



개요
std::exception에 대한 논란은 언제나 많다.
제대로 문제에 대해서 이야기하기 위해선 내부구현을 알아야 한다고 생각해서 파봤다.
std::exception은 정확히 무얼 하는가
std::exception이 하는 일은 단순하지 않다.
try-catch가 있는 호출자 함수를 찾아 스택프레임을 하나하나 unwind하면서 올라가야 한다.
1.먼저 현재 함수에 catch가 있는지 체크한다,
2.없으면 현재 함수를 끝내야 하므로 지역변수의 소멸자들을 호출시킨다.
3.이전 함수의 스택 상태로 복구시킨다.
(반복)
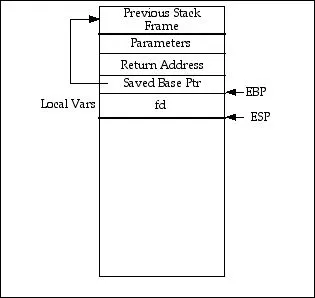
3번은 쉽다.
단순히 푸시된 BP와 Ret_addr을 이용해 이전함수의 스택 상태를 복구하고 돌아갈 수 있다.
(그냥 C언어의 return 과정을 여러번 반복하는거다. add esp, pop ebp, ret)
하지만 1번과 2번은 기존 스택의 정보로는 불가능하다.
스택 정보로는 이게 어떤 함수인지 알 수 없고
어떤 변수들의 소멸자를 호출시켜야하고
catch가 있는지 없는지에 대한 정보가 스택에 존재하지 않기 때문이다.
따라서 해당 정보들을 추가적으로 어딘가에 기록하여 추적하는 방식을 사용해야한다.
구현 방식
먼저, std::exception은 표준에서 내부구현에 대해 정의하지 않는다.
따라서 컴파일러마다, 머신 마다 다른 구현이 존재함을 유의하자.
구현 방식은 크게 2가지 형식이 있다.
1. 런타임의 함수 시작과 끝마다 현재 함수의 정보를 기록해서
스택을 추적하다 throw가 발생하면 함수를 unwind 하는 방법.
(VC++ 32bit, GCC 과거 버젼, SEH)
2. 아무런 스택 추적을 하고 있지 않다가
throw가 발생하면 RTTI처럼 함수를 특정하고 unwind 하는 방법.
(VC++ 64bit, GCC 최신 버젼)
구현 방식 1. Dynamic Registration
1번이 기존 컴파일러들이 많이 사용하던 방식이다.
런타임에서 모든 함수의 정보를 추적하므로
try를 사용하는 것 만으로도 매 함수 호출마다 오버헤드가 발생하는 문제가 있다.
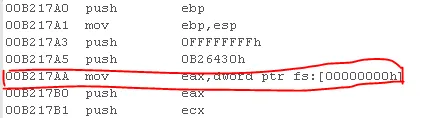
실제로 VC++ 32bit에서 try-catch를 사용하면 도입부에서 SEH를 세팅하는 것을 볼 수 있다.
스크린샷은 유영천님의 블로그에서 가져왔다.

그리고 Throw 부분을 보면 NtRaiseException 시스템 서비스를 호출한다.
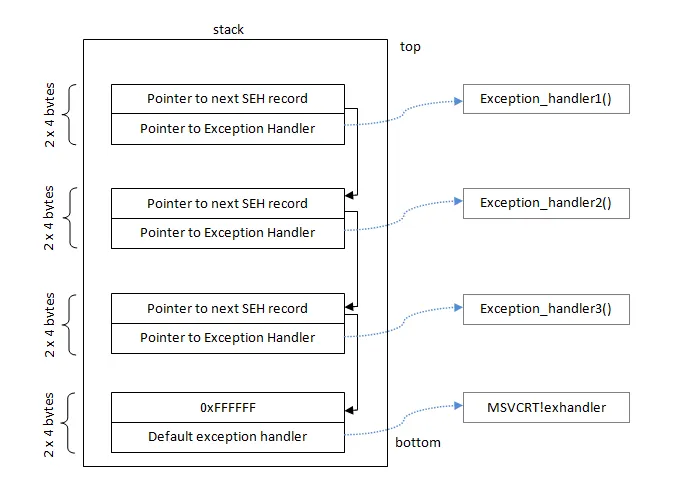
매 함수 프레임마다 별도의 Exception Handler에 대한 정보를 기록하여
추적하다가 Throw가 발생되면 시스템 콜로 핸들링 하는 방식이다.
