



개요
스프링으로 포팅하면서 이전보다 느리게 오는 응답에 대해서 문제점을 분석하고, 이를 해결하기 위해서 DB와 백엔드 코드에서 어떻게 해결할 수 있을지에 대해서 분석해보려고 한다.
겪고 있는 문제
서비스의 웹 뷰에서 사용자가 로그인 후 가장 먼저 하게 되는 행동은 특정 층의 사물함 전체 조회다. 기존 Nest.js 백엔드에서는 100회 평균 약 80ms로 응답속도가 빨랐는데, 스프링 포팅 이후에 해당 호출이 100회 평균 약 520ms로 급격히 상승했다
문제 진단
•
응답 속도 측정해보기 (Postman Runner)
•
쿼리 호출이 너무 잦지는 않은가? (코드 고치기)
•
인덱스가 잘 설정되어 있는가? (DB Index)
•
멀티 스레드의 가용이 잘 이뤄지고 있는가? (스레드 풀과 커넥션 풀)
Postman을 이용한 응답 시간 측정
웹 개발을 경험해본 사람들에게 익숙한 Postman은 API를 테스트하기 위한 API 플랫폼이다. Postman에는 Runner라는 기능이 있는데, 본인이 설정해놓은 HTTP 요청을 특정 시간과 간격, 딜레이 등등을 두어서 테스트 해볼 수 있다.
•
기존 Nest.js에서 2층 사물함들의 정보에 대한 응답속도 - 평균 약 80ms(AWS 서버)
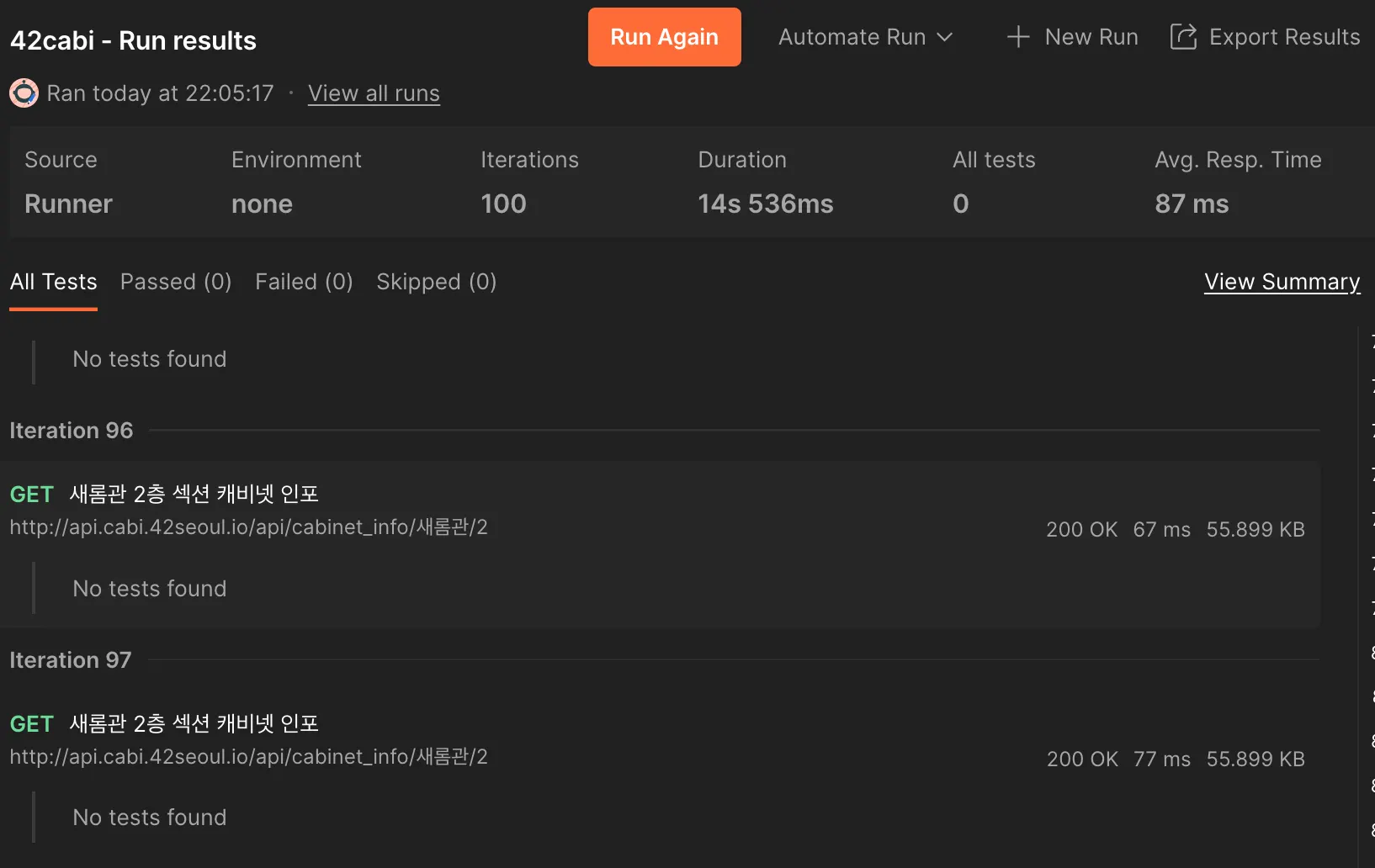
100회 평균 87ms로 좋은 응답 속도를 보이고 있다.
