


10-1. 단순한 정렬 알고리즘
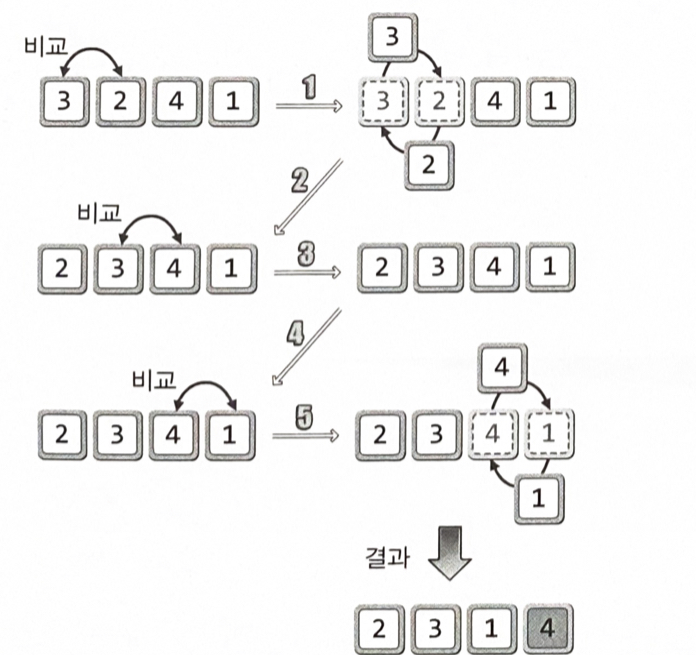
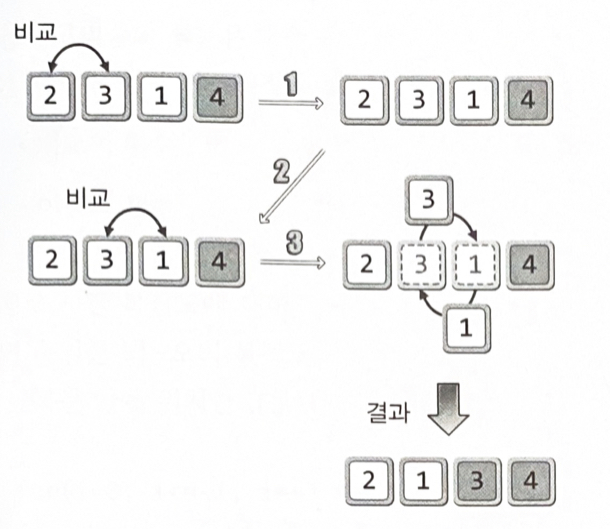
버블 정렬(Bubble Sort) : 이해와 구현
)
)
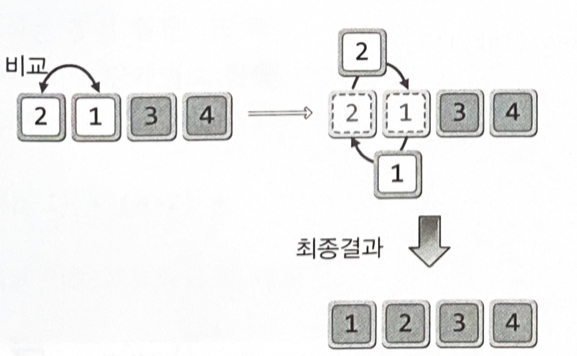
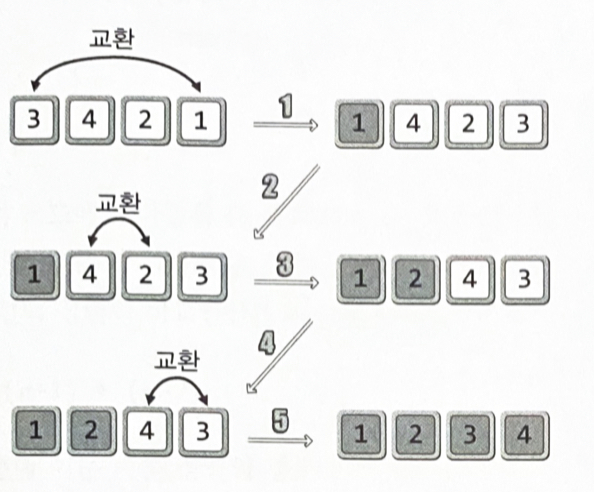
인접한 두 개의 데이터를 비교해가면서 정렬을 진행하는 방식
정렬의 우선순위가 가장 낮은, 제일 큰 값을 맨 뒤로 보내기
void BubbleSort(int arr[], int n)
{
int i, j;
int temp;
for(i = 0; i < n-1; i++)
{
for(j = 0; j < n-1-i; j++)
{
if(arr[j] > arr[j+1])
{
//데이터의 교환
temp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = temp;
}
}
}
}
Plain Text
복사
버블 정렬(Bubble Sort) : 성능 평가
•
비교의 횟수 : 두 데이터간의 비교연산의 횟수
버블 정렬에서 데이터의 수가 n개일 때(n-1) + (n-2) + … + 2 + 1
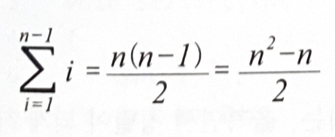
즉, 최선의 경우와 최악의 경우 모두 O(n^2)
•
이동의 횟수 : 위치의 변경을 위한 데이터의 이동횟수
데이터가 이미 정렬된 상태라면 데이터의 이동이 한 번도 일어나지 않지만, 데이터가 역순으로 정렬된 상태라면 비교의 횟수와 이동의 횟수가 일치한다즉, 최악의 경우 O(n^2)이다.