여기서 자세히 다루진 않으므로 자세한 구현은 SEH 문서를 찾아보시길…
구현 방식 2. Table-driven approach (zero-cost exception(itanium-ABI))
2번이 최근 컴파일러들이 자주 사용하는 방법이다.
런타임에서 아무런 스택 추적을 시행하지 않다가,
Throw가 발생하면 그 때 unwind를 수행한다.
그래서 zero-cost 방식이라고 많이 불린다.
Try-catch를 사용하는 것 만으로는 비용이 들지 않고
실제 Throw가 발생했을 때 비용이 발생한다.
너무 매력적인 방식인데, 어떻게 구현했을까?
이름에서 알 수 있듯이 컴파일타임에서 함수를 식별할 수 있는 거대한 테이블을 생성하는 것이다.
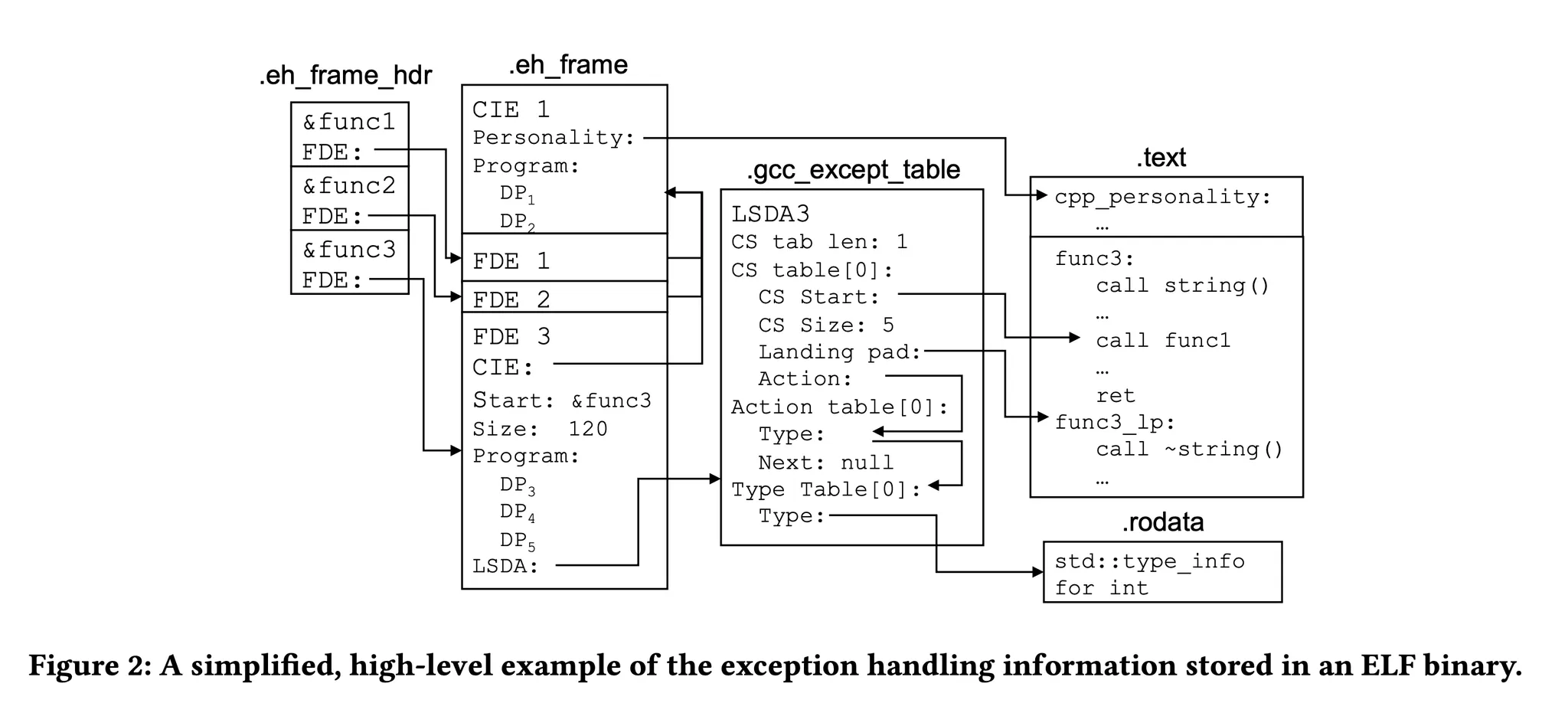
우선 IP(Instruction Pointer) 를 가지고 어떤 함수인지 찾기 위해서
어떤 함수의 코드가 어느 주소에서 시작해서
얼마만큼의 범위를 가지고 있는지에 대한 테이블을 만든다.
