

 발단
발단
strncmp코드에서 const char를 unsigned char로 형변환해서 계산하는 부분이 있다.이 부분에서 확장아스키가 들어올 수 있기 때문에 unsigned char를 사용해야한다고 설명했는데 이 설명만으로는 부족한 것 같아 동료들과 토론을 해보았다.
이 글을 이해하기 위한 기본지식
char형과 unsigned char형char과 unsigned char형은 모두 1byte(8bit)를 사용해서 표현한다.ㅁㅁㅁㅁ ㅁㅁㅁㅁ => 1bytechar형은 부호표현이 있으니 -128~127까지 unsigned char형은 부호표현이 없으니 0~255까지 표현할 수 있다
unsigned char와 char형은 어떻게 다를까
그럼 char형에 확장아스키코드 값(128~255)를 넣으면 어떻게 될까?일단 컴파일할수 없다.
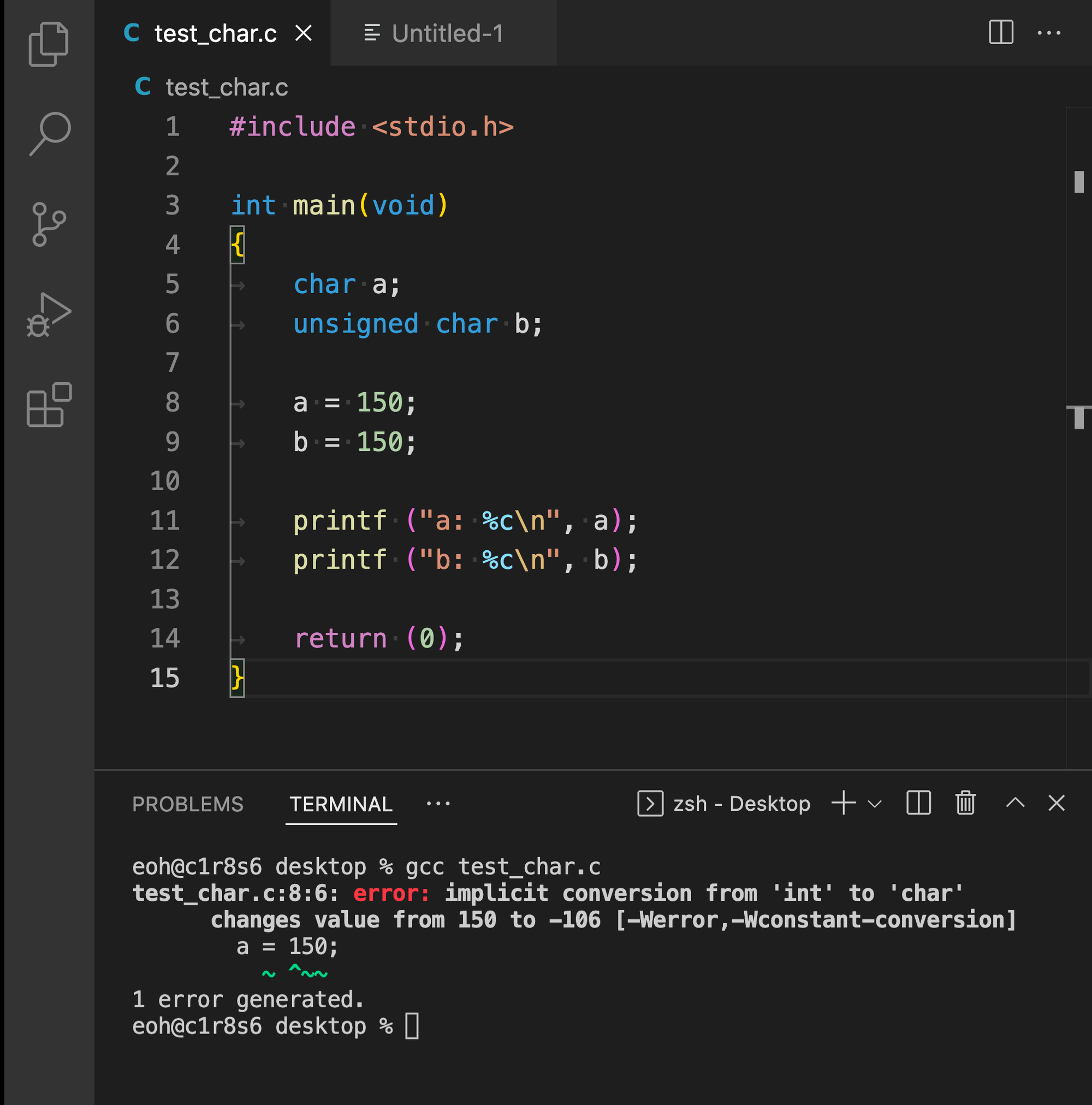
컴파일 되지 않고 오버플로된 값을 알려주는 모습
그런데 컴파일러에서 150대신 -106을 넣으라고 추천해준다.8비트에 150을 넣었을 때 오버플로난 값을 계산해보면 -106이다. 이 뜻은 비트수가 똑같다는 뜻이다.150을 8비트로 계산했을 때도 10010110-106을 8비트로 계산했을 때도 10010110 이 된다.그럼 char a = -106인 값을 출력했을 때, 확장아스키150의 값을 얻을 수 있을까?