선택정렬(Selection Sort) : 이해와 구현
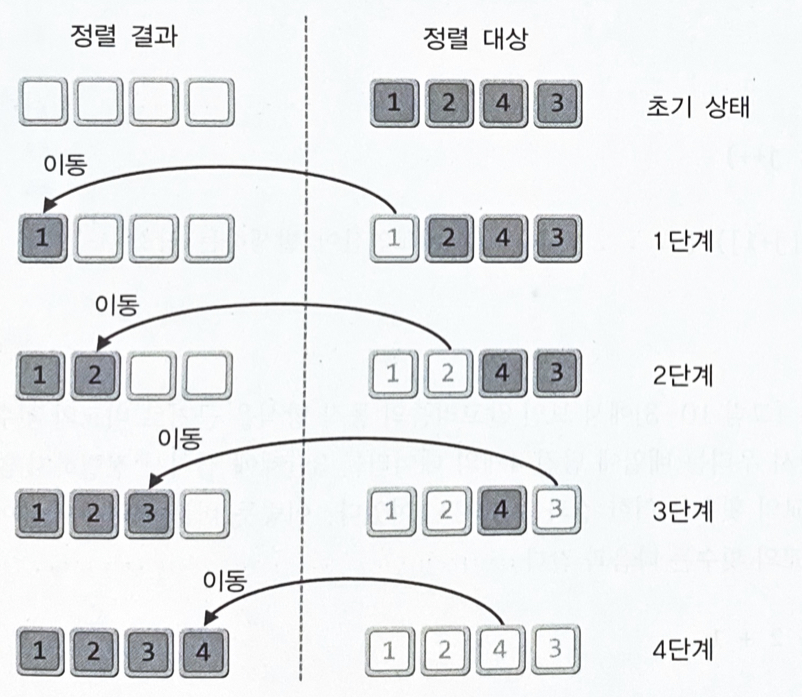
정렬 순서에 맞게 하나씩 선택해서 옮기는 정렬선택 정렬은 정렬 결과를 담을 별도의 메모리 공간이 필요하다이는 개선된 알고리즘으로 해결할 수 있다
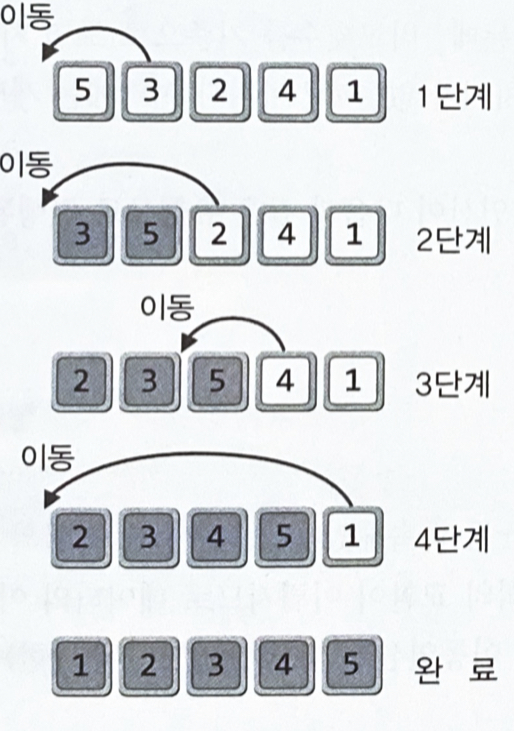
정렬순서상 가장 앞서는 것을 선택해 가장 왼쪽으로 이동시키고, 원래 그 자리에 있던 데이터는 빈 자리에 가져다 놓는다
void SelSort(int arr[], int n)
{
int i, j;
int maxIdx;
int temp;
for(i = 0; i < n-1; i++)
{
maxIdx = i;
for(j = i+1; j < n; j++)
{
if(arr[j] < arr[maxIdx])
maxIdx = j;
}
temp = arr[i];
arr[i] = arr[maxIdx];
arr[maxIdx] = temp;
}
}
Plain Text
복사
선택 정렬(Selection Sort) : 성능평가
•
비교의 횟수
•
(n-1) + (n-2) + . . . + 2 + 1즉, 최선의 경우와 최악의 경우 모두 O(n^2)
•
연산의 횟수
•