(IP는 실행중인 코드의 주소를 의미한다. PC와 동일)
위 다이어그램을 보면 .eh_frame에 함수의 start, size 에 대한 정보가 있다.
throw가 던져지면 IP를 해당 테이블에서 검색해서 어떤 함수인지 찾아내는 것이다.
이제 어떤 함수인지 알아냈으므로 어떤 지역변수들의 소멸자들을 호출해야 하는지를 알아야 한다.
여기서 문제가 발생하는데,
어디서 throw가 던져지냐에 따라서 소멸시켜야 하는 변수들이 달라진다.
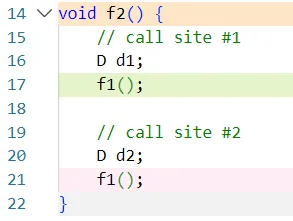
다음과 같은 함수가 있다고 보자.
위쪽의 f1() 함수에서 exception이 발생하면 d1의 소멸자를 호출해야하고,
아래쪽의 f1() 함수에서 exception이 발생하면 d1, d2의 소멸자를 호출해야 한다.
저런 범위를 call site라고 부르는데,
그러면 exception에서는 어떤 call site에서 호출되었는지를 알아내어
각기 다른 해제 루틴을 시행해주어야 한다.
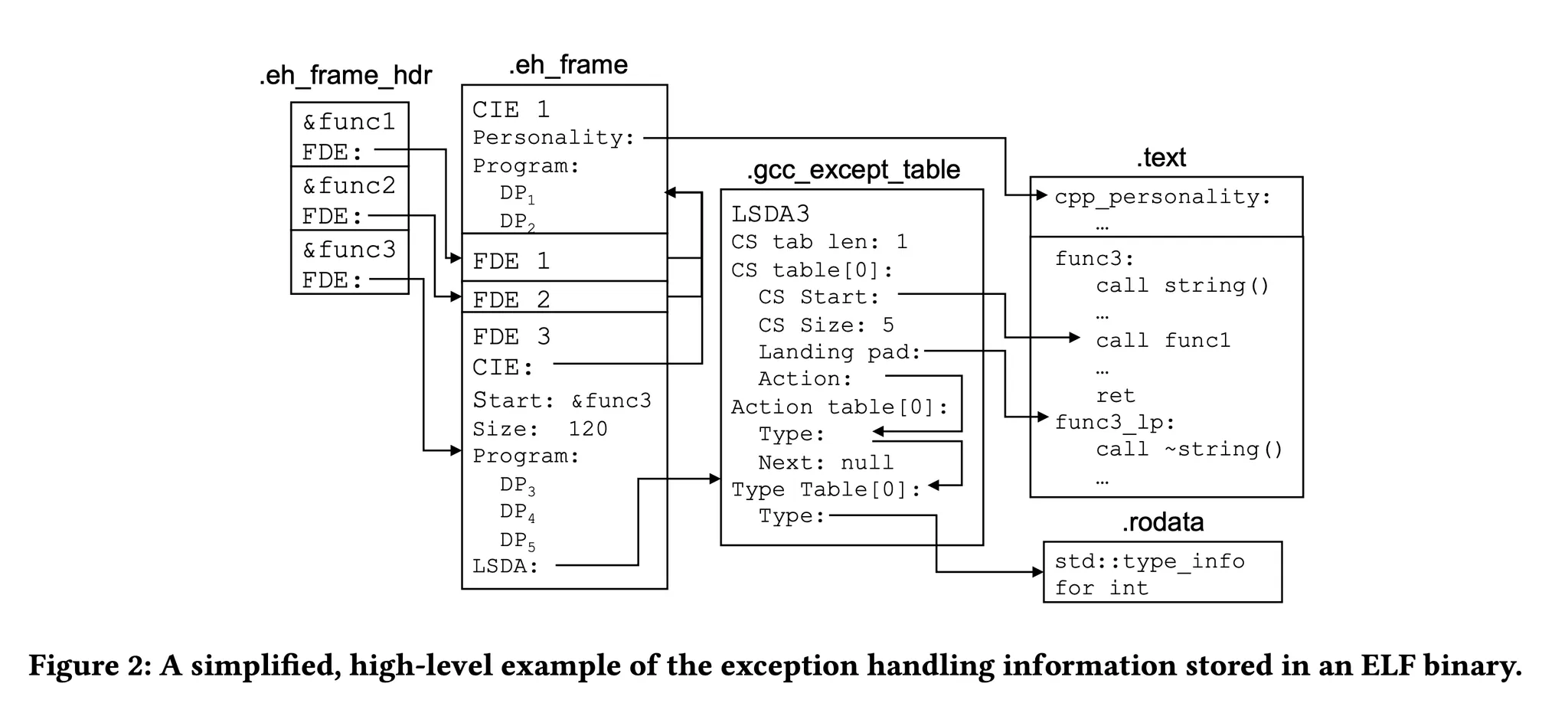
그래서 각 call site에 대한 주소 범위와 해제 루틴도 컴파일 테이블에 추가된다!
.gcc_except_table 섹션의 CS가 바로 아까 전의 call site이다.
몇 개의 call site가 있는지, 주소 범위가 어떻게 되는지,
어떤 해제 루틴을 수행해야 하는지(Landing Pad)
가 기록되어 있다.
정리하자면
컴파일타임 테이블에서 IP를 통해 어떤 함수이고 어떤 call site인지를 특정해내어
