



Fetch & Decode to uop Execution units
(superscalar 4way)
+----+ +---+---core0--+ +--------+ +------------+ +-------+
|DRAM| sys |L3 | L2 | L1-I|------> |re-order| -/> |Reservation | -uop> |mul,div|
| | bus | | | L1-D| |--> |buffer | |station. | +-------+
| | --> | | | + BH| |--> | | | | -uop> |add,sub|
| | | | | | |--> | | | | +-------+
| | | |---core1--| +--------+ | - - - - - -| -uop> |store. |
+----+ +---+----------+ | | Register | +-------+
| +------------+ -uop> |load. |
| | +-------+
| | | |
+----------------+---------------+ |
Internal data bus |
+-------+
|L1-DATA|
(by hyunjunk) +-------+
C++
복사
system bus → 메모리 컨트롤러나 DMA 컨트롤러가 캐시까지 프로그램을 가져옴
L1-cache → non-temporal 같은 캐시를 거치지 않는 특수한 상황이 아니라면,
기본적으로 모든 데이터와 코드는 연산되기 전에 L3-L2을 거쳐 L1까지 fetch 되어야 함.
instruction과 data를 동시에 fetch하기 위해 I-cache와 D-cache로 나뉨 + Branch History도 여기에 저장
fetch → 캐시에서 cpu 버퍼로 읽어옴
superscalar → 이 때, 하나씩 fetch 하면 느리므로 n개씩 한꺼번에 읽어들임
(만약 branch prediction이 실패해서 파이프라인을 flush하면 빠르게 명령어들을 다시 채울 수 있어야 함).
+(뒤의 파이프라인 과정도 여러개씩 한꺼번에 진행하는데, skylake architecture를 보면 책에서 나오는 것 처럼 단계별로 슈퍼스칼라 개수가 n개씩 고정인게 아니라 멋대로임)
decode → 명령어를 해독함. cisc 명령어는 길이가 가변적이라 복잡.
risc의 고정길이 명령어셋 인 경우 간단하여 fetch-decode를 한 번에 진행하기도 함.
+ cisc 명령어는 복잡해서 pipelining 하기 힘듬(한 명령어가 execution stage를 점유하는 시간이 김).
그래서 작은 단위인 uop(micro operation)으로 변환
re-order buffer → out-of-order 프로세서에서 필요한 버퍼.
의존성 등을 보고 re-order 시킴. 이 때 rename도 진행 (가짜의존성 제거)
reservation station → uop들이 의존성이 없어지거나 execution unit이 not busy 할 때 까지 대기.
execution units → 실행 유닛. 각 실행 유닛 별로 기능을 분리해서, 병렬적으로 돌릴 수 있도록 함(설계마다 다른 듯)
internal data bus → 레지스터 값 load나 레지스터에 store를 지원.
execution 까지 끝나면 →
writeback + forward-operand로 대기중인 다른 uop을 깨우고 기다리던 결과를 가져다주거나,
commit하여 실행결과를 확정(레지스터나 캐시에 저장)
commit이 존재하는 이유는 page protection 등을 검사하고 결과를 취소할 수 있어야 하기 때문.
더 자세한 다이어그램은 여기
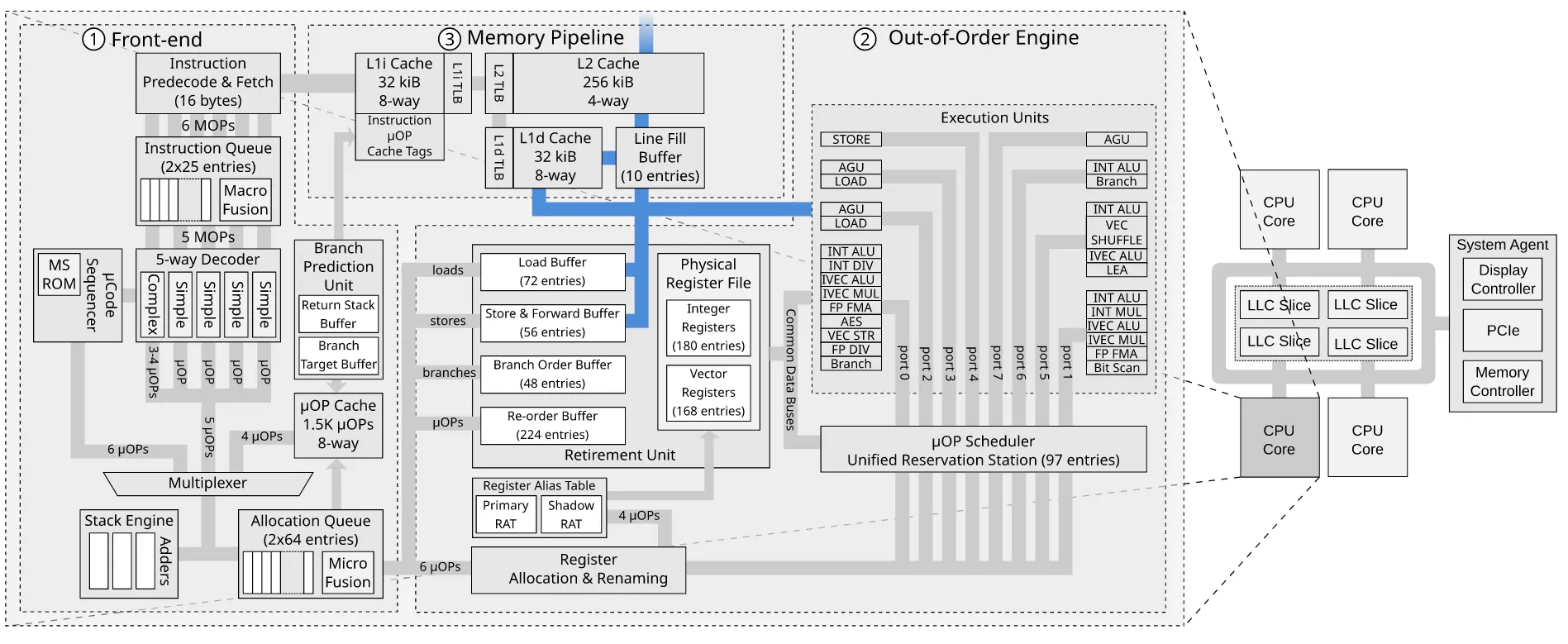
full overview of the Intel Skylake microarchitecture.
중간에 load buffer나 saves buffer 같은 것들이 있는데 이게 뭐 하는지 잘 모르겠음.
내 생각에는 투기적 실행을 하고 실패 시 rollback 하려고 버퍼를 따로 두는 듯 ?
Line Fill Buffer는 WC buffer임 이름이 바뀐 듯