선택 정렬의 경우 데이터 연산 코드가 바깥쪽 for문에 있기 때문에 (n-1)회의 교환이 이루어지고, 코드 당 데이터가 3회 이동하므로 3(n-1)이다즉, 최선의 경우와 최악의 경우 모두 O(n)
최악의 경우 버블정렬과 비교했을 때 더 좋은 성능을 기대할 수 있지만, 버블 정렬은 최선의 경우에 단 한번도 데이터 이동이 없는 점과 실제로 데이터들이 늘 최악의 경우로 배치되어 있지 않다는 점을 감안하면 둘의 비교는 무의미하다
삽입 정렬(Insertion Sort) : 이해와 구현
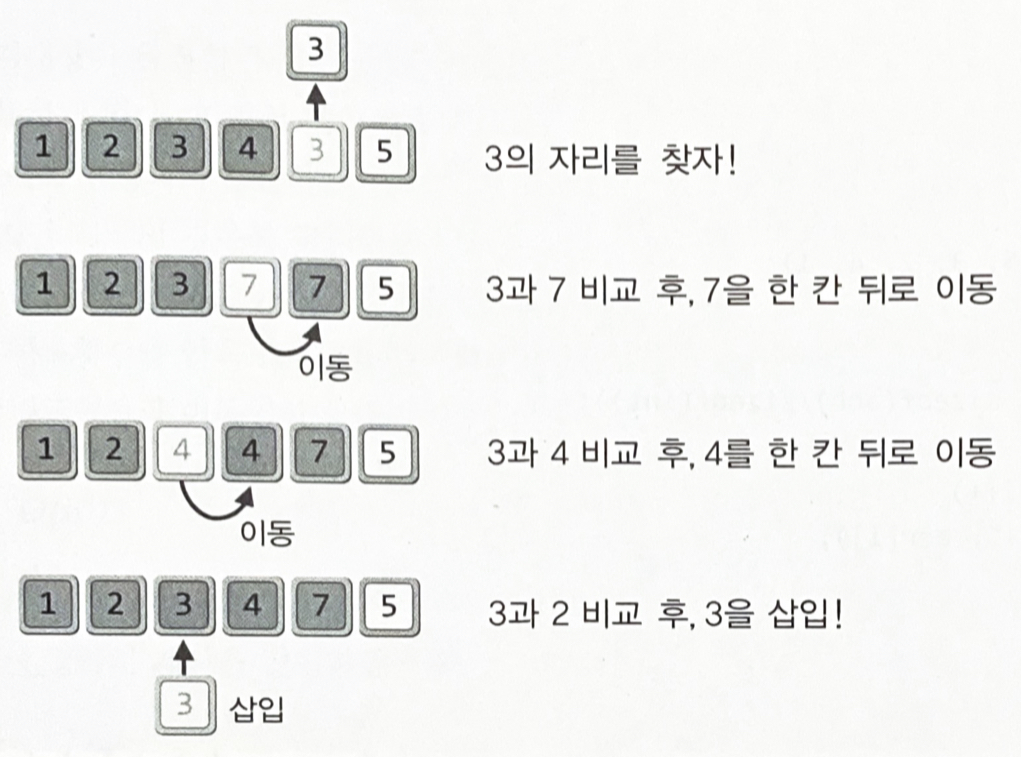
정렬이 완료된 영역의 다음에 위치한 데이터가 그 다음 정렬대상이다
•
삽입할 위치를 발견하고 데이터를 한 칸씩 뒤로 밀수도 있지만, 데이터를 한 칸씩 뒤로 밀면서 삽입할 위치를 찾을 수도 있다
void InserSort(int arr[], int n)
{
int i, j;
int insData;
for(i = 1 ; i < n; i++)
{
insData = arr[i];//정렬 대상을 insData에 저장for(j = i - 1; j >= 0; j--)
{
if(arr[j] > insData)
arr[j+1] = arr[j];//비교대상 한 칸 뒤로 밀기else
break;//삽입위치 찾았으니 탈출!
}
arr[j+1] = insData;//찾은 위치에 정렬대상 삽입!