어떤 해제 루틴을 수행해야 하는지 찾아내는 것이다.
실제 컴파일 확인
실제로 저 방식대로 수행되는지 어셈블리를 뽑아보자.
다음과 같이 코드를 작성했다.
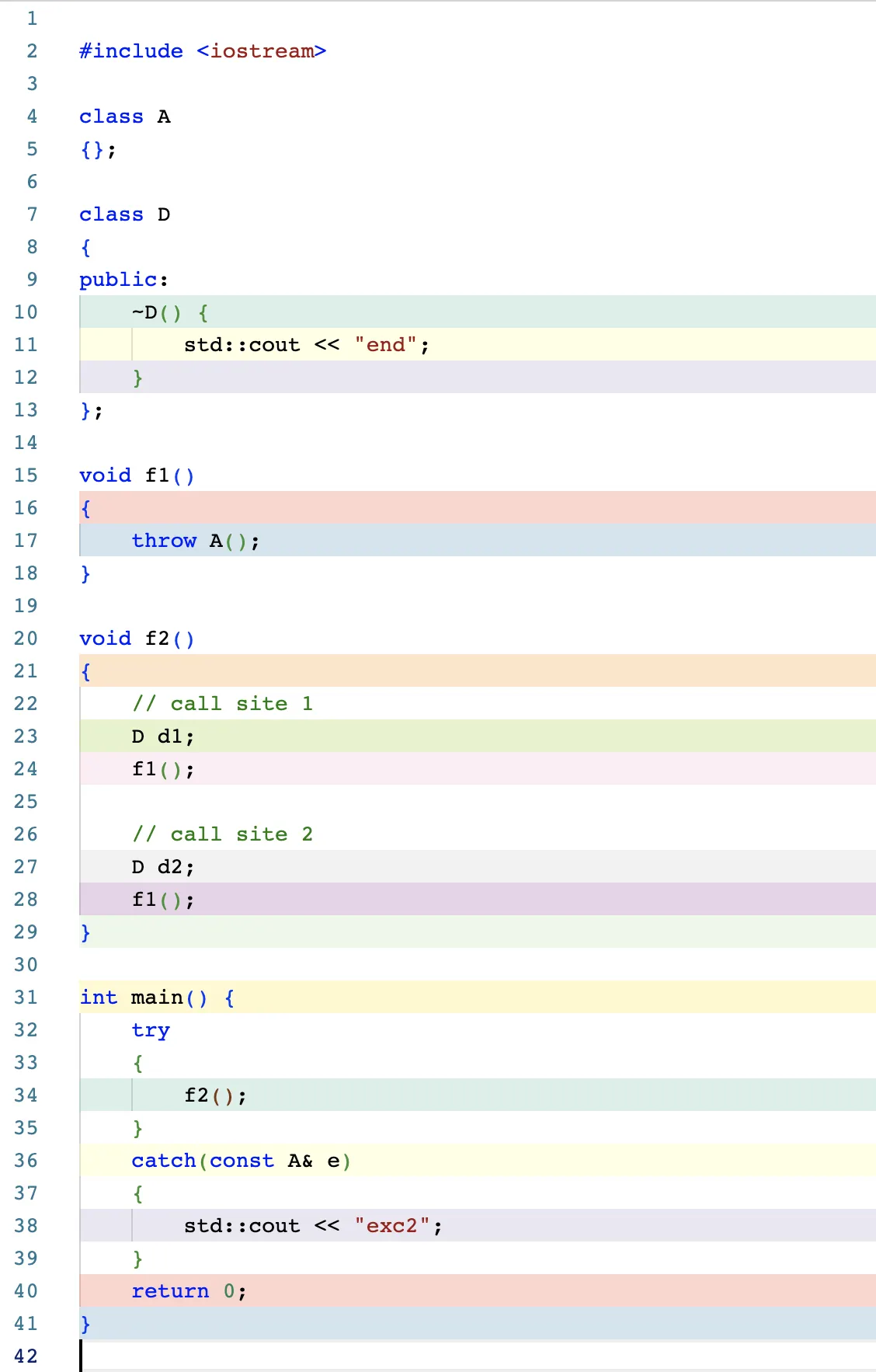
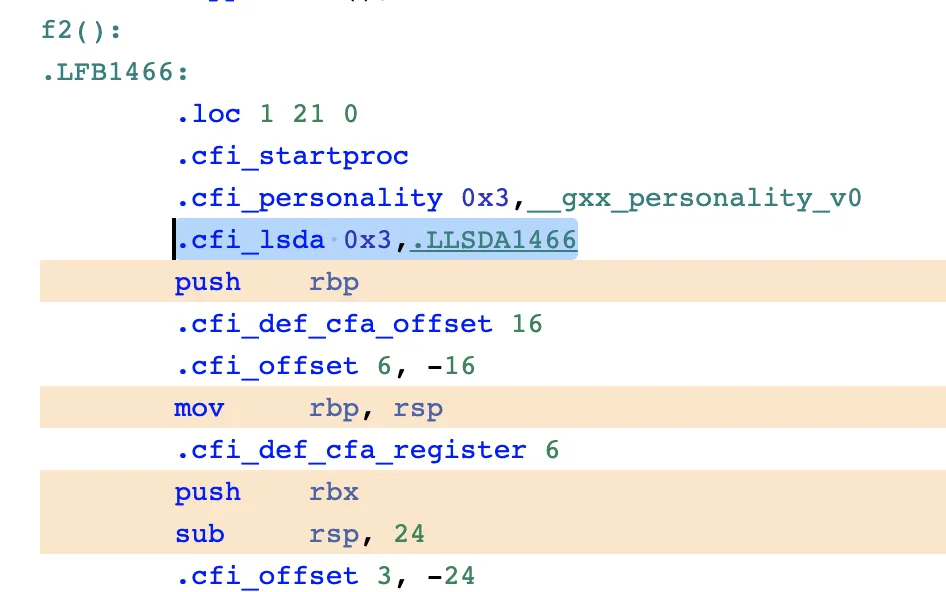
컴파일 결과의 f2() 부분의 함수 윗부분을 보니 함수 코드 이외에
이것저것 많은 정보들이 추가되어있다.
LSDA가 바로 call site에 대한 정보가 기록되는 테이블이다.
저 라벨을 따라가보자.

149-152 줄이 call site #1,
153-156 줄이 call site #2의 범위를 담고 있다.
151줄, 155줄이 해제루틴의 주소이다.
CS#1 해제루틴은 .L6,
CS#2 은 .L7이다.
