



목차
구조체
구조체는 사용자가 C언어 기본 타입을 활용해서 새롭게 정의할 수 있는 사용자 정의 자료형이다. 관련된 정보를 하나의 의미로 묶을 때 사용한다.
구조체를 구성하는 변수를 구조체 멤버 또는 멤버 변수라고 한다.
구조체 정의와 선언
C언어에서 구조체는 struct 키워드를 사용하여 다음과 같이 정의한다.
struct 구조체이름
{
변수타입 변수1;
변수타입 변수2;
...
};
C
복사
위와 같이 정의된 구조체는 다음과 같이 구조체 변수로 선언하여 사용할 수 있다.
struct 구조체이름 구조체변수명;
// 예시
struct book my_book;
C
복사
또는, 다음과 같이 구조체 정의와 구조체 변수의 선언을 동시에 할 수 있다.
struct 태그
{
자료형 멤버이름;
...
} 타입이름;
// 예시
struct book
{
char title[30];
char author[30];
int price;
} my_book;
C
복사
구조체는 배열로도 선언이 가능하다.
// 구조체 배열 선언
struct book my_book[10];
// 구조체 배열 초기화
struct book old_book[3] =
{
{"Python", "Django", 100},
{"Java" , "Spring", 200},
{"Swift" , "iOS" , 300}
};
C
복사
구조체 포인터 선언
구조체 포인터는 동적 메모리 할당을 위해 사용한다. 위의 예제에서는 정적 메모리 할당을 한 것이며, 동적 메모리 할당을 위해서는 malloc 함수를 사용해야 한다. 만약, 동적 메모리 할당을 하지 않는다면 구조체 포인터 값은 0 으로 초기화 된다.
typedef struct node
{
int data;
} t_node;
// 구조체 포인터 선언
t_node *t1;
C
복사
디버거를 사용해 출력한 결과는 다음과 같다.
(lldb) p t1
(t_node *) $3 = 0x0000000000000000
(lldb) p &t1
(t_node **) $4 = 0x00007ffeefbff7f0
C
복사
malloc 함수를 사용하면 구조체 포인터를 선언하면 다음과 같다.
t_node *t1;
t1 = (t_node *)malloc(sizeof(t_list));
C
복사
디버거를 사용해 출력한 결과는 다음과 같다.
(lldb) p t1
(t_node *) $0 = 0x0000000100205290
(lldb) p &t1
(t_node **) $1 = 0x00007ffeefbff7f0
C
복사
typedef 키워드
typedef 키워드는 이미 존재하는 타입에 새로운 이름을 붙일 때 사용한다. 이 키워드를 사용하면 구조체를 새롭게 선언할 때 struct 키워드를 매번 사용하지 않아도 된다.
typedef struct 구조체이름 구조체의새로운이름;
// 예시
typedef struct book MYBOOK;
C
복사
또한, 구조체의 정의와 typedef 선언을 동시에 할 수도 있다.
typedef strcut 구조체이름
{
변수타입 변수1;
변수타입 변수2;
...
} 구조체_새로운_이름;
// 예시
typedef struct book
{
char title[30];
char author[30];
int price;
} MYBOOK;
C
복사
구조체 이름을 생략한 익명 구조체(anonymous structure)도 사용할 수 있다.
typedef struct {
자료형 멤버이름;
} 구조체별칭;
C
복사
구조체 변수 초기화
구조체 변수의 초기화는 크게 3가지 방법으로 할 수 있다.
// 구조체 변수 초기화 방법 1
MYBOOK book1; // MYBOOK 타입 변수 선언
strcpy(book1.title, "장고는 못말려");
strcpy(book1.author, "파이똥");
book1.price = 42000;
C
복사
1번 방법으로 구조체 멤버 변수를 할당할 때, 문자열 변수는 strcpy 함수를 사용해야 한다. 이미 할당된 배열에는 문자열을 바로 넣을 수 없기 때문이다.
