Subject
1. 문제 해석
2. 새로운 접근 - 선형 메모리
3. 결론 - locality
1. 문제 해석
1 - 1) push swap이란?
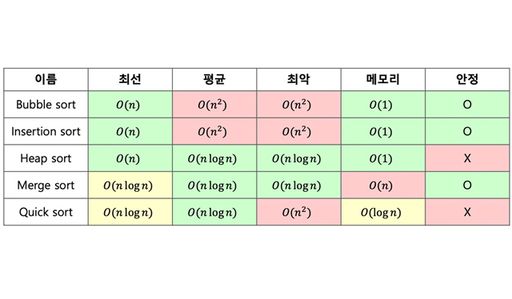
0을 포함한 양의 정수를 원소로 하는 두 스택 a, b에 대하여, 주어진 조작 방식 만을 활용하여 a의 원소를 모두 오름차순으로 정렬하는 문제이다. 이 때 최대한 적은 회수로 스택을 조작하여 정렬하는 것을 목표로 한다.
문제에서는 스택(stack)이라 칭하지만, 이후 소개할 내용에서 보면 스택의 top 뿐만 아니라 bottom에도 접근이 가능하므로, 사실상의 덱(deque)라 보아야 할 것이다.
1 - 2) command
문제에서는 제한된 방식으로만 스택을 조작할 수 있게 하는데, 이를 커맨드라 한다. 커맨드는 push(a, b), swap(a, b, all), rotate(a, b, all), reverse rotate(a, b, all)의 4부류, 총 11종이 존재한다. 이는 다음과 같다.
