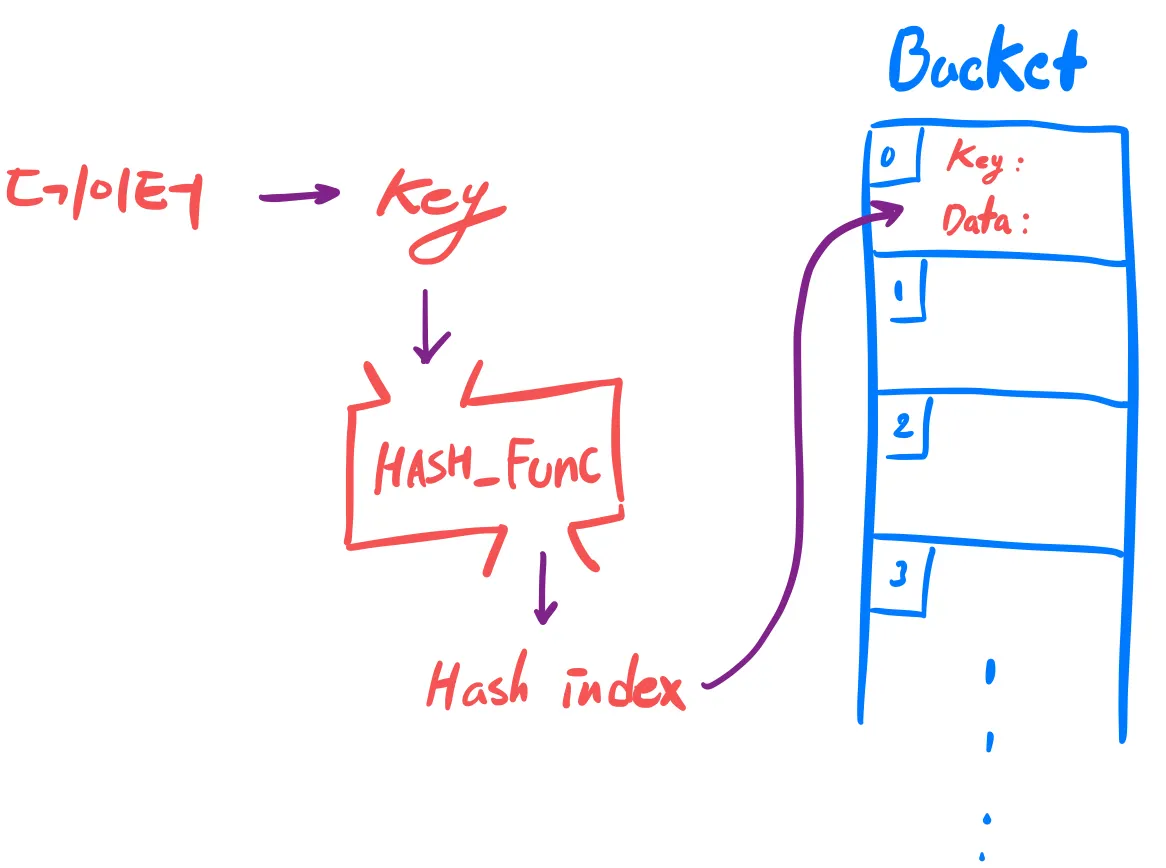
해시테이블 이란?
1.
데이터로 키 값을 만들고,
2.
키 값을 해시 함수를 통해 해시 인덱스를 만듭니다
3.