}
}
Plain Text
복사
삽입 정렬(Insertion Sort) : 성능평가
•
비교연산, 이동연산
1 + 2 + 3 + . . . + (n-2) + (n-1) 만큼 계산되므로최선의 경우, 최악의 경우 모두 O(n^2)
10-2. 복잡하지만 효율적인 정렬 알고리즘
힙 정렬(Heap Sort) : 이해와 구현
•
힙의 특성 활용
◦
힙의 루트 노드에 저장된 값이 가장 커야 한다
◦
힙의 루트 노드에 저장된 값이 정렬순서상 가장 앞선다
#include "UsefulHeap.h"
int PriComp(int n1, int n2)
{
return n2-n1;//오름차순 정렬을 위한 문장
}
void HeapSort(int arr[], int n, PriorityComp pc)
{
Heap heap;
int i;
HeapInit(&heap, pc);
//정렬 대상을 가지고 힙을 구성한다
for(i = 0; i < n; i++)
arr[i] = HDelete(&heap);
}
Plain Text
복사
내림차순 정렬을 진행할 때: PriComp함수 변경
int PriComp(int n1, int n2)
{
return n1-n2;
}
Plain Text
복사
힙 정렬(Heap Sort) : 성능 평가
•
힙의 데이터 저장 시간 복잡도 : O(log2(n))
•
힙의 데이터 삭제 시간 복잡도 : O(log2(n))
•
삽입과 삭제를 하나로 묶었을 때 시간복잡도 : O(2log2(n)) = O(log2(n))
•
정렬대상의 수가 n개일 때 시간복잡도 : O(nlog2(n))
n^2과 nlog2(n)의 차이

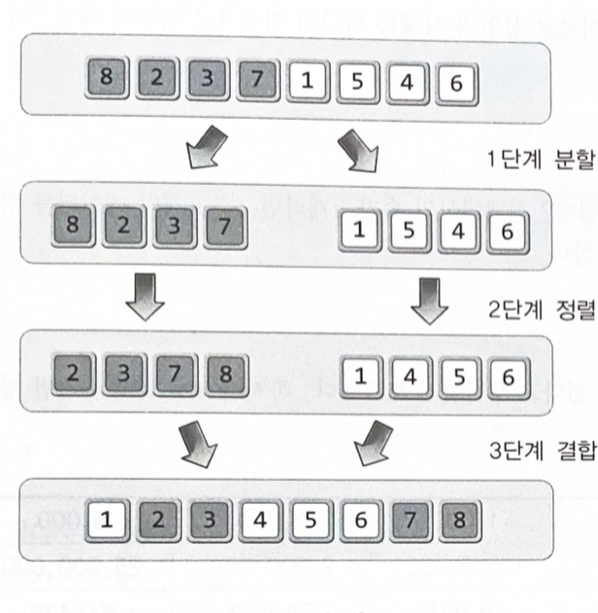
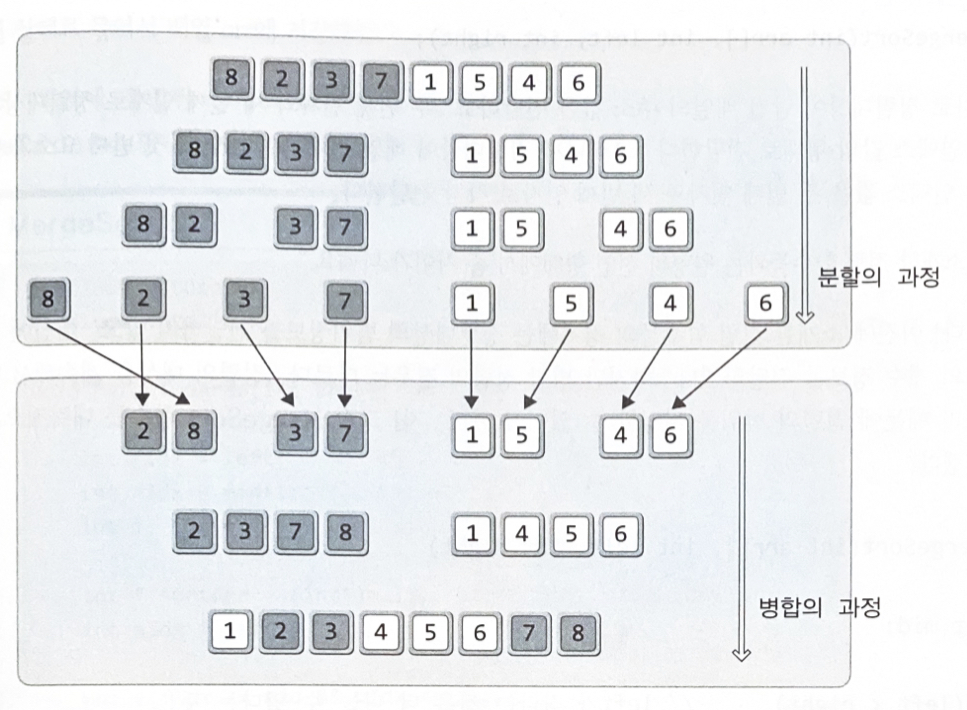
병합 정렬(Merge Sort) : 이해와 구현
분할 정복(divide and conquer)이라는 알고리즘 디자인 기법에 근거하여 만들어진 정렬 방법
•
1단계 분할(Divide) : 해결이 용이한 단계까지 문제를 분할해 나간다
•
2단계 정복(Conquer) : 해결이 용이한 수준까지 분할된 문제를 해결한다
•
3단계 결합(Combine) : 분할해셔 해결한 결과를 결합하여 마무리한다
8개의 데이터를 동시에 정렬하는 것보다, 이를 둘로 나눠서 4개의 데이터를 정렬하는 것이 더 쉽고, 또 이들을 각각을 다시 한 번 둘로 나눠서 2개의 데이터를 정렬하는 것이 더 쉽다
)
•
MergeSort 함수
•
void MergeSort(int arr[], int left, int right) { int mid; if(left < right) //left가 작다는 것은 더 나눌 수 있다는 뜻! { //중간지점을 계산한다 mid = (left + right) / 2; //둘로 나눠서 각각을 정렬한다 MergeSort(arr, left, mid); //left~mid에 위치한 데이터 정렬! MergeSort(arr, mid+1, right); //mid+1~right에 위치한 데이터 정렬! //정렬된 두 배열을 병합한다 MergeTwoArea(arr, left, mid, right); } }