•
push
•
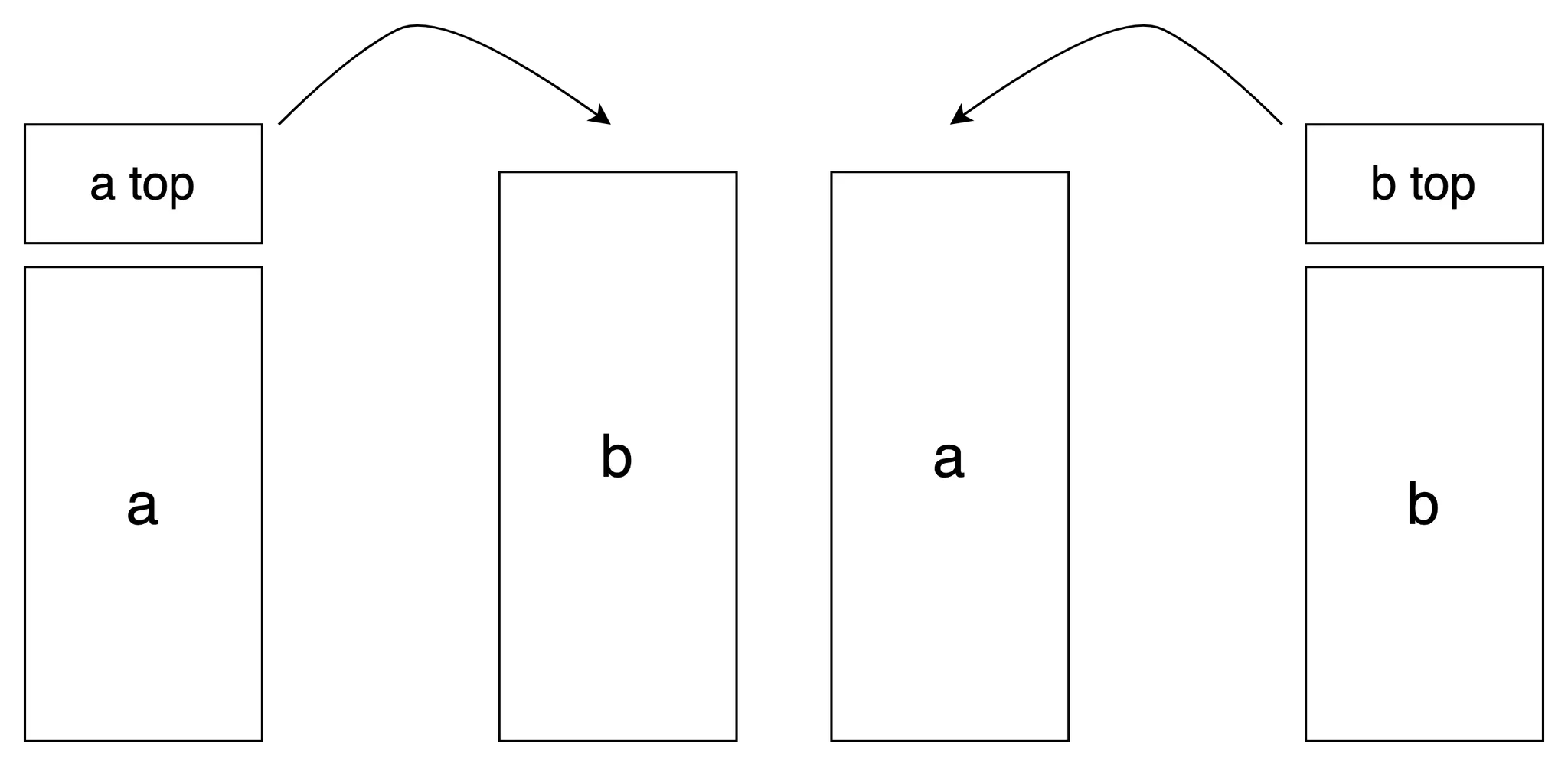
swap
•
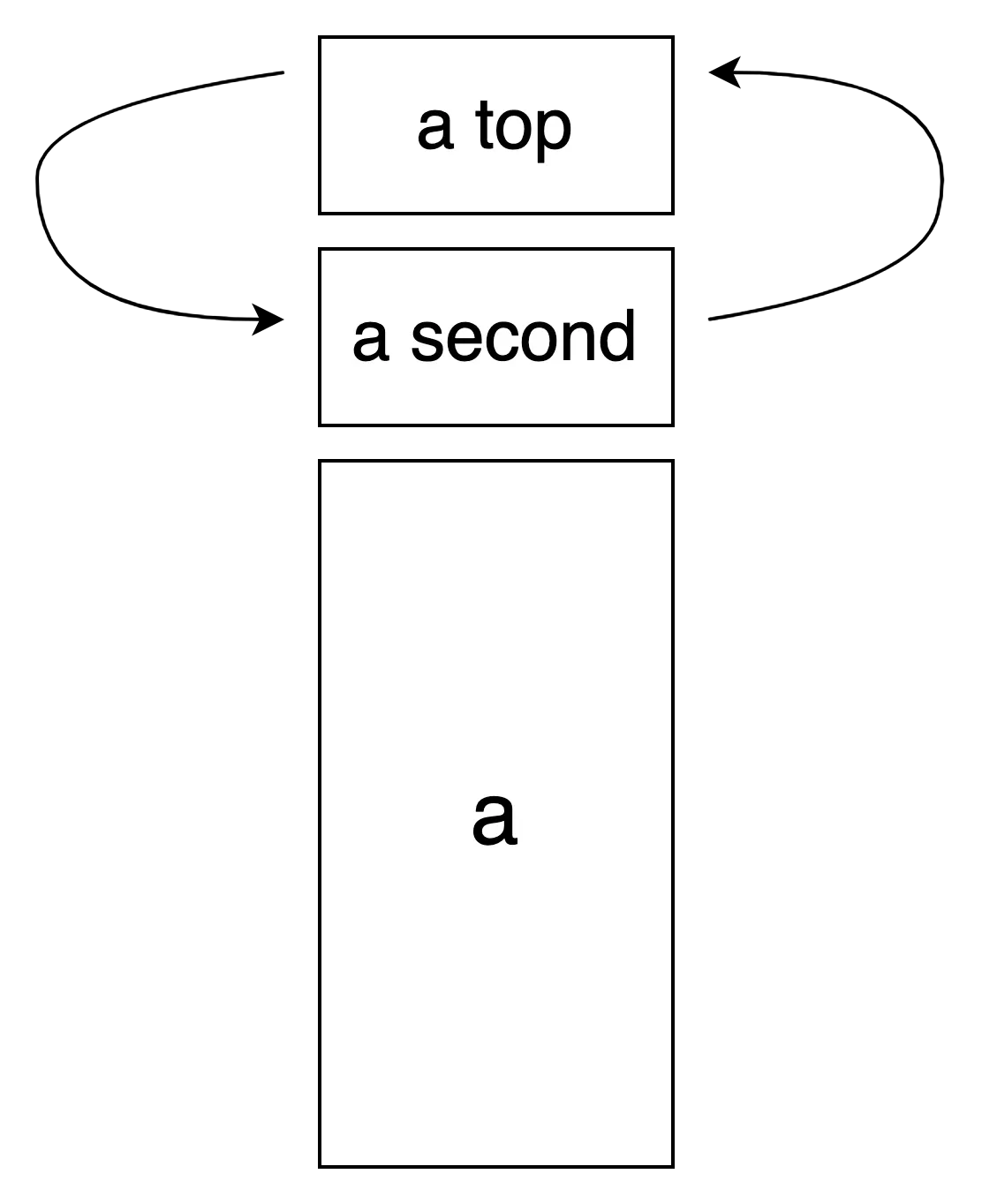
rotate
•
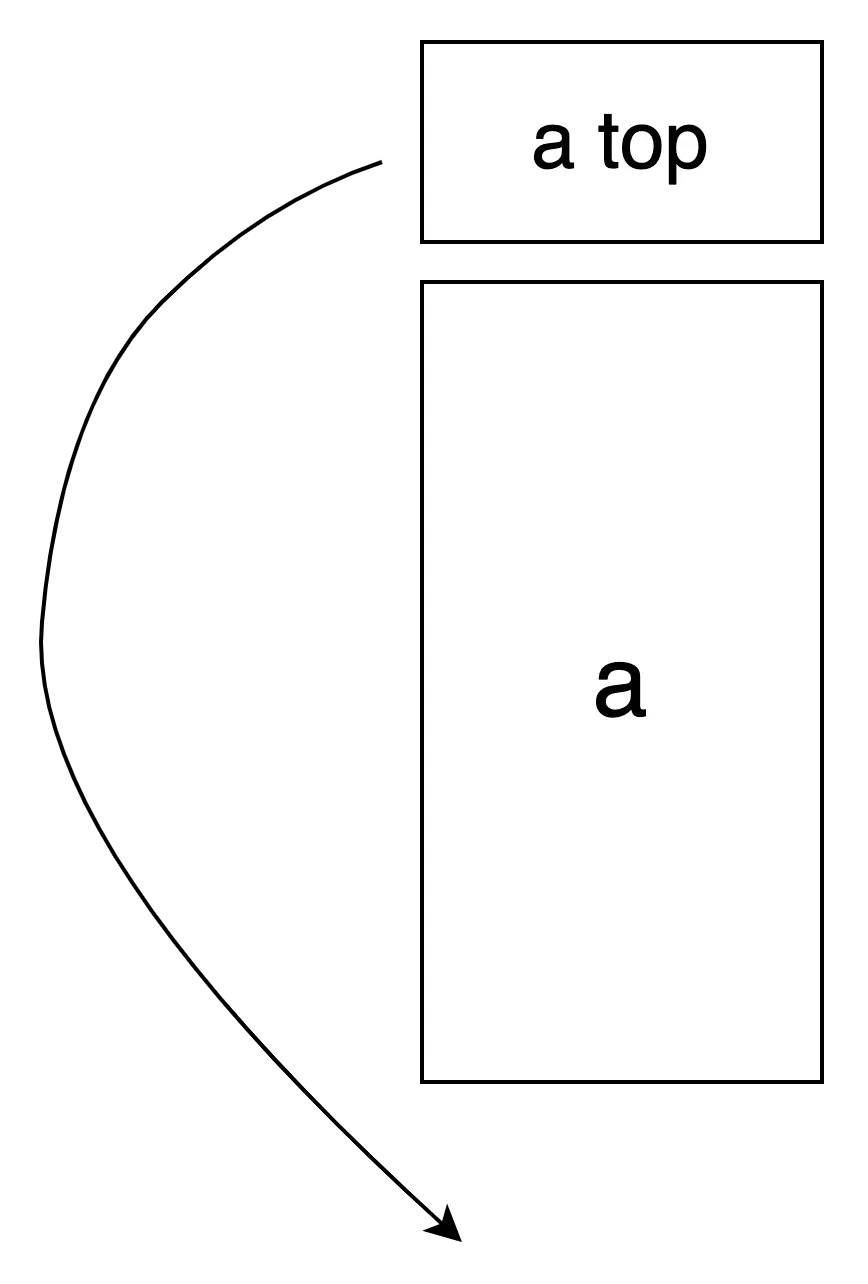
reverse rotate
2. 새로운 접근 - 선형 메모리
2 - 1) 두 스택을 하나로
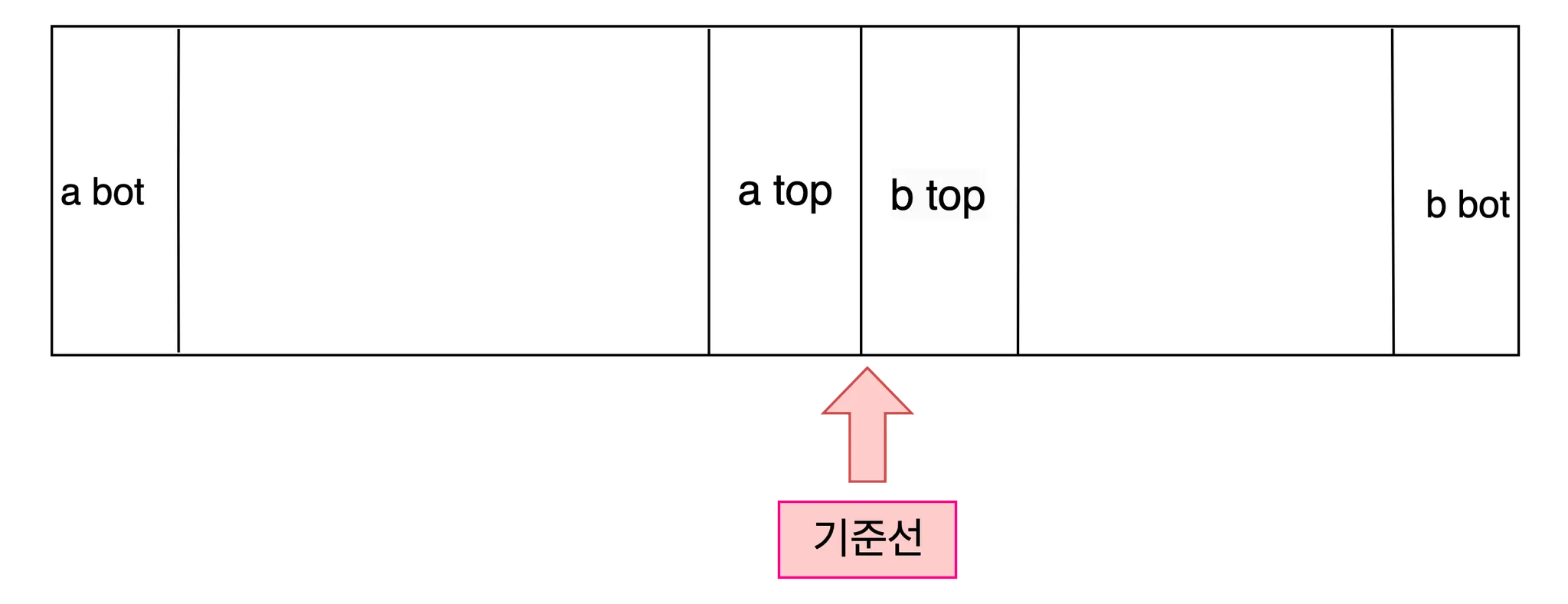