한편..
•
Spring 포팅 직후의 응답속도 - 평균 약 520ms(심지어 로컬)
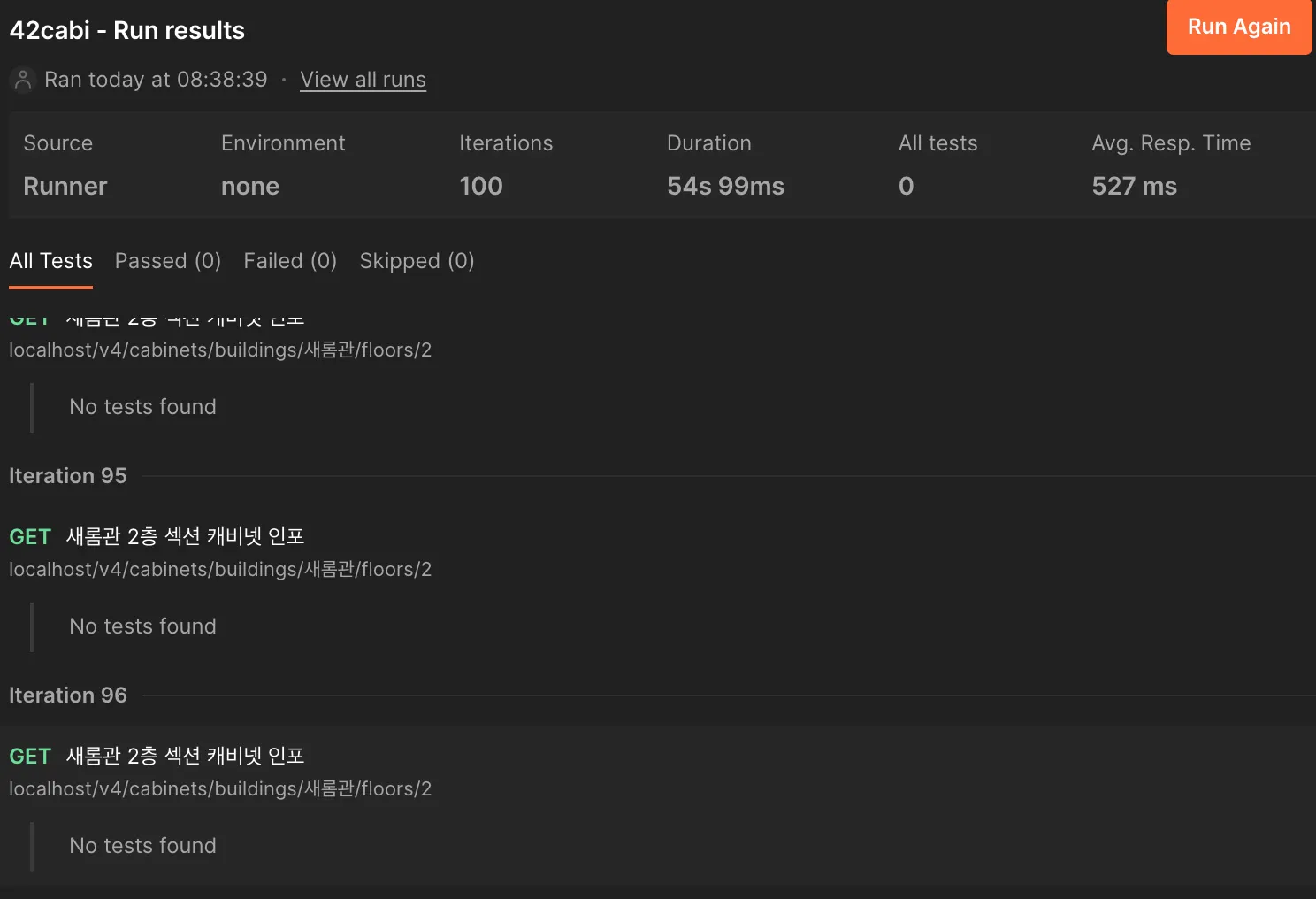
약 4배 이상이 차이가 나는 어마무시한 속도를 보여주고 있다.
