



멀티 코어 CPU에서, 두 개의 코어가 같은 메모리 라인에 write 작업을 수행 할 경우
코어마다 로컬 캐시의 내용이 다르게 되어버리는 문제가 생긴다.
(캐시 메모리는 코어끼리 공유하는 캐시와 코어마다의 독립적인 캐시가 레벨로 나누어진다)
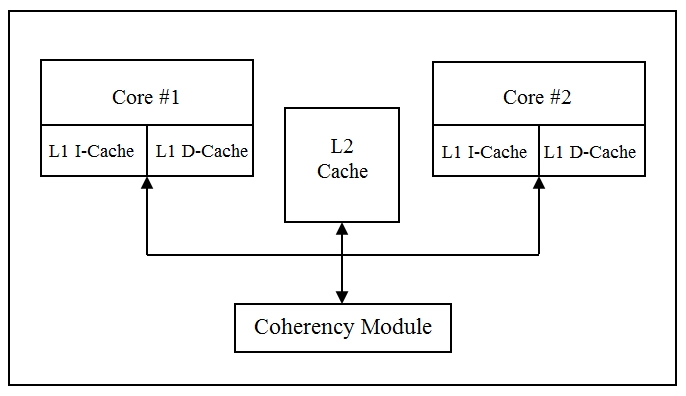
이를 해결하기 위해서 하드웨어에서 Cache-Coherence(캐시 일관성)을 지원하는데,
주로 MESI Protocol 이란 방식에서 Bus Snooping 을 사용한다.
.png&blockId=a1c28aa2-45fd-40fb-a091-c01509fb98a2)
Bus Snooping을 간단히 설명하자면 캐시에 write 작업을 수행 할 때마다 다른 코어들에게 브로드캐스트 한다.
다른 코어들은 이 신호를 받고 자신의 로컬-캐시 내에 같은 주소를 들고 있다면 무효화 시키고,
무효화 시킨 라인을 사용 할 때에는 최신 데이터를 들고 있는 코어에게서 캐시간 전송으로 데이터를 받는다.
(착각할 수 있는게, 이렇게 캐시를 일관화 시키면
race condition도 해결되어야 하는것이 아닌가 싶지만,
CC는 쓰기-읽기 순서를 보장하는 것이라, 명령어가 atomic하지 않다면 race condition이 발생할 수 있고
race condition은 캐시를 사용하지 않는 경우에도 발생하므로 해결되지 않는다.)
여기서 의문점이 생겼는데, 같은 캐시라인에서 두 개의 코어가 같이 write 작업을 수행한다면
Cache-Coherence를 위해 많은 비용이 들텐데, 하나의 코어가 write 하는 것 보다 느리지 않을까?
enum {
CACHE_LINE = 64,
ITER_NUM = 1000000000,
};
alignas(CACHE_LINE) volatile char arr[CACHE_LINE];
// Same cache-line 2-therad write
thread a([&]()
{
for (int i = 0; i < ITER_NUM / 2; i++)
{
arr[0] = 1;
}
});
thread b([&]()
{
for (int i = 0; i < ITER_NUM / 2; i++)
{
arr[CACHE_LINE - 1] = 2;
}
});
C++
복사
같은 캐시라인에 스레드 2개가 총 10억 번 write 하도록 테스트를 작성
하나는 스레드 2개가 서로 다른 캐시라인에 5억 번씩 write를 한다
스레드 1개가 10억번 write하는 경우도 추가
Intel® Core™ i7-8700K
CACHE_LINE - 64byte
1. Same cache-line 2-thread write : 376430100ns
2. Different cache-line 2-thread write : 119981200ns
3. Just single-thread write : 232743700ns
C
복사
테스트에 문제가 있을 수도 있지만, 가설이 맞는 것 같다
같은 캐시라인에 스레드 2개가 분담해 write 하면 엄청 느려진다.
그냥 하나의 스레드가 write 하는게 더 빠르다.
•
알고보니 이걸 false sharing 이라고 하는 모양이다 ㅡ_ㅡ;;;