해당 문제의 어려움 중 하나는 비 직관성이다. 일반적인 환경에서의 정렬은 모두 선형, random access가능한 메모리를 대상으로 수행한다. 문제에서 요구하는 상황인 둘로 분절된, 심지어 특정 위치에만 접근 가능한 상황은 대단히 당황스럽다. 따라서 문제의 상황을 보다 이해하기 쉬운, 연속된 하나의 선형 메모리로 만들어보자.
두 스택 a, b에 대하여 서로의 top을 이어붙여서 하나의 메모리 덩어리로 만든다. 그 결과는 다음과 같다.
2 - 2) command의 새로운 구현
a, b의 관계가 변하였으므로, 기존의 커맨드들도 새로운 의미를 갖는다. 따라서 다음과 같이 새롭게 표현된다.
•
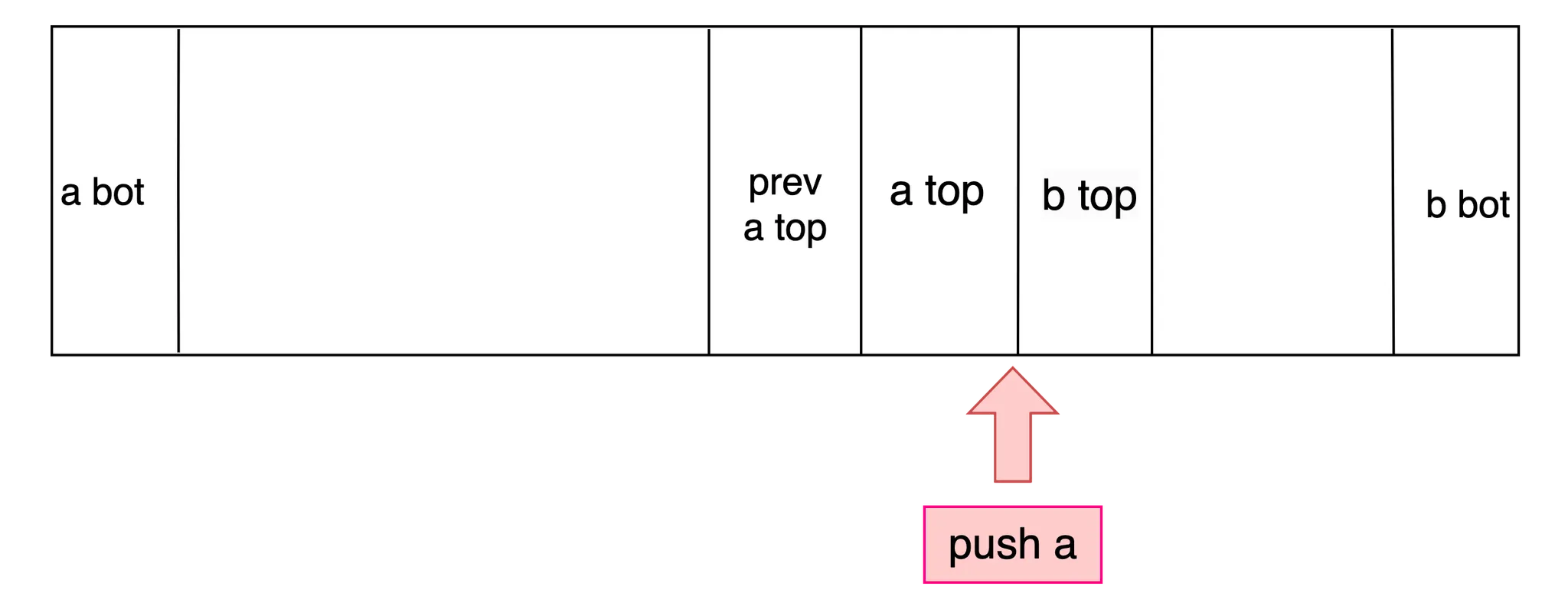
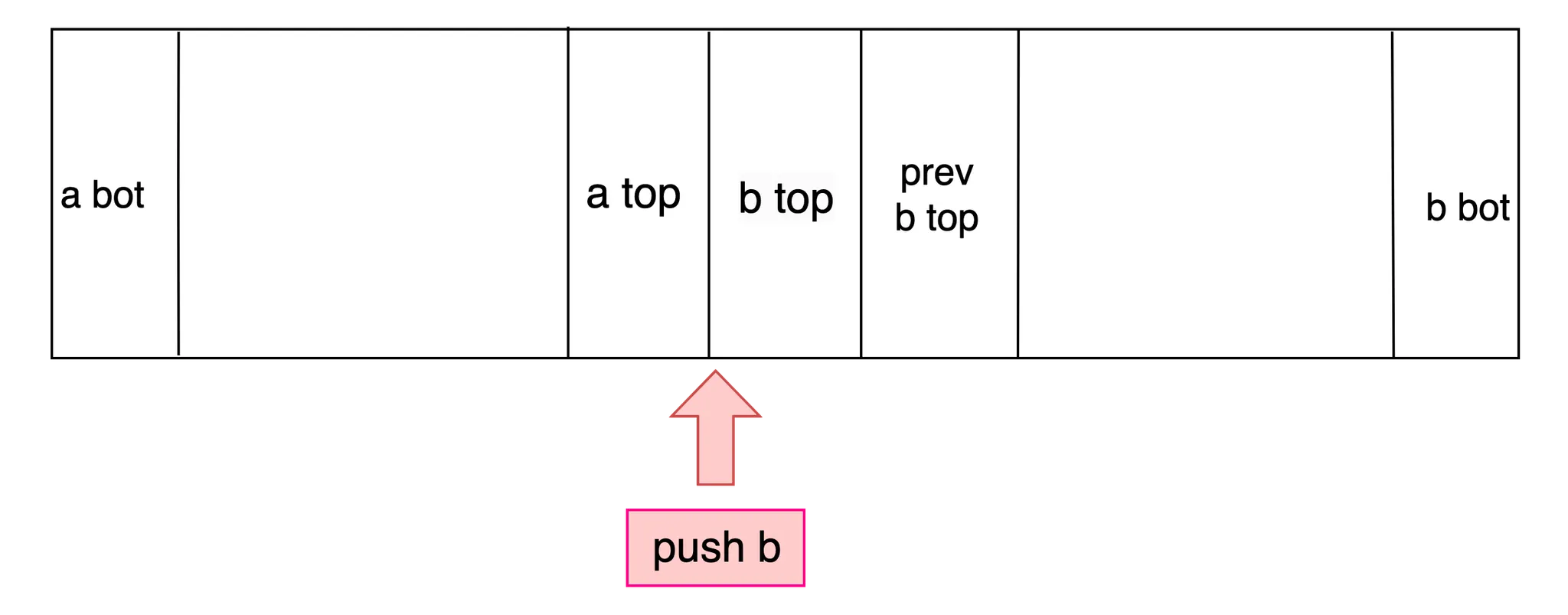
push
두 스택의 top이 붙어있으므로, push 계열 명령어는 두 스택을 구분짓는 가상의 선(이하 기준선)을 이동시키는 것으로 구현된다. 즉 실질적인 데이터의 이동은 발생하지 않는다.