문제점 알아보기
이 끔찍한 속도의 원인을 찾아보기 위해서 찾아본 결과, 문제점은 다음과 같았다.
•
해당 응답을 요청하는 뷰에서 필요하지 않은 정보를 호출하고 있었다.
→ 사이드바의 특정 층을 누르면, 해당 층의 모든 사물함들의 정보를 가져오는데, 뷰에 사용되지 않는 정보들과 클릭 시에 응답되는 정보와 겹치는, 즉 불필요한 정보들이 있었다.
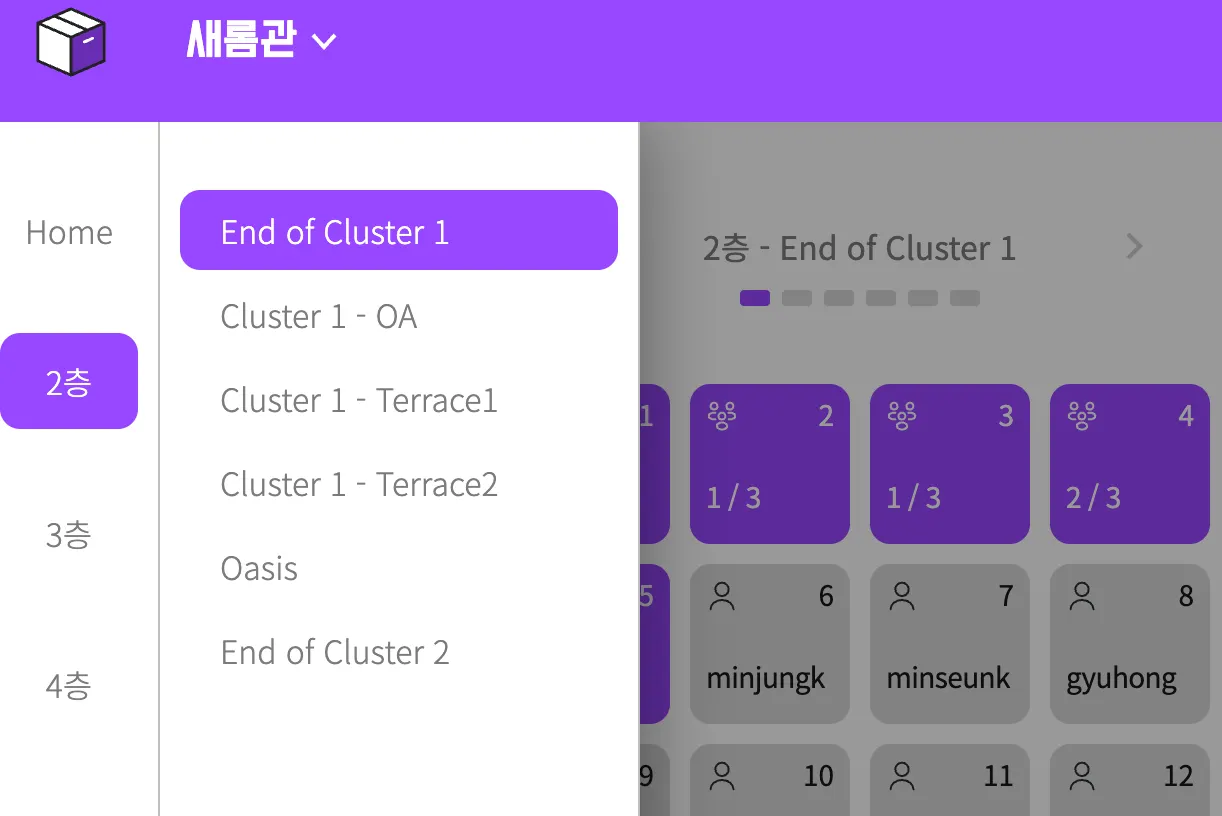
뷰에서는 나타나지 않는 공유 사물함 대여자의 대여 정보들도 응답 받았다.