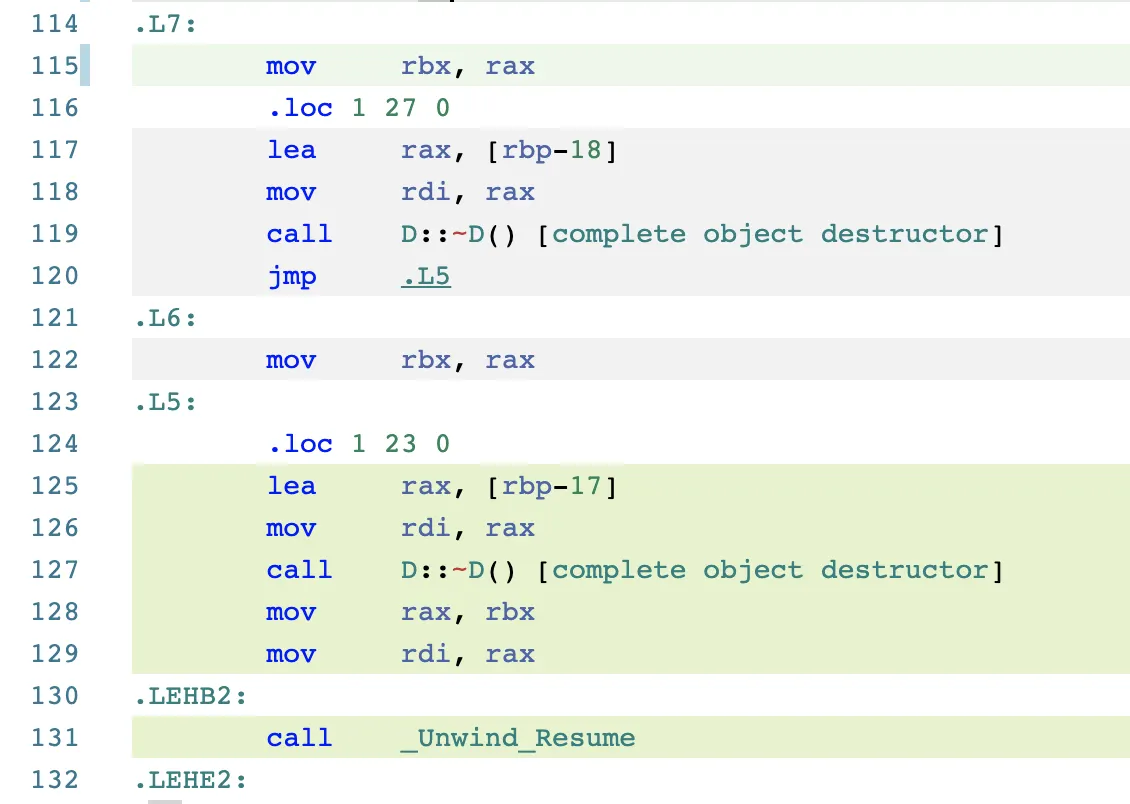
실제 .L6, .L7 라벨을 보니
L7 이 실행되면 두 번 D의 소멸자를 호출하고
L6 이 실행되면 한 번만 D의 소멸자를 호출하는 것을 최종적으로 확인할 수 있다.
Exception type check
추가로
catch를 찾아 올라갈 때 catch를 하는 타입과 throw를 한 exception의 타입이 일치하는지 확인해야 하는데
이를 위해 type에 대한 정보 또한 테이블로 만들어져 있다.

정리
exception은 마법이 아니다. 정말 복잡하다.
1번 방법을 사용하는 컴파일러라면 exception을 사용하는 것 만으로 오버헤드가 있고
2번 방법도 정말 큰 사이즈의 테이블이 필요하기 때문에 코드 크기가 증가하며
둘 다 exception이 발생되면 많은 cost를 지불해야 한다.
따라서
현재 내가 사용하는 환경이 어떤 exception 구현인지 확인한 뒤 사용해야 하고
최대한 exception이 발생하지 않도록 해야한다.
많은 대형 C++ 프로젝트에서 exception을 아예 끄는 경우도 많으니
아예 꺼버리는 결정도 고려해야.
어쨋든 if를 대신해서 try/catch를 사용한다면 때려도 무죄.
컴파일 결과는 아래 링크에서 직접 확인할 수 있다.
https://godbolt.org/z/Yjrx8eTv3
Reference
Compiler Internal (hex-rays)
https://itanium-cxx-abi.github.io/cxx-abi/abi-eh.html (zero-cost table은 itanium ABI에 기술되어있다)
Clang exception source code