터미널에서 확장아스키코드 지원을 하지 않아 조건문을 이용해 출력했다.
a와 b가 같을 때 출력하라고 조건문을 주었는데 출력하지 않고 다를 때 출력하라는 조건문에서는 무언가 출력이 되었다. a와 b는 다르다는 뜻이다. 비트수는 같은데 왜 다를까?
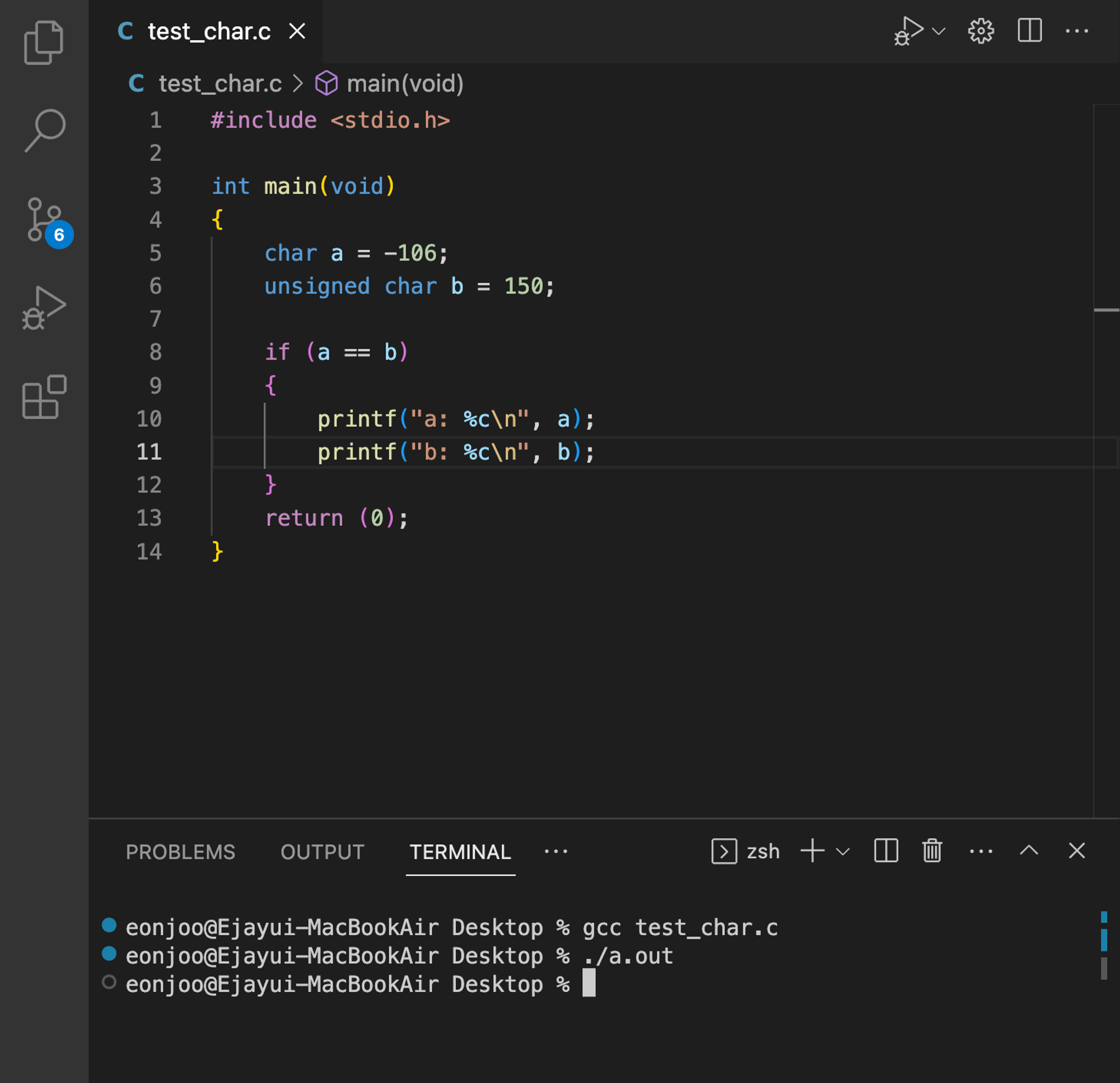
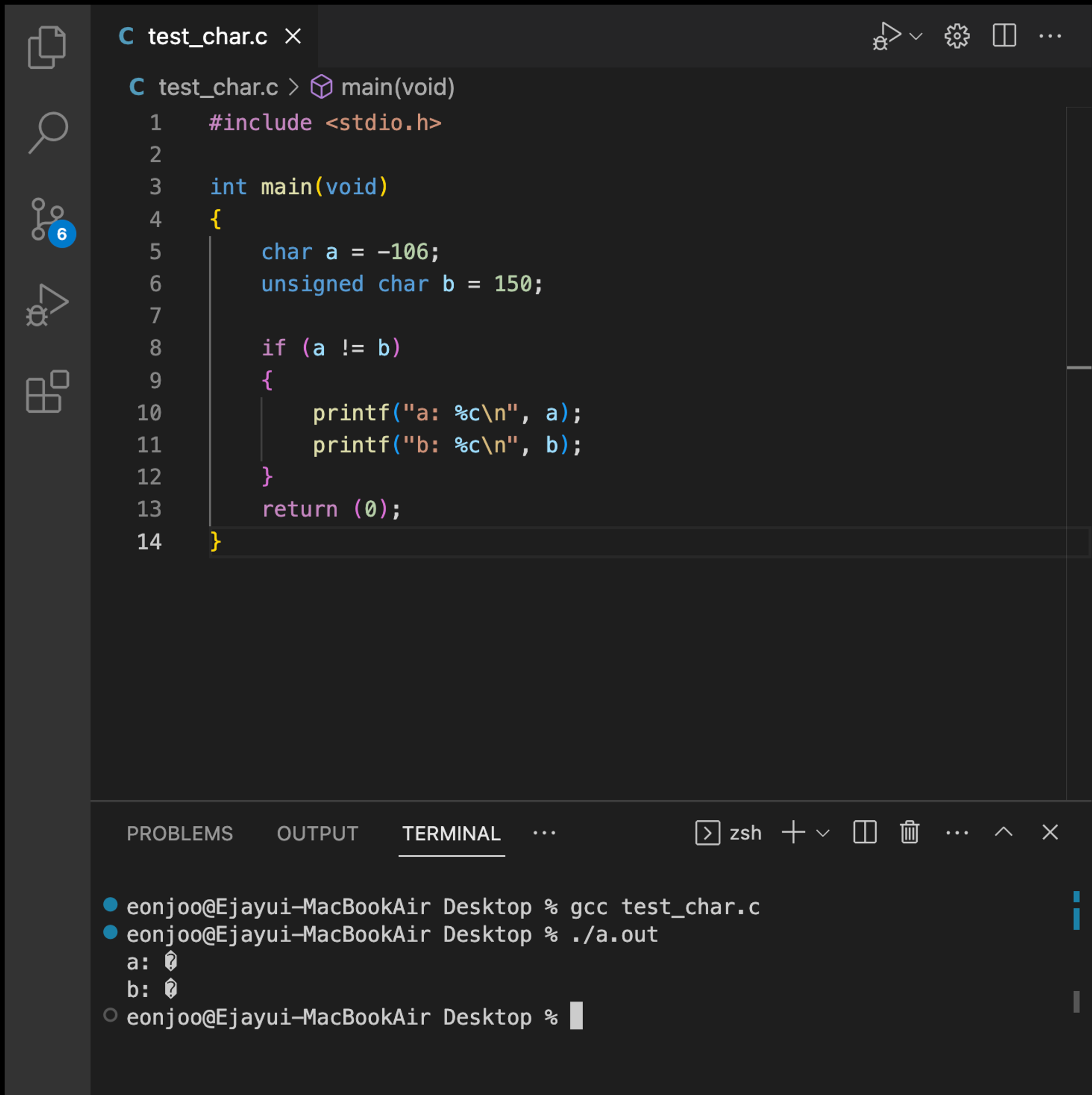
char형과 unsigned char형에 같은 비트값을 넣어서 출력한 모습