•
MergeTwoArea 함수
•
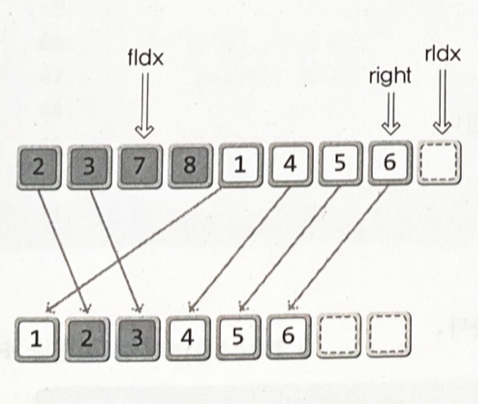
void MergeTwoArea(int arr[], int left, int mid, int right) { int fIdx = left; int rIdx = mid+1; int i; int *sortArr = (int*)malloc(sizeof(int)*(right+1)); int sIdx = left; while(fIdx <= mid && rIdx <= right) { if(arr[fIdx] <= arr[rIdx]) sortArr[sIdx] = arr[fIdx++]; else sortArr[sIdx] = arr[rIdx++]; sIdx++; } if(fIdx > mid) { for(i = rIdx; i <= right; i++, sIdx++) sortArr[sIdx] = arr[i]; } else { for(i = fIdx; i<=mid; i++, sIdx++) sortArr[sIdx] = arr[i]; } for(i = left; i <= right; i++) arr[i] = sortArr[i]; free(sortArr); }
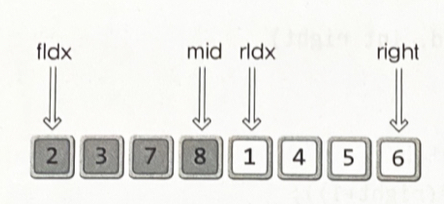
•
2와 1의 비교 : 비교연산 후 1을 sortArr로 이동, 그리고 rIdx의 값 1 증가
•
2와 4의 비교 : 비교연산 후 2를 sortArr로 이동, 그리고 fIdx의 값 1 증가
•
3과 4의 비교 : 비교연산 후 3을 sortArr로 이동, 그리고 fIdx의 값 1 증가
•
7과 4의 비교 : 비교연산 후 4를 sortArr로 이동, 그리고 rIdx의 값 1 증가
•
7과 5의 비교 : 비교연산 후 5를 sortArr로 이동, 그리고 rIdx의 값 1 증가
•
7과 6의 비교 : 비교연산 후 6을 sortArr로 이동, 그리고 rIdx의 값 1 증가
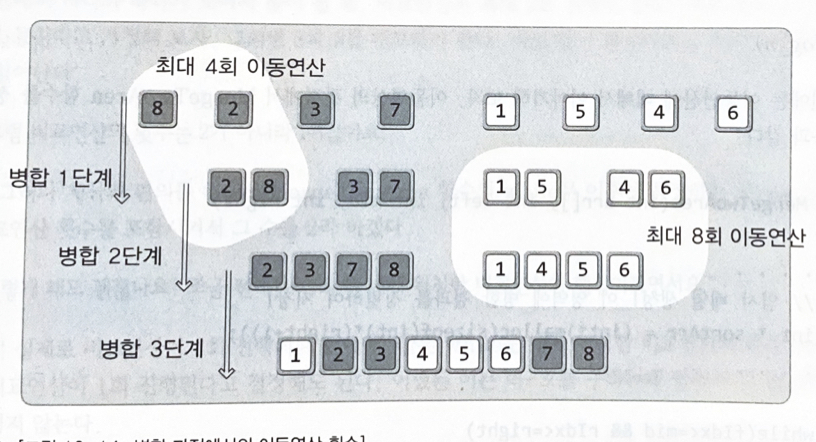
병합 정렬(Merge Sort) : 성능 평가
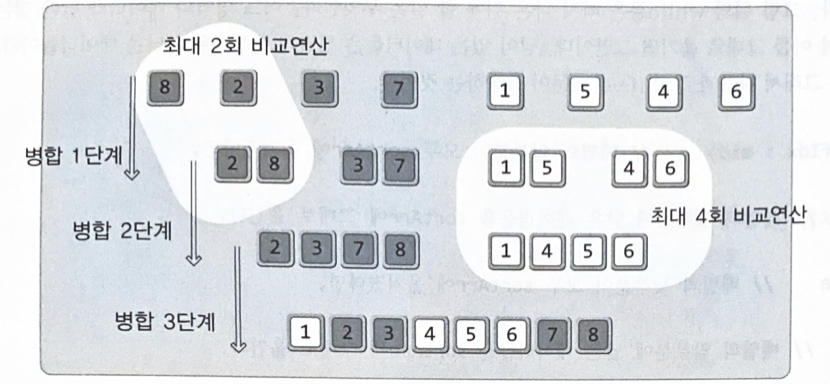
•
비교연산
•
정렬의 대상인 데이터의 수가 n개 일 때, 각 병합의 단계마다 최대 n번의 비교연산이 진행된다즉, 최대 비교연산의 횟수는 O(nlog2(n))
•
이동연산
•
임시 배열에 데이터를 병합하는 과정에서 데이터 이동
•
임시 배열에 저장된 데이터 전부를 원위치로 옮기는 과정에서 한 번즉, 최악, 평균, 최선의 경우에 상관없이 2nlog2(n)이므로 O(nlog2(n))