그리고 만약 구조체 변수를 선언하고 값을 초기화 하지 않으면, 멤버 변수에는 쓰레기값이 저장된다.
MYBOOK book1;
C
복사
디버거를 통해 구조체 변수를 출력하면 다음과 같다.
(lldb) p book1
(MYBOOK) $0 = (title = "", author = "", price = -272631760)
Bash
복사
배열 형태로 선언한 구조체도 마찬가지다.
MYBOOK book1[10];
C
복사
(lldb) p book1
(MYBOOK [10]) $0 = {
[0] = (title = "���, author = "", price = 240732)
[1] = (title = "\x01", author = "", price = 32766)
[2] = (title = "", author = ", price = -272631744)
[3] = (title = ", author = "'\x12\x01", price = 0)
[4] = (title = "", author = "\x01", price = 667696)
[5] = (title = "\x01", author = "", price = 0)
[6] = (title = "�\x01", author = "\x01", price = 33554432)
[7] = (title = "0", author = "", price = 0)
[8] = (title = "", author = ", price = 0)
[9] = (title = "", author = "", price = 32766)
}
C
복사
따라서 구조체 변수를 선언하고 나서 초기화를 해주는 것이 바람직하다.
// 구조체 변수 초기화 방법 2
MYBOOK book2 =
{
.title = "장고는 못말려",
.author = "파이똥",
.price = 79000
};
C
복사
// 구조체 변수 초기화 방법 3
MYBOOK book3 = {"장고는 못말려", "파이똥", 79000};
C
복사
2번, 3번 방법으로 초기화 할 때, 특정 멤버 변수에 값을 할당하지 않으면 해당 멤버 변수는 자료형에 따라 0 또는 빈 문자열로 초기화된다.
MYBOOK book2 = {"Django", "Python"};
MYBOOK book3 = {.author = "Java"};
C
복사
해당 변수를 출력한 결과는 다음과 같다.
(lldb) fr v book2 book3
(MYBOOK) book2 = (title = "Django", author = "Python", price = 0)
(MYBOOK) book3 = (title = "", author = "Java", price = 0)
Bash
복사
구조체 멤버 변수 접근
변수명으로 구조체를 선언했으면 . 을 사용해서 멤버 변수에 접근할 수 있다.
// 구조체 정의
typedef struct node
{
int data;
struct node *next;
} t_node;
C
복사
// 구조체 변수 선언
t_node t1;
t1.data = 1;
C
복사
포인터를 사용해서 구조체를 선언했다면 -> 또는 참조 연산자 * 를 사용해서 접근할 수 있다. 참조 연산자(*)는 멤버 연산자(.)보다 연산자 우선순위가 낮으므로 반드시 괄호를 사용해야 한다.
// 구조체 포인터 선언
t_node *t2;
t2->data = 2;
t_node *t3;
(*t3).data = 3;
C
복사
구조체 포인터 변수로 선언하고, 구조체의 멤버가 포인터일 때 역참조 하는 방법은 다음과 같다.
•
*구조체->멤버
•
*(*구조체).멤버
// 구조체 정의
typedef struct node
{
int *data;
} t_node;
C
복사
int n;
t_node *t1;
n = 10;
t1 = (t_node *)malloc(sizeof(t_node));
t1.data = &n;
C
복사
디버거를 사용해 출력한 결과는 다음과 같다.
(lldb) p *t1->data
(int) $9 = 10
(lldb) p *(*t1).data
(int) $10 = 10
C
복사
구조체를 이용한 연결 리스트
typedef struct node
{
void *content;
struct node *next;
} t_node;
C
복사
위와 같은 구조체로 연결 리스트를 다음과 같이 구현할 수 있다.
t_node *node;
t_node *new_node;
node = (t_node *)malloc(sizeof(t_node));
new_node = (t_node *)malloc(sizeof(t_node));
node->next = new_node;
C
복사
위의 코드는 node 의 다음 노드로 new_node 를 연결하는 예제이다.
