pivot_root . put_old;
Plain Text
복사
루트 디렉토리와 put_old를 확인하면 pivot_root가 성공적으로 실행된 것을 확인할 수 있다.
이제 put_old를 제거하자. put_old는 반드시 제거해야한다.
호스트의 루트 파일시스템이 부착되어 있기 때문이다. 남겨두면 보안 상 위험이 된다.
그러기 위해서는 put_old를 umount 해줘야 한다. umount를 위해서 우선 proc을 mount 해줘야 하니 다음 명령어들을 차례대로 수행하자.
mount -t proc proc /proc;
umount -l put_old;
rm -rf put_old;
Plain Text
복사
이렇게 하면 깔끔하게 호스트의 파일 시스템과 격리될 수 있다.
RED 컨테이너 완성
이제 RED 컨테이너를 완성했다. 다음과 같이 RED 컨테이너를 확인해보자.
RED 프로세스를 확인하자
ps -ef
/bin/sh이 PID 1임을 확인할 수 있다.
RED 호스트네임을 변경하자
hostname RED
여기까지 하면 RED 컨테이너를 만든 것이다.
BLUE 컨테이너 만들기
이제 BLUE 컨테이너를 만들어야 하는데 RED에서 한 것과 똑같이 해주면 된다.
위에서 RED 컨테이너 구성하는 방법을 알아보았으니 직접 BLUE 컨테이너를 구성해보자.
내용이 중복되기 때문에 이 글에서는 BLUE 컨테이너도 이미 만들었다고 가정하겠다.
컨테이너 테스트
RED/BLUE 통신 테스트
RED -> BLUE 로 ping test
ping 11.11.11.3
Plain Text
복사
stress 테스트
→ RED CPU 리소스 확인
in RED
stress -c 1
Plain Text
복사
in 호스트
top
Plain Text
복사
cpu 사용륭 40% 아래에서 스로틀링이 걸리는 것을 확인할 수 있다.
→ RED 메모리 리소스 확인
RED 컨테이너에서 메모리 할당량을 점차 200MB에 가까워지도록 테스트 하자
in RED
stress --vm 1 --vm-bytes 195M
stress --vm 1 --vm-bytes 196M
stress --vm 1 --vm-bytes 200M
Plain Text
복사
in 호스트
top
Plain Text
복사
메모리 할당량을 점점 늘려가다 보면 어느 지점에서 프로세스가 종료되는 것을 확인할 수 있다.
호스트에서 dmesg로 확인해보면 memory cgroup이 사용량을 넘겨서 커널이 해당 프로세스를 종료시킨 것을 볼 수 있다.