병합 정렬은 임시 메모리가 필요하다는 단점이 있지만 연결 리스트일 경우 단점이 되지 않는다
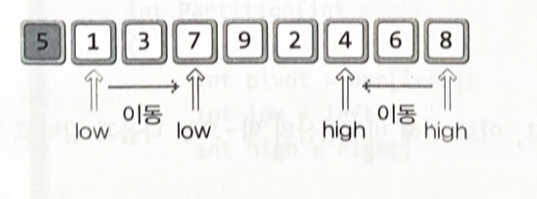
퀵 정렬(Quick Sort) : 이해와 구현

•
left : 정렬대상의 가장 왼쪽 지점을 가리키는 이름
•
right : 정렬대상의 가장 오른쪽 지점을 가리키는 이름
•
pivot : 피벗이라 발음하고 중심점, 중심축의 의미를 담고 있어 정렬을 진행하는데 필요한 기준이다
•
low : 피벗을 제외한 가장 왼쪽에 위치한 지점을 가리키는 이름
•
high : 피벗을 제외한 가장 오른쪽에 위치한 지점을 가리키는 이름
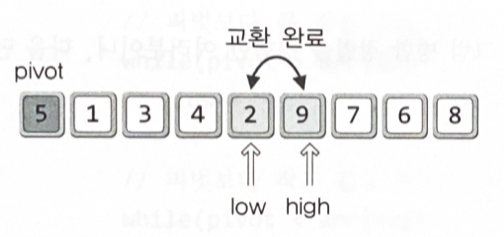
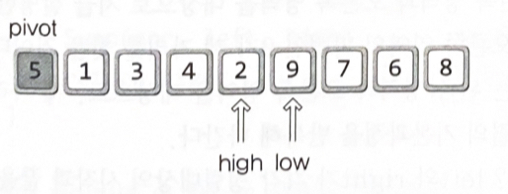
low와 high의 이동 기준
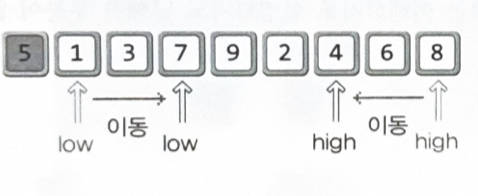
•
low의 오른쪽 방향 이동 : 피벗보다 정렬의 우선순위가 낮은 데이터를 만날 때까지
•
high의 왼쪽 방향 이동 : 피벗보다 정렬의 우선순위가 높은 데이터를 만날 때까지
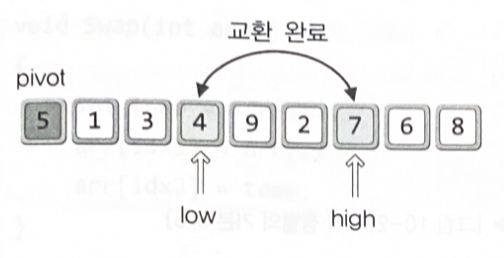
)
)
)
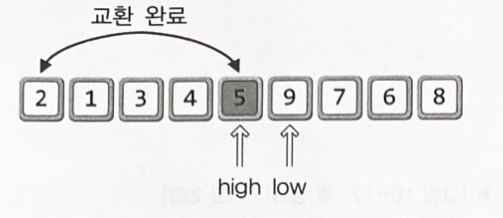
left > right일 시 정렬 종료
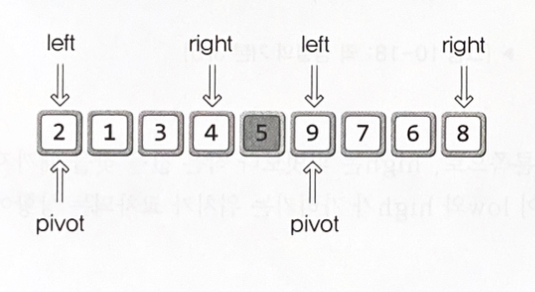
이후, 병합 정렬처럼 재귀로 진행한다
void Swap(int arr[], int idx1, int idx2)
{
int temp = arr[idx1];
arr[idx1] = arr[idx2];
arr[idx2] = temp;
}
int Partition(int arr[], int left, int right)
{
int pivot = arr[left];
int low = left + 1;
int high = right;
while(low <= high)
{
while(pivot > arr[low])
low++;
while(pivot < arr[high])
high--;
if(low <= high)
Swap(arr, low, high);
}
Swap(arr, left, high);
return high;
}
void QuickSort(int arr[], int left, int right)
{
if(left <= right)
{
int pivot = Partition(arr, left, right);
QuickSort(arr, left, pivot - 1);
QuickSort(arr, pivot + 1, right);
}
}
Plain Text
복사
같은 수가 중복이 되는 배열을 정렬할 경우 코드의 버그로 Partition함수를 빠져 나올 수 없다만일, 3이 세 개인 배열이라면pivot == arr[low] == arr[high]가 항상 참이 된다.
