

본과정에서의 첫 번째 과제 libft!
처음 시작할 때는 어려운 것들 투성이었는데, 통과하고 보니 어느새 명확하게 알게 된 점들이 몇 가지 있었다.
man 매뉴얼을 모조리 뒤져가며, 평가를 받다 어버버해가며 …
열심히 시행착오를 겪으면서 얻은 소중한 지식들을 간략하게 정리해 보고자 한다 
어떤 함수는 mem으로 시작하고 어떤 함수는 str으로 시작하는 이유
Part1 에서 구현하는 C 표준 라이브러리 함수 중 일부는 이름이 mem 또는 str 으로 시작한다.
둘의 차이는 해당 함수가 특정 바이트를 기준으로 처리하냐, 문자열을 기준으로 처리하냐 였다.
•
str 으로 시작하는 함수
문자열을 받아서, 이 문자열의 끝을 널문자(\0)로 판단한다.
따라서 문자열이 널문자를 만났는지 아닌지를 핵심적인 조건으로 활용하여 함수를 구현한다.
strncmp 같이 size를 인자로 같이 받는 경우 size에 대한 조건 또한 포함되기도 한다.
•
mem 으로 시작하는 함수
메모리 영역을 가리키는 포인터 뿐만 아니라 처리해야 하는 바이트 수를 인자로 함께 받는다.
이 경우 널문자에 상관없이 인자로 받은 바이트 수가 핵심적인 조건이 된다.
이에 따라 char * 형 뿐만 아니라 void * 형으로 받을 수 있는 데이터도 다룰 수 있게 된다!
크기를 표현하는 자료형 size_t
구현해야 하는 함수들의 man 페이지를 들여다보면
문자열이나 메모리의 크기를 다루는 부분에선 어김없이 size_t 라는 낯선 자료형이 등장한다.
문자열의 길이를 반환하는 strlen 이나, len 바이트 만큼 특정 문자를 세팅하는 memset 함수에서처럼!
size_t strlen(const char *s); // 반환값이 size_t 타입
void *memset(void *b, int c, size_t len); // 매개변수가 size_t 타입
C
복사
C99 에 따르면 size_t 는
이론적으로 가능한 모든 타입의 객체의 최대 크기를 저장할 수 있는 unsigned 데이터 타입이다.
unsigned 타입은 0부터 시작해 양수 값만을 표현한다.
하지만 대응하는 signed 타입과 비교했을 때 자료형의 크기는 변하지 않기 때문에
음수 값을 표현하지 못하는 대신, 양수의 표현 범위가 넓어진다.

이미지 출처 : 정수 자료형 사용하기
⇒ 따라서 양수로만 나타나는 문자열이나 메모리의 크기를 나타내기에 적합하다.
왜 문자열이나 메모리의 크기에 관해서는 unsigned 타입 대신 size_t를 사용할까
size_t 는 unsigned 정수 타입의 별칭(typedef)이다.
일반적으로 unsigned int 지만, unsigned long 또는 unsigned long long 이 될 수도 있다는 것!
특정 unsigned 타입 대신 size_t를 사용하면, 대상 플랫폼에서 가능한 가장 큰 객체의 크기를 나타내기에 충분하면서도 필요 이상으로 크지 않은 unsigned 정수를 선택할 수 있게 된다!
→ 이에 따라 size_t는 32비트 운영체제에서는 부호 없는 32비트 정수(unsigned int), 64비트 운영체제에서는 부호 없는 64비트 정수(unsigned long long)가 된다.
ssize_t …?
크기를 나타내는 signed 데이터 타입으로 음수까지 표현이 가능하다.
read, write 같은 파일 입출력 함수는 실패 시에 -1을 반환하는데, 이를 위해서 음수까지 표현이 가능한 ssize_t를 반환형으로 사용한다.
overlap될 수 있다면 memcpy 대신 memmove를 사용해라?
두 함수 모두 특정 바이트만큼 메모리 영역을 복사할 때 사용되는 함수다.