•
불필요한 쿼리 호출의 반복이 많다.
쿼리 호출은 기본적으로 백엔드 서버와 DB 서버의 데이터 네트워크 통신이다.
통신은 당연히 내부 데이터를 읽고 쓰는 것 보다 느리므로, 불필요하게 호출하는 횟수가 많을 수록 무조건 느려질 수 밖에 없다.
→ 기존의 Nest.js 환경에서는 TypeORM을 이용해 적은 횟수의 쿼리 호출로 원하는 데이터를 가져왔다.
사용자가 누른 층에 해당하는 모든 사물함(Cabinet)의 정보를 가져온다.
이 때, 연관관계를 이용하여 해당 사물함의 대여(LentHistory), 대여 중인 유저(User)에 대한 정보를 모두 가져온다.
이후 현재 특정 위치와 층에 해당하는 모든 섹션 정보를 가져오고, 이를 기준으로 사물함 번호로 정렬한다.
→ 현재 Spring의 방식은 해당 건물과 층에 해당하는 섹션을 가져오고 - 해당 섹션의 사물함들을 조회하고 - 해당 사물함들 각각의 사용중인 대여기록을 조회하고 정렬하므로 호출이 약 3~4배 많았다.
또, @JoinColumn을 통한 연관관계로 최적화된 쿼리를 사용하는 것이 아닌, 직접 그 엔티티가 다른 연관관계에 대한 ID를 기준으로 직접 가져오는 구조(섣부른 설계)로 인해서 코드 작성 또한 번거로웠다.
해결 방법 알아보기
결국 문제는 ‘사용자의 입장에서 해당 요청을 보냈을 때 응답이 느리다’였고, 이를 위해서는 속도에 대한 개선이 필요했다.
데이터를 응답받을 때 느려지는 문제의 해결방법들에 대해 찾아보았을 때, DB Index 튜닝과 커넥션 풀에 대한 관리에 대한 내용이 있었다.
DB 인덱스 튜닝
DB의 인덱스와 관련하여 찾아보고, 직접 현재 문제가 되는 조회 부분에 해당하는 부분들에 Index를 설정해보았다. 어쩌면 내가 잘못 걸었을 지 모르겠지만, 별다른 개선점은 없었다.
→ 인덱스 튜닝은 DB에 있는 데이터(Row)의 개수가 매우 많은 경우, 그리고 이 때의 조회에서 큰 효과를 갖는다. 한편, 우리 서비스의 경우 Row가 그렇게 많지 않기 때문에, 그리고 PK나 FK에 기본적으로 설정된 인덱스들이 있었기에 큰 효과는 보지 못했다.
커넥션 풀 관리
커넥션 풀(Connection Pool)은 스레드 풀과 유사한 개념으로서, 스레드 풀의 스레드 생성, 해제가 그러하듯이 DB 서버와 클라이언트의 연결 및 해제의 비용이 비싸기 때문에 미리 연결 해놓은 집합을 의미한다. 커넥션 풀의 관리는 DB 서버와 연결된 클라이언트 쪽의 스레드의 개수를 관리하는 등, 서버-클라이언트 양쪽에 대한 스케일링으로 원활한 요청-응답 구조를 만들어서 해결하는 방법이다. 이는 실시간 사용자가 너무 많아 커넥션 풀의 관리가 필요할 때(병목이 생길 때) 해결하는 방법이다. 하지만, 위에 썼듯 실시간 사용자가 그렇게 많지 않은 우리 서비스에서 해결책으로서 사용되기는 적절하지 않다고 판단했다.
불필요한 부분들을 개선해보자
아무래도 JPA와 Spring 자체에 익숙하지 않다보니 생각나는대로 구현해서 이런 불상사가 발생했다(범인은 나였다).
결국 근본적으로 호출하는 방식과 이에 대한 개선이 필요했다.
우선, 기존에 사용하지 않던 @JoinColumn 설정으로 연관관계에 대해 지연 로딩 및 최적화했고, 약 140ms 정도 줄일 수 있었다.
TMI - JoinColumn, 지연 로딩?