바이트 패딩 (byte padding)
구조체의 크기는 멤버 변수들의 크기에 따라 결정된다. 하지만 구조체의 크기가 멤버 변수들의 크기 총합과 항상 일치하지 않는다.
#include <stdio.h>
typedef struct node
{
char a;
int b;
double c;
} t_node;
int main(void)
{
printf("sizeof(char) : %d\n", sizeof(char));
printf("sizeof(int) : %d\n", sizeof(int));
printf("sizeof(double) : %d\n", sizeof(double));
printf("sizeof(t_node) : %d\n", sizeof(t_node));
return (0);
}
C
복사
출력 결과는 다음과 같다.
sizeof(char) : 1
sizeof(int) : 4
sizeof(double) : 8
sizeof(t_node) : 16
Plain Text
복사
구조체 멤버 변수의 크기는 각각 1, 4, 8 바이트이지만, 구조체의 크기는 16이다.
이는 구조체를 메모리에 할당할 때 컴파일러가 프로그램의 속도 향상을 위해 바이트 패딩(byte padding) 규칙을 이용하기 때문이다.
구조체는 다양한 자료형을 멤버 변수로 가질 수 있는데, 컴파일러는 메모리의 접근을 쉽게 하기 위해서 크기가 가장 큰 멤버 변수를 기준으로 모든 멤버 변수의 메모리 크기를 맞춘다.
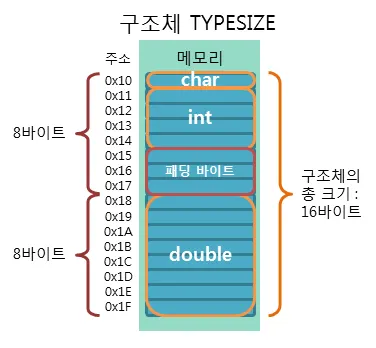
출처 : TCP School
위의 예제에서는 크기가 가장 큰 double 형 타입의 크기인 8바이트를 기준으로 메모리 크기가 설정된다. 실제로 사용하지 않는 패딩 공간을 확보함으로써 메모리의 크기를 맞추는 이유는 캐시 hit 율을 높이고 CPU의 연산 횟수를 줄이기 위해서이다.
이를 이용하면 효율적인 구조체 설계가 가능하다.
효율적인 공간 설계
typedef struct node
{
int a;
int b;
char c;
char d;
double e;
short f;
} t_node;
C
복사
위와 같은 구조체는 크기는 다음과 같다.
sizeof(t_node) : 32
Plain Text
복사
메모리를 시각화해서 보면 다음과 같다.

출처 : 코딩팩토리
멤버 변수를 정의한 순서에 따라 메모리가 할당되기 때문에 멤버 변수의 순서를 고려해서 정의한다면 효율적으로 메모리를 사용할 수 있다.
typedef struct node
{
double e;
int a;
int b;
char c;
char d;
short f;
} t_node;
C
복사
실제로 이전 예시에 비해 공간이 줄어든 것을 확인할 수 있다.
sizeof(t_node) : 24
Plain Text
복사

출처 : 코딩팩토리
double 형 변수의 위치만 위에 선언해줌으로써 불필요한 공간이 8이나 감소했다. 그래서 큰 byte 를 차지하는 자료형이라면 가장 위에 선언하여 불필요한 메모리 낭비를 줄이는 것이 좋다.
참고자료
•
•
Linked List [라피신 학습 내용]
•
구조체의 기본 [TCP School]
•
초보자를 위한 기초 C언어 강좌 #19 : 구조체 [티스토리]
•
구조체 배열 / strcpy [네이버 블로그]
•
구조체 사용하기 [코딩도장]
•
구조체 포인터 사용하기 [코딩도장]
•
구조체의 활용 [TCP School]
•
구조체, 클래스의 패딩 바이트에 대하여 [티스토리]