•
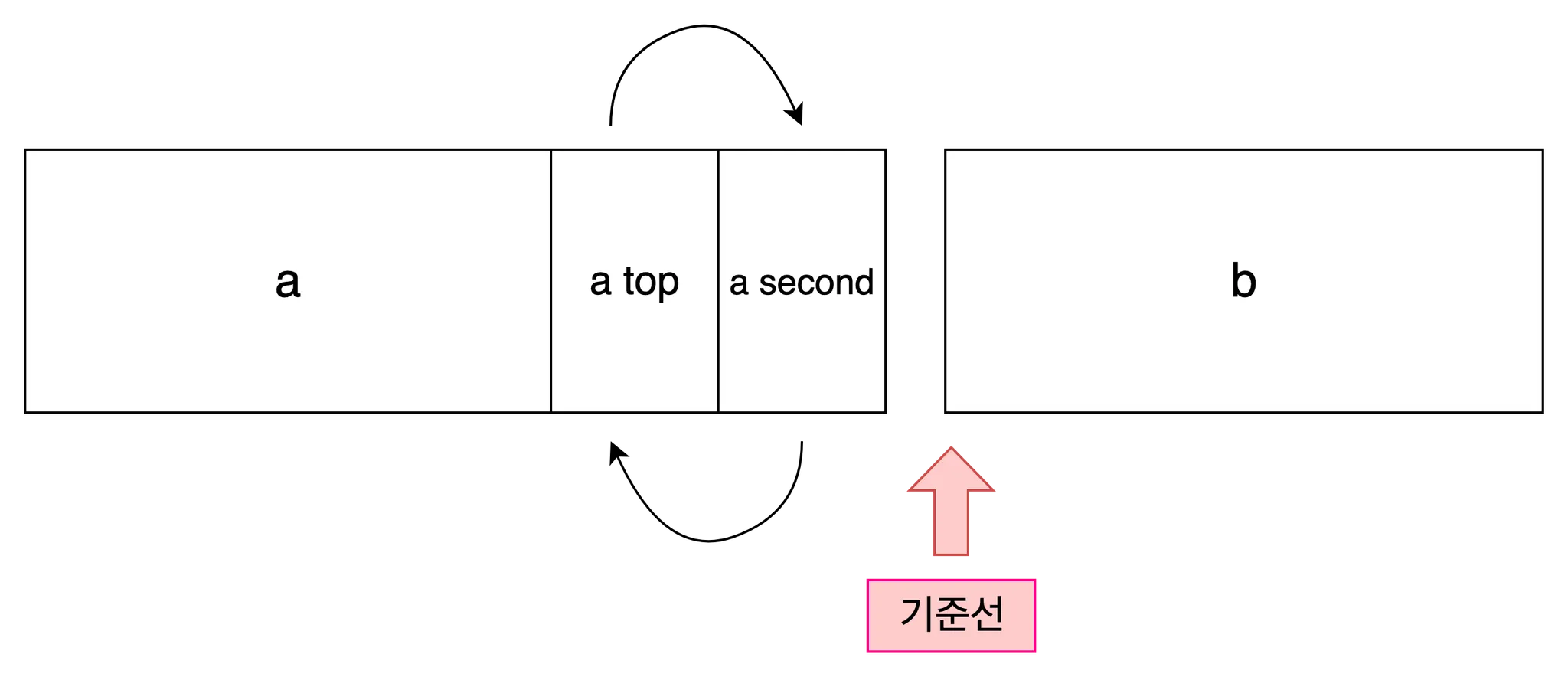
swap
swap은 기준선 좌, 우의 두 원소를 swap한다.