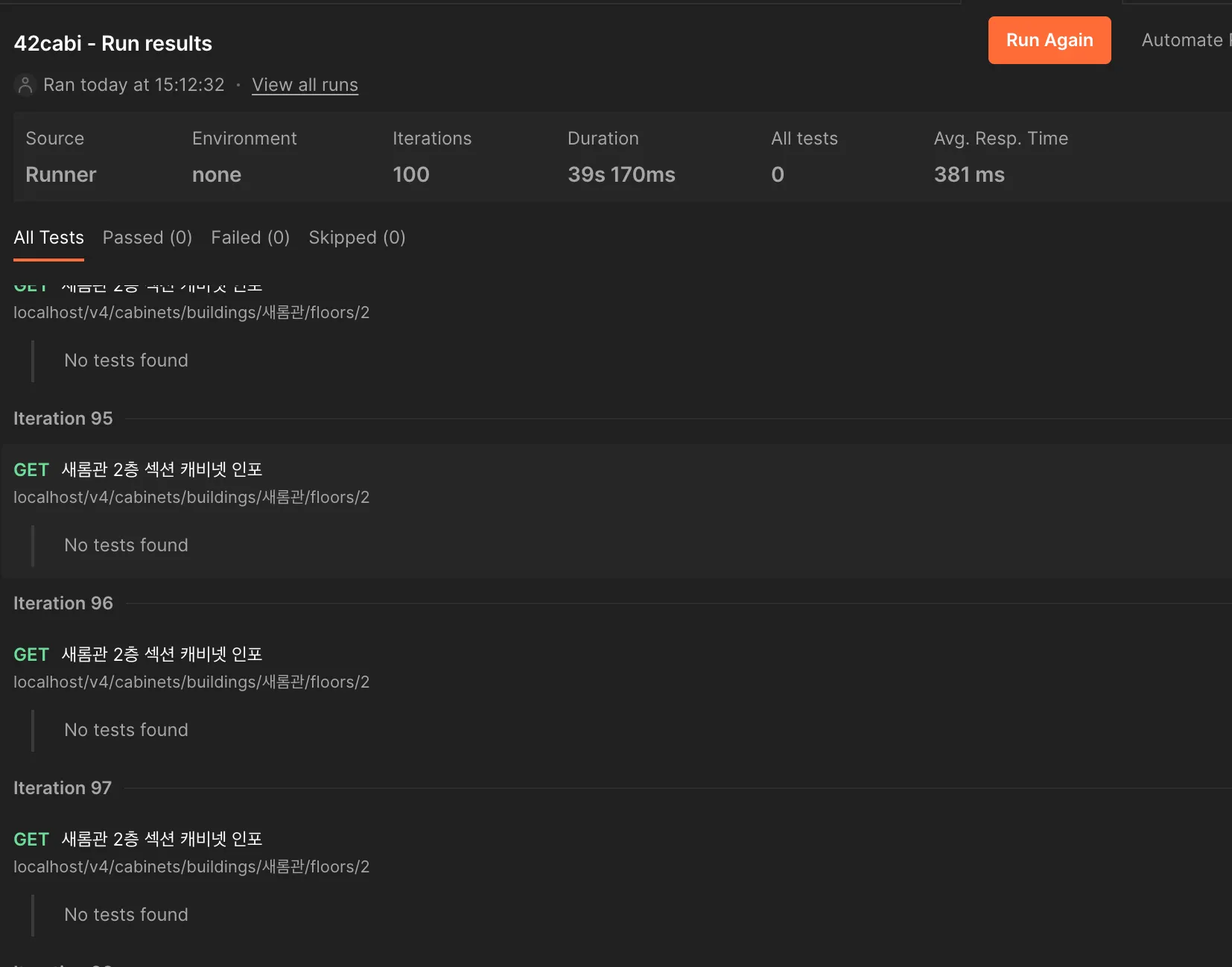
또, 기존에 해당 뷰에서 필요없는 정보(해당 사물함의 현재 대여 정보 전체)를 응답했었는데, 이 부분을 덜어내고, @Transactional(readOnly = true)를 통한 DB 조회 최적화를 통해 속도를 약 200ms 줄일 수 있었다.
→ 응답 데이터의 변경으로 인해 프론트엔드에도 영향이 있으므로 딱히 좋은 방법은 아닌 것 같았지만, 불필요한 정보를 중복해서 요청한다는 점에서 개선이 필요하다고 생각했다.