따라서, Partition함수를
while(pivot >= arr[low] && low <= right)
low++;
while(pivot <= arr[high] && high >= (left + 1))
high--;
Plain Text
복사
로 변경한다.
같은 수를 비교해도 low와 high를 증감하는 조건으로 변경한다. 이 때 low와 high가 배열의 정렬 범위를 넘어서는 일이 발생할 수 있으므로 경계검사를 위한 조건을 추가한다.
피벗이 중간에 해당하는 값일 경우, 정렬대상은 균등하게 나뉜다

한 쪽으로 쏠릴 경우

정렬대상에서 세 개의 데이터를 추출한다. 그리고 그 중에서 중간값에 해당하는 것을 피벗으로 선택한다
퀵 정렬(Quick Sort) : 성능평가
n번 비교를 한다. 분할을 하더라도 마찬가지이다.
Ex) 31개의 데이터를 정렬
•
31개의 데이터는 15개씩 둘로 나뉘어 총 2조각이 된다
•
이어서 각각 7개씩 둘로 나뉘어 총 4조각이 된다
•
이어서 각각 3개씩 둘로 나뉘어 총 8조각이 된다
•
이어서 각각 1개씩 둘로 나뉘어 총 16조각이 된다
즉, 평균적으로O(nlog2(n))이다최악의 경우, 피벗이 가장 작은 값으로 결정되는 상황이므로 O(n^2)이다.
하지만 퀵 정렬은 평균적으로 제일 빠른 정렬이고, 다른 정렬과 비교했을 때 이동횟수가 상대적으로 적고 별도의 메모리를 요구하지 않는다.
기수 정렬(Radix Sort) : 이해1
기수 정렬은 정렬 순서상 앞서고 뒤섬의 판단을 위한 비교연산을 하지 않는다
정렬 알고리즘의 시간 복잡도의 한계는 O(nlog2(n))인데, 이를 뛰어넘을 수 있는 유일한 알고리즘이다
하지만, 데이터의 길이가 다를 경우 정렬이 가능하긴 하지만, 효율성이 떨어져 제한적이다
10진수 정렬
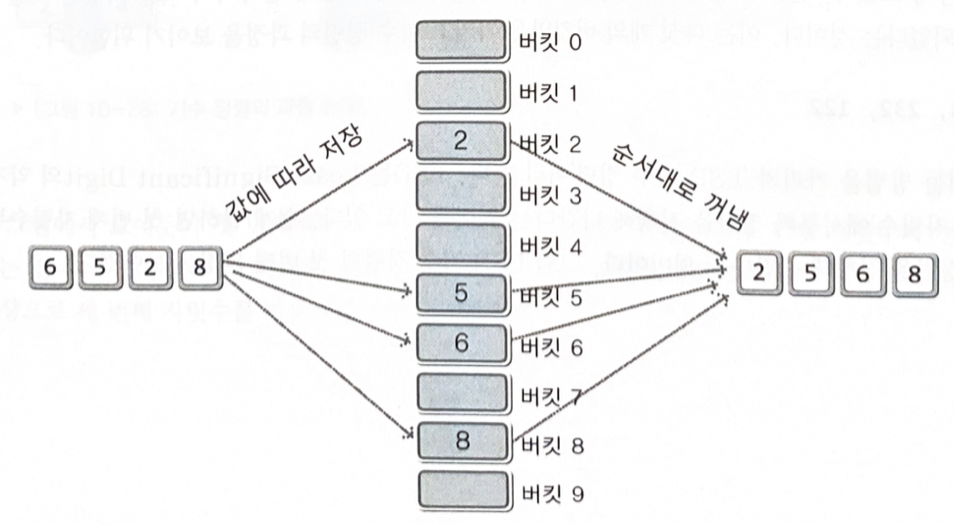
버킷 0
9까지에 해당하는 버킷으로 값을 이동시킨 후, 모든 데이터의 이동이 끝나면 0
9 순서대로 버킷에 있는 데이터를 꺼낸다
기수 정렬은 데이터를 구성하는 기본 요소, 즉 기수를 이용하는 정렬이다
기수 정렬(Radix Sort) : 이해2
LSD기수 정렬 : Least Significant Digit의 약자로 덜 중요한 자릿수부터 정렬을 해 나간다
5진수 정렬 과정

)
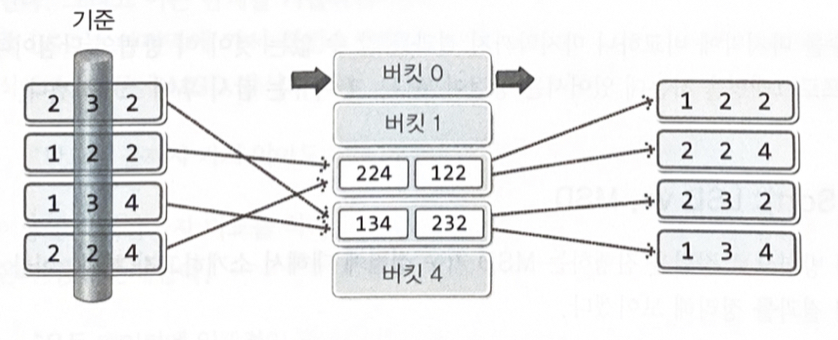
)
작은 자릿수에서 시작해서 큰 자릿수까지 모두 비교를 해야 값의 대소를 판단할 수 있다. 비교 중간에 대소를 판단하는 것은 불가능하다.