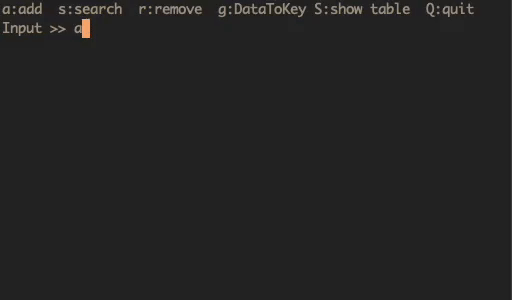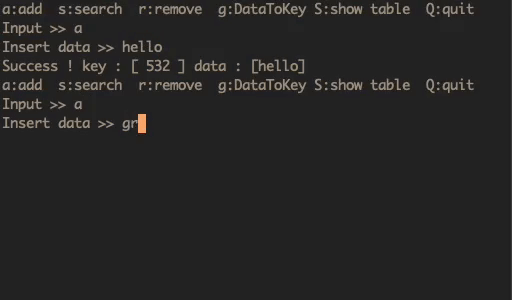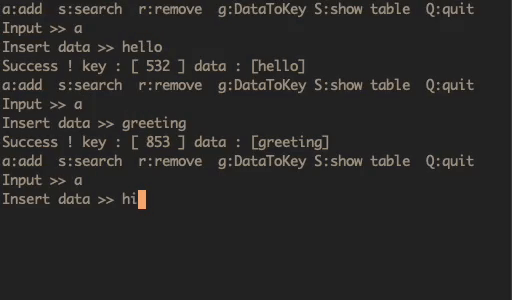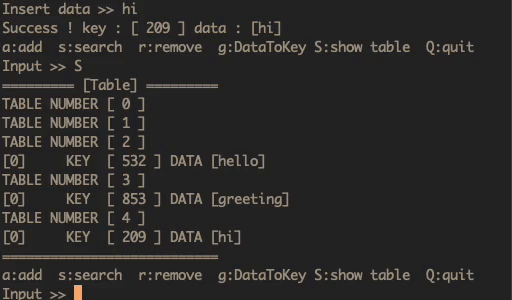
인덱스에 해당하는 테이블(버킷)에 데이터와 키를 저장하는 자료구조입니다 Key - Value
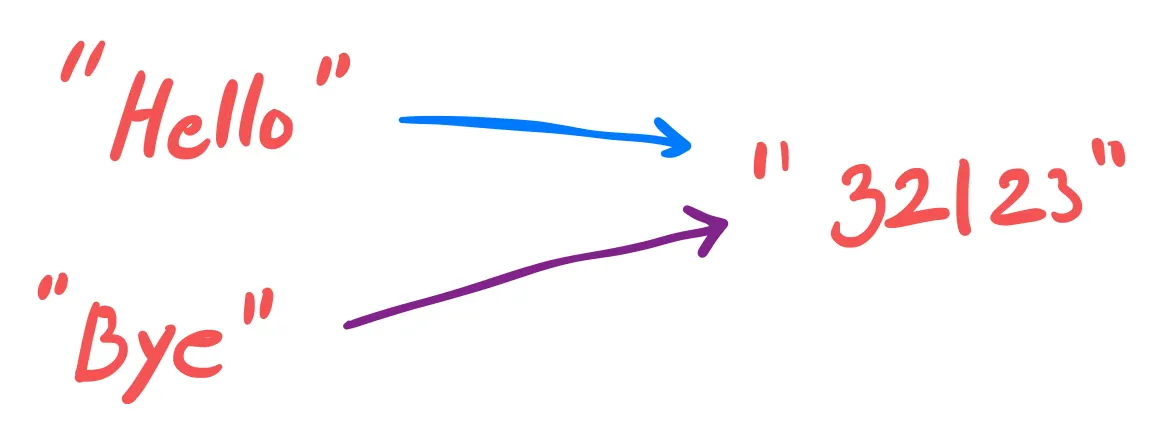
Hash Collision
1.
Different data -> Same key
다른 데이터로 같은 키값을 가지는 것
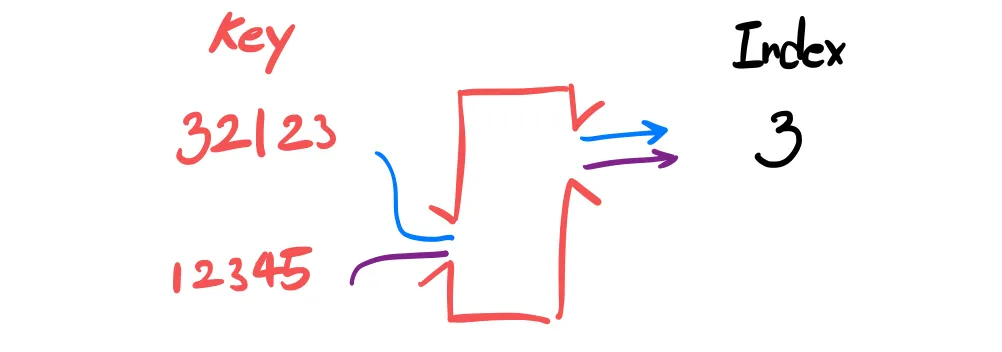
2.
Different key -> Same HashIndex
다른 키로 같은 인덱스를 가지는 것
해시 테이블의 시간 복잡도
가장 이상적인 경우 : 중복되지 않은 HashIndex를 가진 HashTable
최악의 경우 : 모든 값이 중복되는 HashIndex를 가진 HashTable
가장 이상적인 경우 O(1)의 시간 복잡도를 가집니다.
하지만 Hash Collision으로 인해,
최악의 경우 O(n)의 시간 복잡도를 가지게 됩니다.
따라서 Hash Collision이 최대한 일어나지 않도록 분배해주어야 합니다.
Hash Collision resolution
1.
Open Addressing
2.
Chaining
해시 충돌 문제 해결을 위한 두 가지 방법 중, Chaining을 통해 구현해보도록 하겠습니다
해시 테이블 알고리즘
간단한 알고리즘을 사용했습니다
 Data To Key
Data To Key
→ 모든 문자열의 ASCII값을 더한 값
해시 함수
→ Key 값을 TABLE_SIZE로 나눈 값
HashTable ADT
int h_key_maker(char *data)
1.