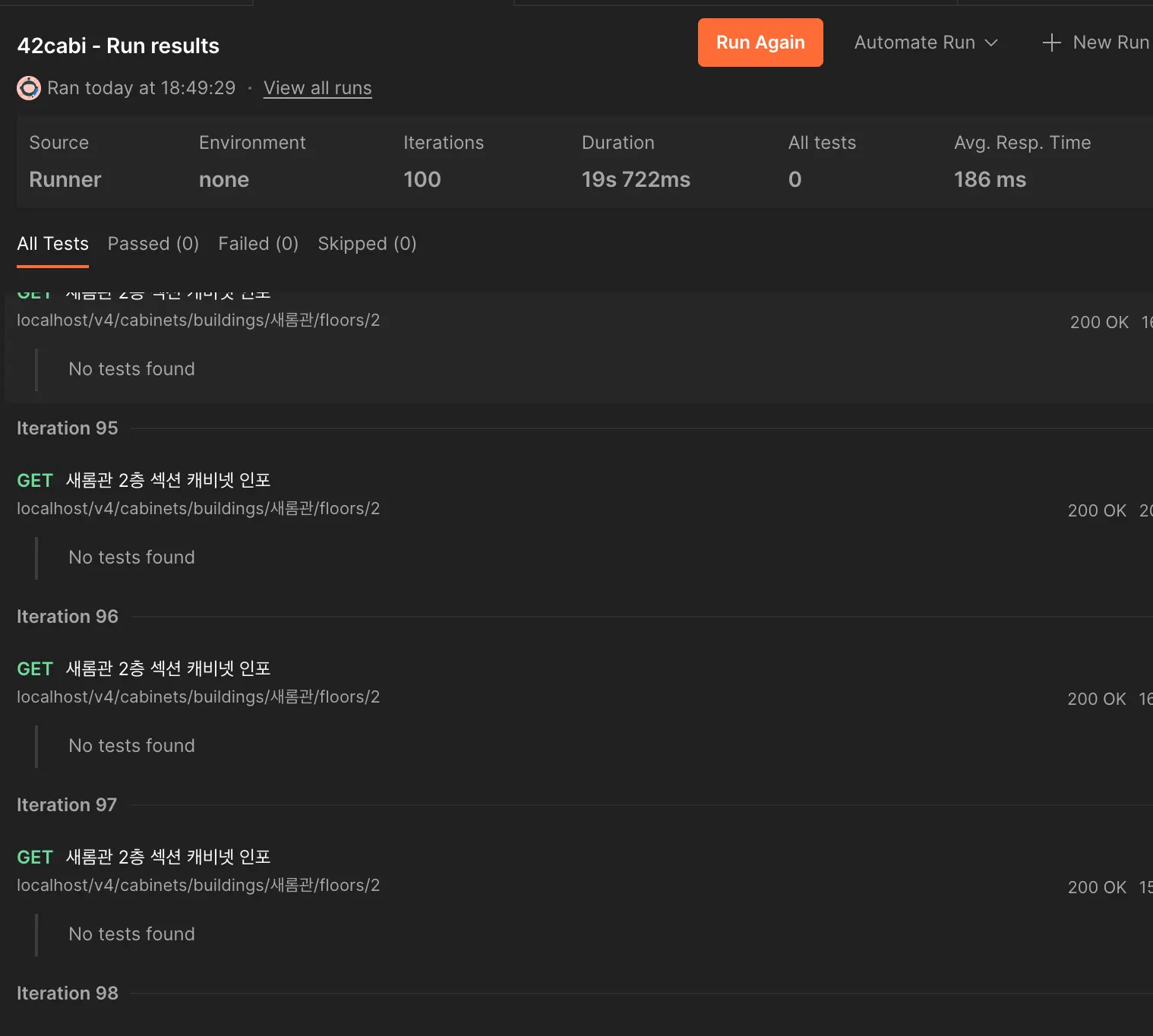
하지만 이전의 평균 80ms에 달하던 빠른 속도에는 아직 한참 못 미친다.
기존의 520ms에서 180ms까지 약 340ms 정도를 빠르게 만들었다. 그럼에도 불구하고 기존의 Nest.js의 속도인 80ms와 비교했을 때, ‘왜 굳이 스프링으로 바꿨어?’라는 질문을 들어도 할 말이 없을 것 같았다.
따라서, 가장 효과가 좋을 것이라고 예상한 직접적인 호출 횟수 줄이기에 돌입해보았다.