•
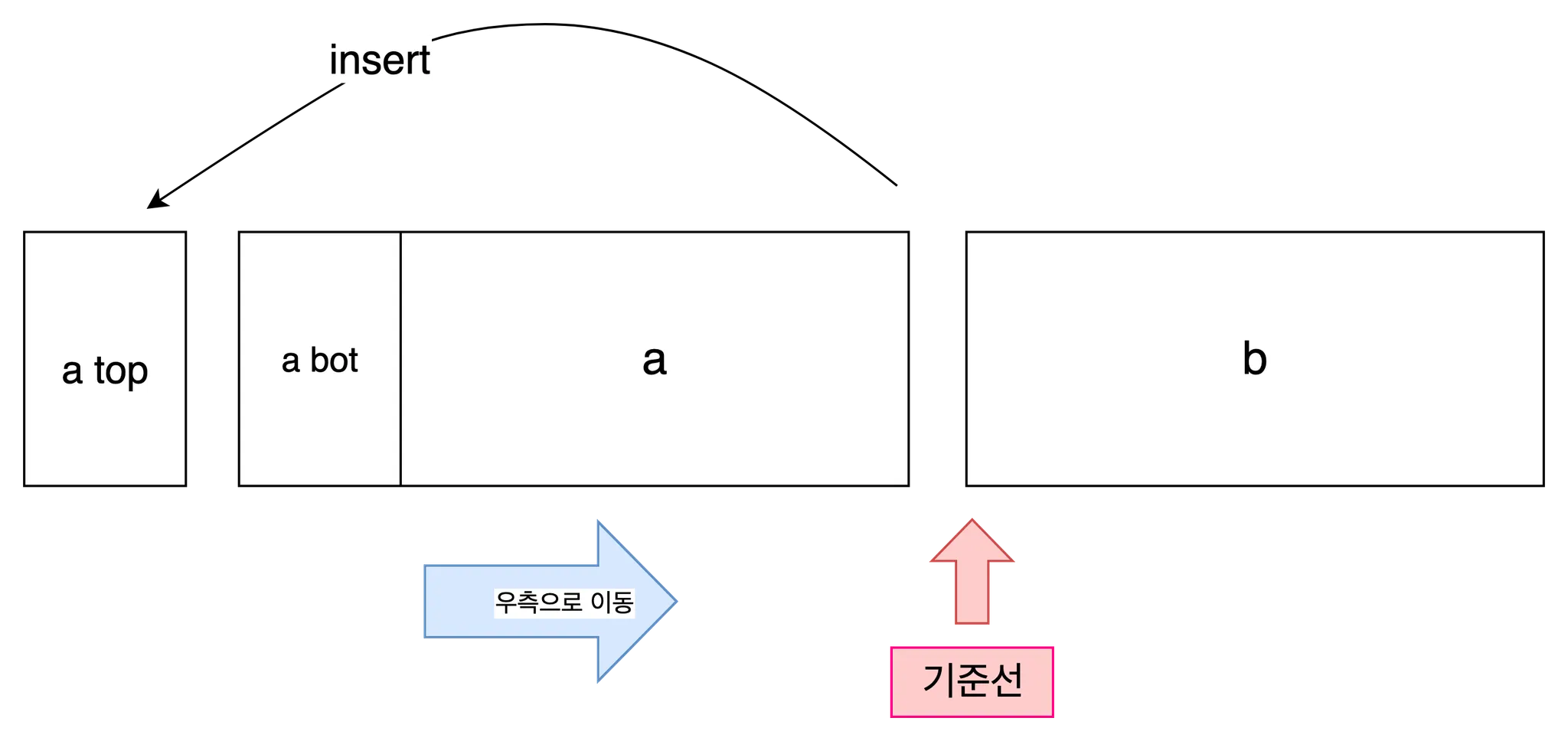
rotate
rotate계열 명령어는 기준선 좌,우의 한 원소를 메모리블럭 양 끝 단에 삽입한다. 삽입의 결과로 a의 나머지 모든 원소는 한 칸(int라면 4byte)씩 이동한다.
•
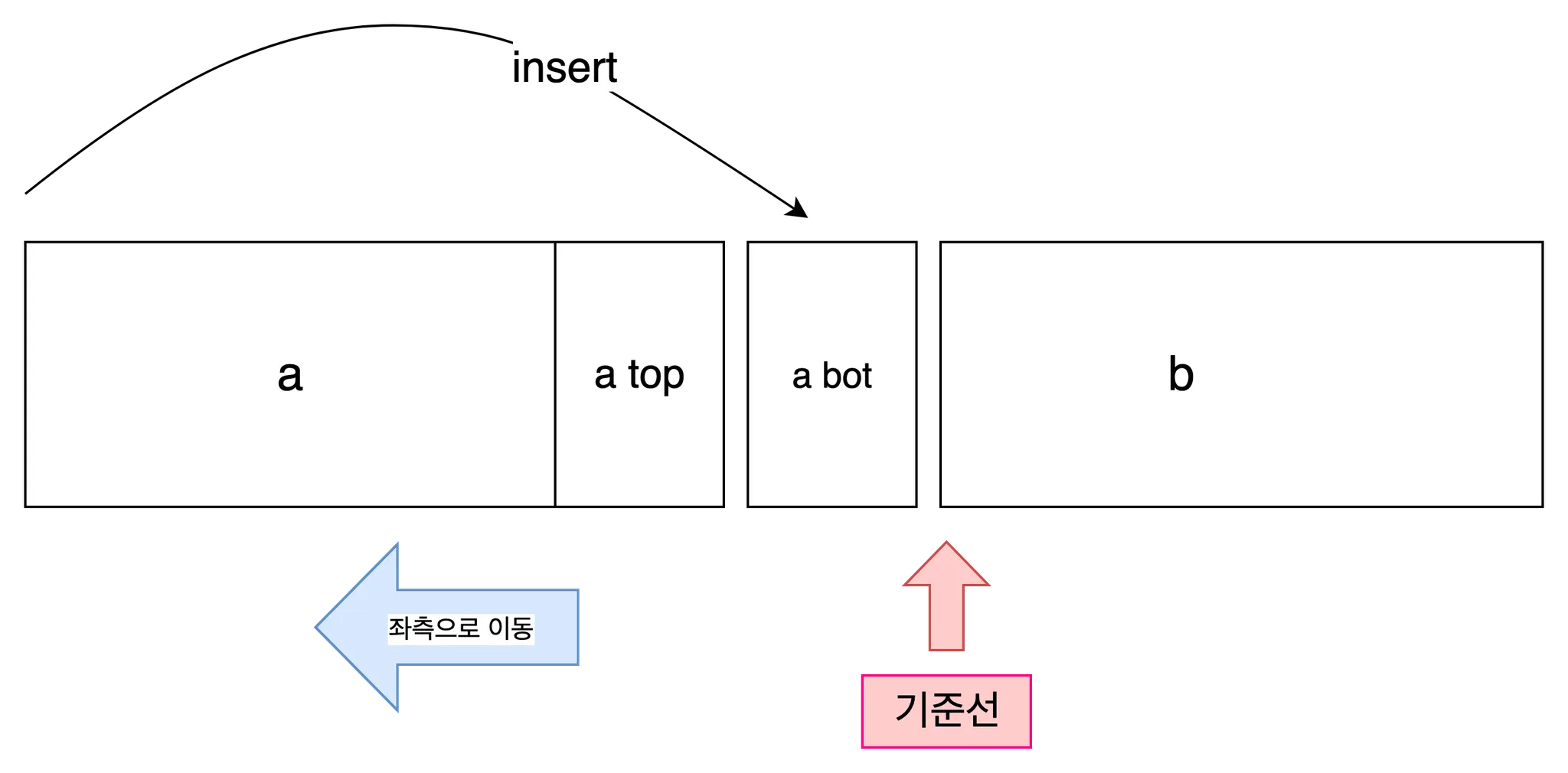
reverse rotate
끝단의 한 원소가 기준선 좌,우에 삽입된다. 마찬가지 원리로 나머지 원소들은 한 칸 이동한다.
3. 결론 - locality
•
결론
두 스택 a,b를 합치는 것을 통해서 우리는 각각의 커맨드가 선형 메모리에서 어떤 동작에 대응하는지 알 수 있었다. 여기서 눈여겨보아야 할 커맨드가 바로 push 계열 커맨드다. push는 실제로 값을 이동시키는 다른 커맨드와 달리, 기준선을 이동시킨다. 즉 그 자체로는 정렬에 기여하지 않는다. 하지만 주어진 과제에서 push 커맨드의 사용은 비용으로서 평가되고있다. 따라서 push의 사용 또한 실제 정렬 과정에서 발생하는 어떤 비용을 의미하는게 아닐까?