� 이 기호는 대체문자로 텍스트 인코딩, 디코딩이 잘못되었을경우 표시된다.a에서 출력된 �기호는 -106에 대응하는 아스키코드 값이 없다는 것을 의미하고b에서는 확장아스키는 표준이 아니므로 터미널에서 출력값과 매칭할 수 없어 출력이 불가능하다는 의미이다.
❗️부호 판별의 차이
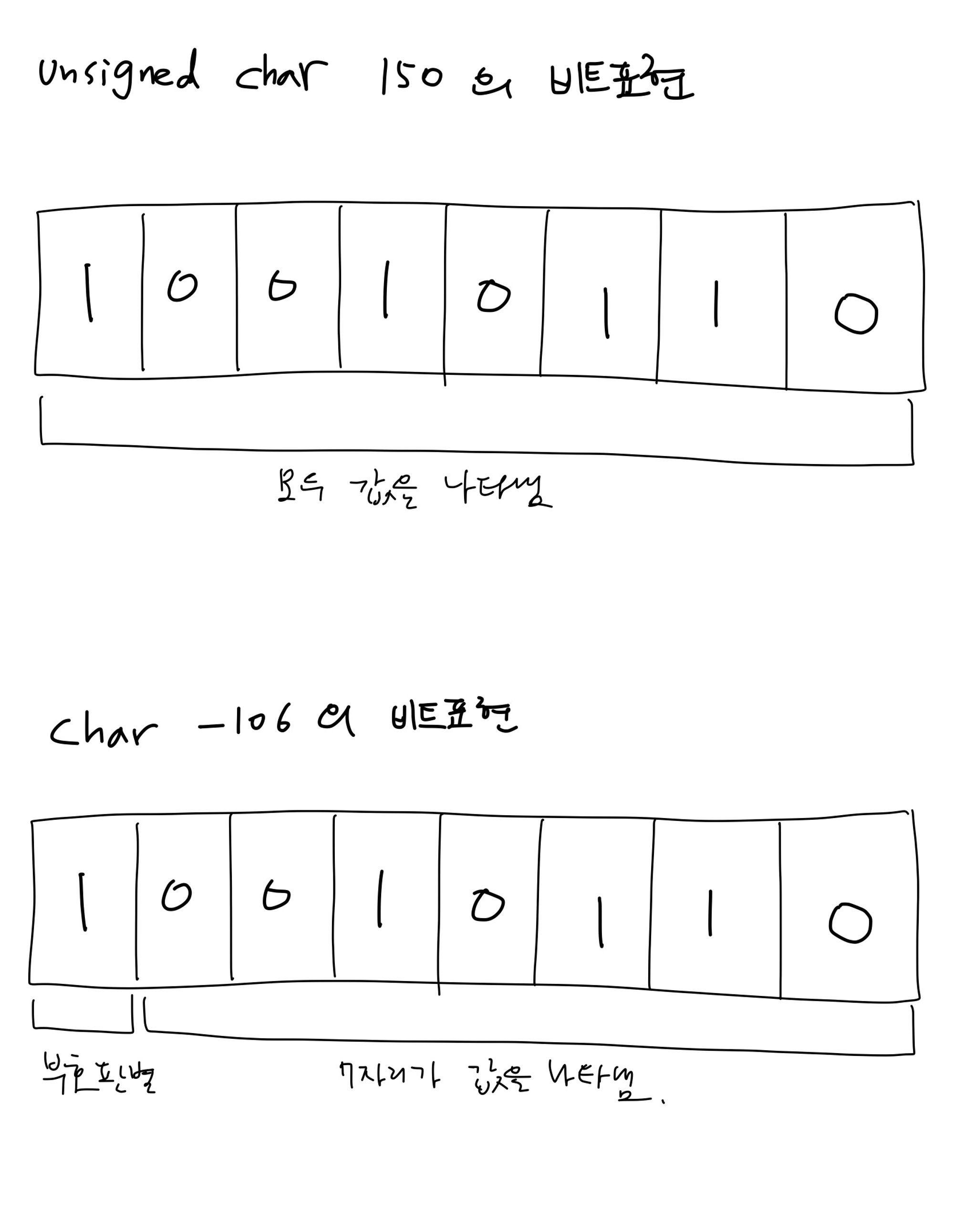
자료형이 부호를 판별하느냐가 가장 큰 차이이다.
부호가 있으면 부호를 나타낼 비트가 필요하고 제일 왼쪽에 있는 비트를 부호를 판별하는데 사용한다. 맨 앞 비트가 1이면 -부호, 0이면 +부호로 판별된다.똑같이 비트가 찍혀있어도 char형에서는 부호비트 자리에있는 부호를 먼저 판별하고 데이터는 7비트로 