•
문제의 코드
@Override
@Transactional(readOnly = true)
public List<CabinetsPerSectionResponseDto> getCabinetsPerSection(String building,
Integer floor) {
log.info("getCabinetsPerSection");
return cabinetOptionalFetcher.findAllSectionsByBuildingAndFloor(building, floor).stream() // 1 - 섹션 조회
.map(section -> {
return cabinetMapper.toCabinetsPerSectionResponseDto(section,
getCabinetPreviewBundle(Location.of(building, floor, section))); // 2 - 섹션 별
})
.collect(Collectors.toList());
}
private List<CabinetPreviewDto> getCabinetPreviewBundle(Location location) {
List<Cabinet> cabinets = cabinetOptionalFetcher.findAllCabinetsByLocation(location); // 3 - 섹션 별 전체 사물함 조회
return cabinets.stream().map(cabinet -> {
List<LentHistory> lentHistories = lentOptionalFetcher.findAllActiveLentByCabinetId(
cabinet.getCabinetId()); // 4 - 사물함 별 현재 대여 기록 조회
String lentUserName = null;
if (!lentHistories.isEmpty() && lentHistories.get(0).getUser() != null) {
lentUserName = lentHistories.get(0).getUser().getName();
}
return cabinetMapper.toCabinetPreviewDto(cabinet, lentHistories.size(), lentUserName);
}).collect(Collectors.toList());
}
Java
복사
섹션 * 사물함 * 대여기록이라는 끔찍한 짓을 하고 있다.
쿼리 호출과 여러 번의 탐색으로 인해 속도가 느렸다.
•
개선 후
@EntityGraph(attributePaths = {"cabinetPlace"})
@Query("SELECT DISTINCT c, lh, u " +
"FROM Cabinet c " +
"JOIN c.lentHistories lh ON lh.cabinetId = c.cabinetId " +
"JOIN lh.user u ON lh.userId = u.userId " +
"WHERE c.cabinetPlace.location.building = :building AND c.cabinetPlace.location.floor = :floor " +
"AND lh.endedAt IS NULL")
List<Object[]> findCabinetActiveLentHistoryUserListByBuildingAndFloor(
@Param("building") String building, @Param("floor") Integer floor);
Java
복사
TMI - EntityGraph?
결국 필요한 정보는 ‘현재 층에 해당하는 모든 섹션의 사물함과 그 사물함의 대여 정보와 대여 중인 유저’에 대한 정보가 필요했기 때문에, Cabinet-LentHistory-User의 세 가지를 최대한 한번에 가져오도록 쿼리를 변경했다.
public List<ActiveCabinetInfoEntities> findCabinetsActiveLentHistoriesByBuildingAndFloor(String building, Integer floor) {
log.info("Called findCabinetsActiveLentHistoriesByBuildingAndFloor2: {}, {}", building, floor);
return cabinetRepository.findCabinetActiveLentHistoryUserListByBuildingAndFloor(building, floor).stream()
.map(result -> {
Cabinet cabinet = (Cabinet) result[0];
LentHistory lentHistory = (LentHistory) result[1];
User user = (User) result[2];
return cabinetMapper.toActiveCabinetInfoEntities(cabinet, lentHistory, user);
}).collect(Collectors.toList());
}
Java
복사
TMI - 처음에 이 방식이 꺼려졌던 이유
public List<CabinetsPerSectionResponseDto> getCabinetsPerSection(String building, Integer floor) {
// 해당 건물과 층에 해당하는 모든 사물함에 대한 대여 기록 - 유저를 가져온다.
List<ActiveCabinetInfoEntities> results = cabinetOptionalFetcher.findCabinetsActiveLentHistoriesByBuildingAndFloor(building, floor);
// 사물함 하나에 대한 대여 기록을 List로 묶고, 이를 Map(Key, Value)으로 구성한다. (DB에서 Row로만 가져오기 때문)
Map<Cabinet, List<LentHistory>> cabinetLentHistories = results.stream().
collect(Collectors.groupingBy(ActiveCabinetInfoEntities::getCabinet,
Collectors.mapping(ActiveCabinetInfoEntities::getLentHistory, Collectors.toList())));
// 해당 Map을 순회하면서, section이 일치하는 <사물함, 대여기록>들을 구성한다.