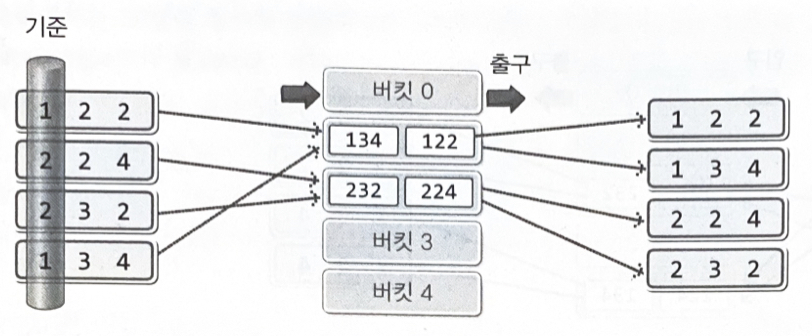
기수 정렬(Radix Sort) : LSD vs MSD
LSD의 정렬과정
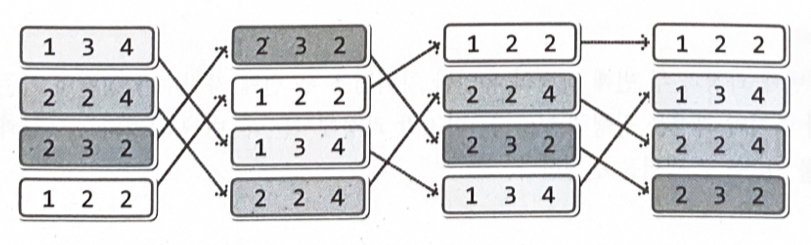
MSD기수 정렬 : Most Significant Digit의 약자로 중요한 자릿수부터 정렬을 해 나간다
•
장점 : 반드시 끝까지 정렬하지 않아도 된다. 중간에 정렬이 완료될 수도 있다
•
단점 : 모든 데이터에 일관적인 과정을 거치게 할 수 없다
기수 정렬(Radix Sort) : LSD 기준 구현
MSD와 LSD의 빅-오는 같다
•
NUM으로부터 첫 번째 자리 숫자 추출 : NUM/1%10
•
NUM으로부터 두 번째 자리 숫자 추출 : NUM/10%10
•
NUM으로부터 세 번째 자리 숫자 추출 : NUM/100%10
#define BUCKET_NUM 10
void RadixSort(int arr[], int num, int maxLen)
{
// 매개변수 maxLen에는 정렬대상 중 가장 긴 데이터의 길이 정보가 전달
Queue buckets[BUCKET_NUM];
int bi;
int pos;
int di;
int divfac = 1;
int radix;
// 총 10개의 버킷 초기화
for(bi = 0; bi < BUCKET_NUM; bi++)
QueueInit(&buckets[bi]);
// 가장 긴 데이터의 길이만큼 반복
for(pos = 0; pos < maxLen; pos++)
{
//정렬대상의 수만큼 반복
for(di = 0; di < num; di++)
{
//N번째 자리의 숫자 추출
radix = (arr[di] / divfac) % 10;
//추출한 숫자를 근거로 버킷에 데이터 저장Enqueue(&buckets[radix], arr[di]);
}
//버킷 수만큼 반복
for(bi = 0, di = 0; bi < BUCKET_NUM; bi++)
{
//버킷에 저장된 것 순서대로 다 꺼내서 다시 arr에 저장while(!QIsEmpty(&buckets[bi]))
arr[di++] = Dequeue(&buckets[bi]);
}
// N번째 자리의 숫자 추출을 위한 피제수의 증가
divfac *= 10;
}
}
Plain Text
복사
기수 정렬(Radix Sort) : 성능평가
비교연산이 핵심이 아니고, 데이터의 삽입과 추출이 핵심이다
데이터의 삽입과 추출 : maxLen X num
정렬대상의 수가 n이고, 모든 정렬대상의 길이가 l이라 할 때, 시간복잡도는O(ln)이고, 빅-오 표기법에 의해서 _O(n)_으로 본다.
즉, 기수 정렬은 _O(nlog2(n))_인 퀵 정렬보다 뛰어난 _O(n)_의 성능을 보이지만 적용 가능한 대상이 한정적인 정렬이다.