판별하기로 프로그래밍이 되어있고,unsigned char형에서는 별도의 부호 판별없이 8자리 모두 데이터로 판별하기로 되어있다.
말로 설명하면 헷갈리는데 아래 그림을 보면 이해하기 쉬울 것이다.
더 나아가서
그렇다면 int형으로 형변할때는 문제가 없을까?
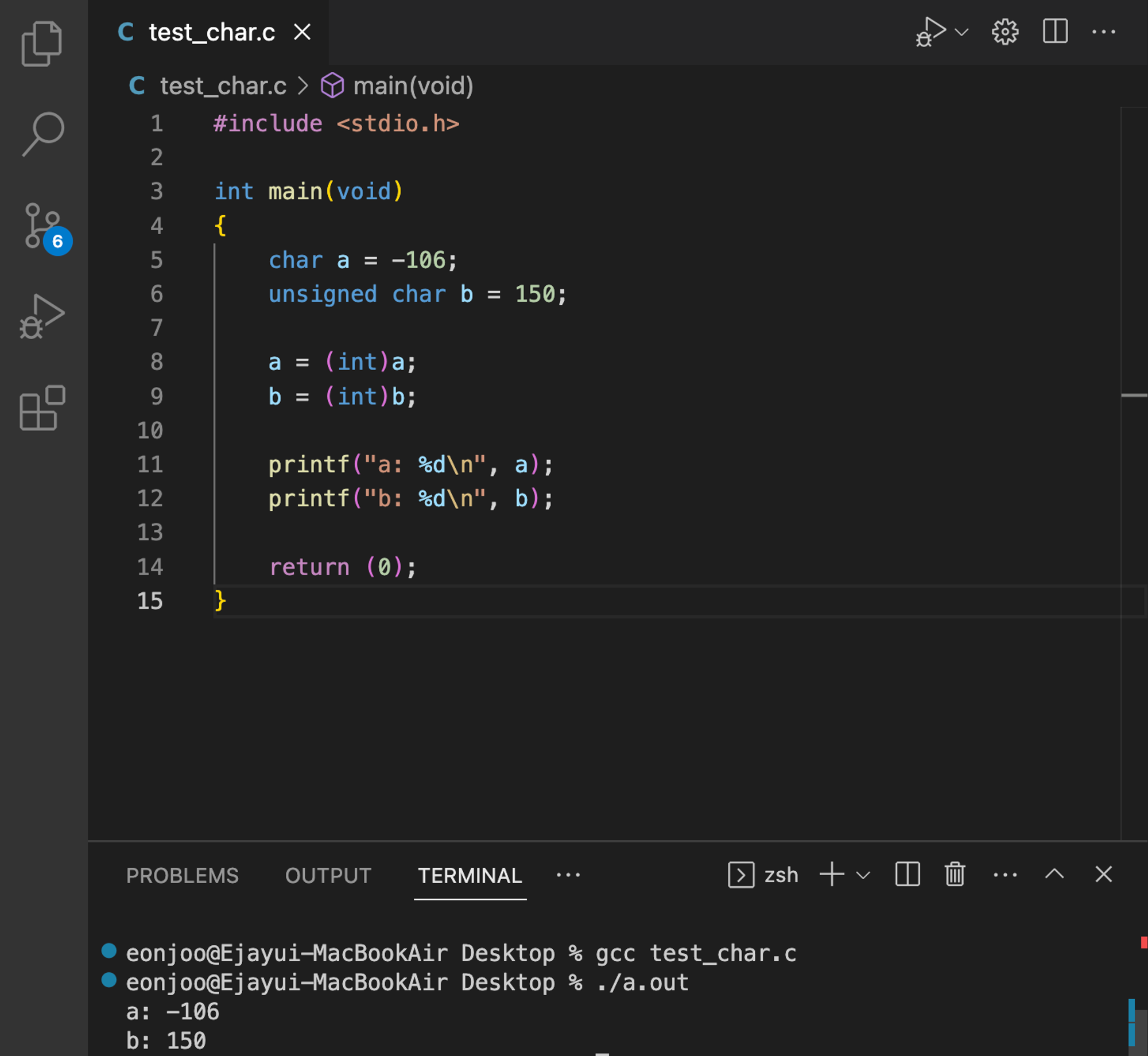
char, unsigned char 타입을 모두 int타입으로 변환해보았다.
형변환도 그대로 잘 된다.비트 수가 같은데 왜 잘될까?
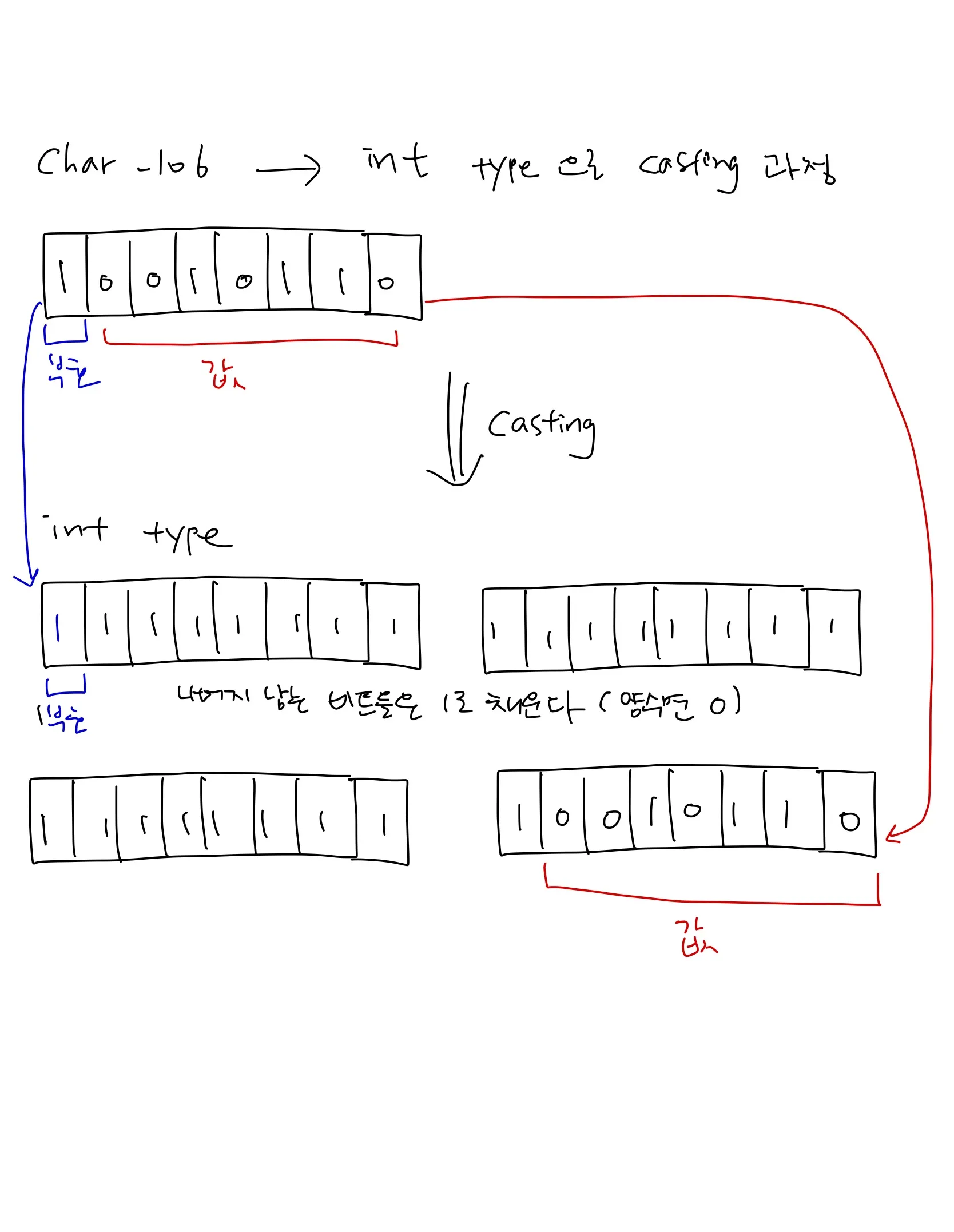
int형은 4byte(32bit)로 표현되고 부호를 가지기 때문에 가장 왼쪽 비트가 부호비트이다.