Map<String, List<CabinetPreviewDto>> cabinetPreviewsBySection = new HashMap<>();
cabinetLentHistories.forEach((cabinet, lentHistories) -> {
String section = cabinet.getCabinetPlace().getLocation().getSection();
CabinetPreviewDto preview = createCabinetPreviewDto(cabinet, lentHistories);
if (cabinetPreviewsBySection.containsKey(section)) {
cabinetPreviewsBySection.get(section).add(preview);
} else {
List<CabinetPreviewDto> previews = new ArrayList<>();
previews.add(preview);
cabinetPreviewsBySection.put(section, previews);
}
});
// Map을 Set<Entry>로 변경하고, 실물번호(VisibleNum)을 기준으로 <섹션, Preview>의 리스트로 구성해 반환한다.
return cabinetPreviewsBySection.entrySet().stream()
.sorted(Comparator.comparing(entry -> entry.getValue().get(0).getVisibleNum()))
.map(entry -> cabinetMapper.toCabinetsPerSectionResponseDto(entry.getKey(), entry.getValue()))
.collect(Collectors.toList());
}
Java
복사
결국 ‘최대한 작은 횟수 안에 필요한 많이’가져오고, 이를 ‘DB가 아닌 백엔드 서버(WAS) 내부에서 연산’하는 것이 중요하다고 생각했다. 어차피 DB에서 데이터를 가져올 때 탐색하는 범위는 정해져 있을 것이고, 연산 자체는 DB서버가 아닌 백엔드 서버가 더 빠를 것이기 때문이다.
26배 빨라진 응답 속도
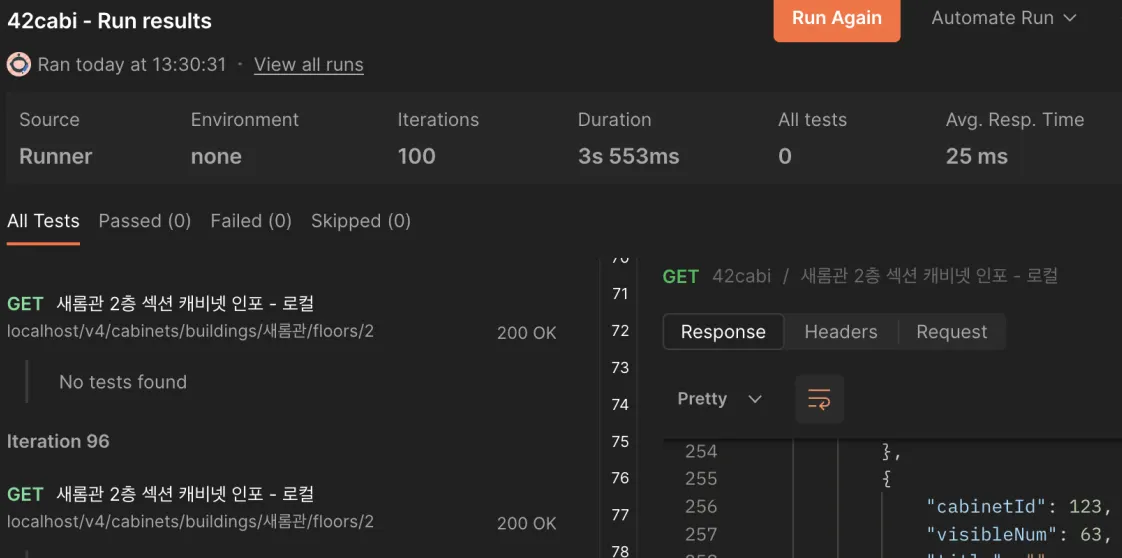
예상을 훨씬 웃도는 속도로 빨라졌다.
제일 빨랐던 기존 Nest.js 서버의 80ms보다 훨씬 빠른, 맨 처음 520ms보다 26배 빠른 평균 20ms대의 속도를 응답한다..!
결국 가장 주요했던 부분은 ‘기본적인 호출 방식’이었던 것 같다.
깨달은 점
•
DB 호출은 최대한 적게, 최대한 크게!
→ 이를 좁혀나가는 연산은 WAS에서 진행하는 것이 훨씬 효율적이다.
•
불필요한 호출에 대해 주기적인 점검이 필요하지 않을까?
→ 더 큰 비즈니스를 가정한다면, 중복되는 정보에 대한 응답은 결국 돈이라고 생각한다.
•
더 높은 수준의 해결방법보다 가장 기저가 되는 부분에 대한 해결이 우선이다.
→ 결국 근본적인 문제를 해결해야 의미가 있다.
•
기존의 구조와 일관성이 살짝 맞지 않더라도, 가장 중요한 건 원활한 서비스다.
→ 배고프지만 예쁜 코드보다 배부르고 더러운 코드가 나을 수 있다.