그렇다면 push계열 커맨드는 일반적인 정렬 과정에서 어떤 비용에 해당할까? 나는 push가 삽입 과정에서 수행되는 원소의 이동을 의미한다고 생각한다. 정렬이란 각 원소를 정해진 위치로 이동시키는 것이다. 하지만, 문제상황에서 원소의 이동은 기준선과 양 끝단에서만 가능하고, 삽입 위치를 특정하기 위해서는 기준선을 이동시켜야 하며, 이 기준선을 이동시키는 커맨드가 곧 push이기 때문이다.
push 커맨드의 개수를 특정 원소를 원하는 위치로 이동시키는 과정에서 발생하는 비용이라 한다면, 우리는 여기에 익숙한 개념을 적용할 수 있는데, 바로 지역성(locality)이다. 지역성이란 caching의 효율을 의미한다. 높은 지역성은 동종의 데이터를 최대한 인접하게 배치하여 탐색의 필요를 최소화 하거나(배열등의 자료구조) 동종의 작업을 집중적으로 처리(반복문)하는 것을 통해서 얻을 수 있다.
따라서 문제 상황에서 push의 빈번한 사용은 곧 낮은 지역성을 의미하며, push의 사용을 최소화 하여 지역성을 높이는 것이야 말로 커맨드 개수의 최소화의 비밀이라 생각한다. 한 발 더 나아가, push swap이라는 과제의 의의는 수행자로 하여금 기존의 big-O로 표현되는 효율성에 더해서 지역성을 고려하게 하는 데에 있다고 생각한다.