데이터를 통해 키 값을 반환
t_node *h_create_node(char *data)
1.
노드를 생성하고 주소 값을 반환
2.
할당 실패 시 실패 메세지 출력 후 프로세스 종료
void h_add_hash(char *data)
1.
생성된 노드를 키 값에 맞는 인덱스를 찾아서 해시테이블에 저장
2.
해당 인덱스의 초기 값이라면 헤드에 주소 값을 저장하고,
해당 인덱스의 초기 값이 아니라면 기존 헤드를 밀어내고 헤드에 주소 값을 저장
3.
실패 시 실패 메세지 출력 후 종료
void h_remove_hash(int key)
1.
해당 키 값을 가진 노드를 찾아 삭제 후 재 연결
2.
실패 시 실패 메세지 출력 후 프로세스 종료
bool h_search_hash(int key)
1.
해시 테이블에서 동일한 키 값을 찾음
2.
성공 시 True 실패시 false 반환
Key 값을 TABLE_SIZE로 나눈 값
#define HASH_FUNCTION(KEY) KEY % TABLE_SIZE
hash.h
// hash.h
#ifndef HASH_H
#define HASH_H
#define TABLE_SIZE 5
#define HASH_FUNCTION(KEY) KEY % TABLE_SIZE
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
typedef struct s_node
{
int key;
char *data;
struct s_node *next;
} t_node;
typedef struct s_table{
t_node *head;
int count;
} t_table;
int h_key_maker(char *data);
t_node *h_create_node(char *data);
void h_add_hash(char *data);
void h_remove_hash(int key);
bool h_search_hash(int key);
char *dup(const char *s);
int len(const char *str);
void del_buf(void *str, char type);
extern t_table *table;
#endif
C
복사
Node와 Table 구조체 선언
노드는 데이터 와 KEY , 다음 노드의 주소 로 구성하고
테이블은 Root node의 주소 와 table의 전체 크기 로 구성했습니다
Node 만들기
t_node *h_create_node(char *data)
{
t_node *node;
node = (t_node *)malloc(sizeof(t_node) * 1);
if (!node)
return (0);
int key = h_key_maker(data);
node->key = key;
node->data = data;
node->next = 0;
return (node);
}
int h_key_maker(char *data)
{
int key = 0;
unsigned int i = 0;
if (!data)
return (0);
while (data[i])
{
key += (int)data[i];
i++;
}
return (key);
}
C
복사
기본 기능 구현
해시 테이블에서 기본적으로 구현해야 할 기능은 3가지입니다
1.
추가
2.
삭제
3.
검색
추가
void h_add_hash(char *data)
{
int hashindex;
t_node *newnode;
if (!data)
{
printf("Empty data\n");
return ;
}
if (h_search_hash(h_key_maker(data), false))
{
printf("Overlapped key\n");
return ;
}
t_node *newnode;
if (!(newnode = h_create_node(data)))
{
printf("Malloc Failed create node\n");
exit(1);
}
hashindex = HASH_FUNCTION(newnode->key);
if (!table[hashindex].count)
// 해당 인덱스의 테이블에 데이터가 없을 경우 헤드에 추가
{
table[hashindex].head = newnode;
table[hashindex].count++;
}
else
// 해당 인덱스에 데이터가 있을 경우 헤드에 있는 데이터를 밀어내고 추가
{
newnode->next = table[hashindex].head;
table[hashindex].head = newnode;
table[hashindex].count++;
}
printf("SUCCESS\n", newnode->key, newnode->data);
}
C
복사
탐색
bool h_search_hash(int key)
{
int hashindex = HASH_FUNCTION(key);
bool search_flag = false;
t_node *finder = table[hashindex].head; // 탐색할 해당 테이블의 헤드로 주소값 설정
while (finder)
{
if (finder->key == key)
{
search_flag = true;
break;
}
finder = finder->next;
}
if (search_flag == true)
{
printf("DATA: %s\n", finder->data);
return (search_flag);
}
else
{
printf("NOT EXIST\\n");
return (search_flag);
}
}
C
복사
삭제
void h_remove_hash(int key)
{
int hashindex = HASH_FUNCTION(key);
bool remove_flag = false;
t_node *finder;
t_node *before;
finder = table[hashindex].head;
while (finder)
{
if (finder->key == key)
{
if (finder == table[hashindex].head)
// 테이블의 맨 앞 노드를 다음 노드로 교체
table[hashindex].head = finder->next;
else
before->next = finder->next;
table[hashindex].count--;
free(finder);
remove_flag = true;
}
before = finder; // 현재 주소를 이전 주소로
finder = finder->next; // 다음 주소는 현재 주소로
}
if (remove_flag == true) // 삭제 했으면
printf("REMOVED: %d\n", key);
else // 삭제 못했으면
printf("NOT EXIST\\n");
}
C
복사