char형도 부호를 가지기 때문에 char형이 int형으로 변환될 때 가장 먼저 부호비트를 가져온다. 그리고 남는 자리에는 부호비트와 똑같은 비트로 채우고 데이터를 판별하는 값을 채운다.
unsinged char형은 부호를 판별하는 부분이 없으므로 남는 비트는 모두 0으로 채운다.
예시로 문자열을 비교해 그 아스키코드 값의 차이를 내뱉는 strncmp의 구현코드에서 char의 값의 차이를 계산할 때 unsigned char형으로 형변환을 한 다음 계산한다
(unsigned char)s1[i] - (unsigned char)s2[i]);
C
복사
일단 char형끼리 산술연산을 하면 자동으로 int형으로 변환해서 계산한다. 이 과정에서 문자열 만약 확장아스키코드의 값이 들어와있다면? 오버플로 난 값으로 형변환이 되어 잘못된 계산이 나올 것이다.
예를 들어 문자열에 Û(확장아스키 코드 150번)이 담겨있을때 unsigned char형으로 형변환을 하지않으면 오버플로가 나 char형에 -106의 값으로 담겨있을 것이고 산술연산이 일어나면서 int형으로 변환할 때도 150이 아닌 -106으로 계산이 되어 값이 달라진다.
결론
같은 비트 수라도 데이터타입에 따라 처리하고 받아들이는 방식이 달라서 데이터 타입이 중요하다.