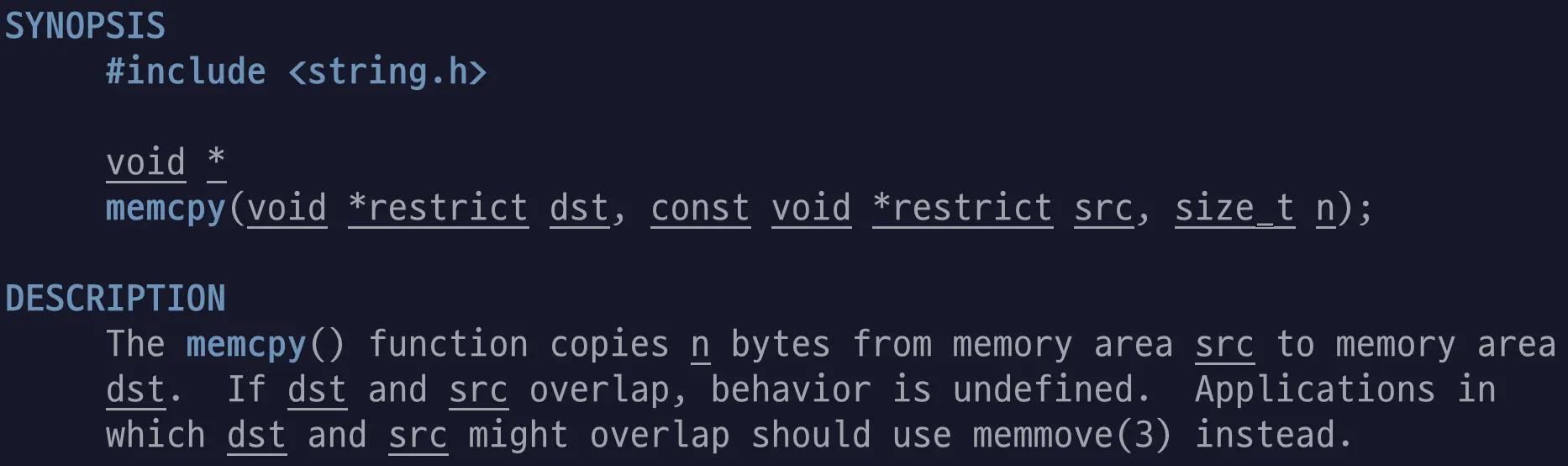
그런데 memcpy의 man 페이지를 살펴보면, 복사 받는 영역과 복사할 영역이 겹치면 동작이 정의되지 않는다! 겹칠 가능성이 있는 경우, memmove를 사용해라! 라는 설명이 있다.
•
memcpy
메모리의 내용을 직접 복사한다. 따라서 두 메모리 영역이 겹치면, 복사 작업이 파괴적으로 일어날 가능성이 있다. 복사 받을 메모리 영역보다 복사할 메모리 영역이 앞에 위치하면서 두 영역이 겹치는 경우에 문제가 생기는데, 복사할 메모리 내용이 이미 바뀌어 기존의 값을 잃어버리는 탓에 잘못된 값이 복사되기 때문이다.
•
memmove
메모리의 내용을 임시저장소에 저장한 후 복사한다. 따라서 메모리 영역이 겹쳐도 복사 작업이 원하는 대로 진행되므로 더 안전하다고 할 수 있다.
다만 해당 과제에서 memmove를 구현하기 위해서 임시 저장소 대신 다른 방법을 찾아야 했다!!!
임시저장소를 생성하기 위한 malloc 함수를 사용할 수 없기 때문이었다.
임시저장소를 생성하기 위한 malloc 함수를 사용할 수 없기 때문이었다.파일을 대표하는 값 File Descriptor
Part2의 함수 중 일부는 인자로 받은 파일 디스크립터(fd)를 활용하여 구현한다.
파일 디스크립터(File Descriptor)
시스템으로부터 할당 받은, 파일을 대표하는 추상적인 값으로 0 또는 양의 정수 값을 갖는다.
유닉스 시스템에서는 프로세스가 파일에 접근하기 위해서 파일 디스크립터를 활용한다.
표준 입력(Standard Input), 표준 출력(Standard Output), 표준 에러(Standard Error)는
기본적으로 할당되는 파일 디스크립터로, 각각 0, 1, 2 정수 값이 할당된다.
프로세스 실행 중에 파일을 열면, 시스템은 해당 프로세스의 파일 디스크립터 숫자 중 사용하지 않은 가장 작은 값을 할당한다. 예를 들어 해당 프로세스에서 파일을 처음 열었다면 그 파일에는 파일 디스크립터로 숫자 3이 할당될 것이다!
파일 디스크립터는 고작 숫자인데, 어떻게 특정 파일을 대표할 수 있는 걸까
파일 디스크립터가 가리키는 파일에 어떻게 접근하는지를 이해하려면 다음 세 가지 테이블을 이해하는 것이 좋다!
•
File Descriptor Table
각 프로세스에서 현재 사용 중인 파일을 관리하기 위한 테이블이다.
File Table을 가리키는 포인터를 담고 있는 배열이며, 이 배열의 index가 파일 디스크립터이다.
•
(Open) File Table
열린 파일의 읽기/쓰기 동작을 지원하기 위한 테이블으로, 파일이 열릴 때마다 하나씩 할당된다.
•
Inode Table
파일의 inode를 담고 있는 테이블이다. 같은 파일 당 하나씩 할당된다. inode 안에는 파일 종류와 권한, 크기, 데이터 블록을 가리키는 포인터 등의 파일 정보가 들어있다.
inode란?
그림과 함께 보면 이해가 쫌 더 잘 될 것이다.
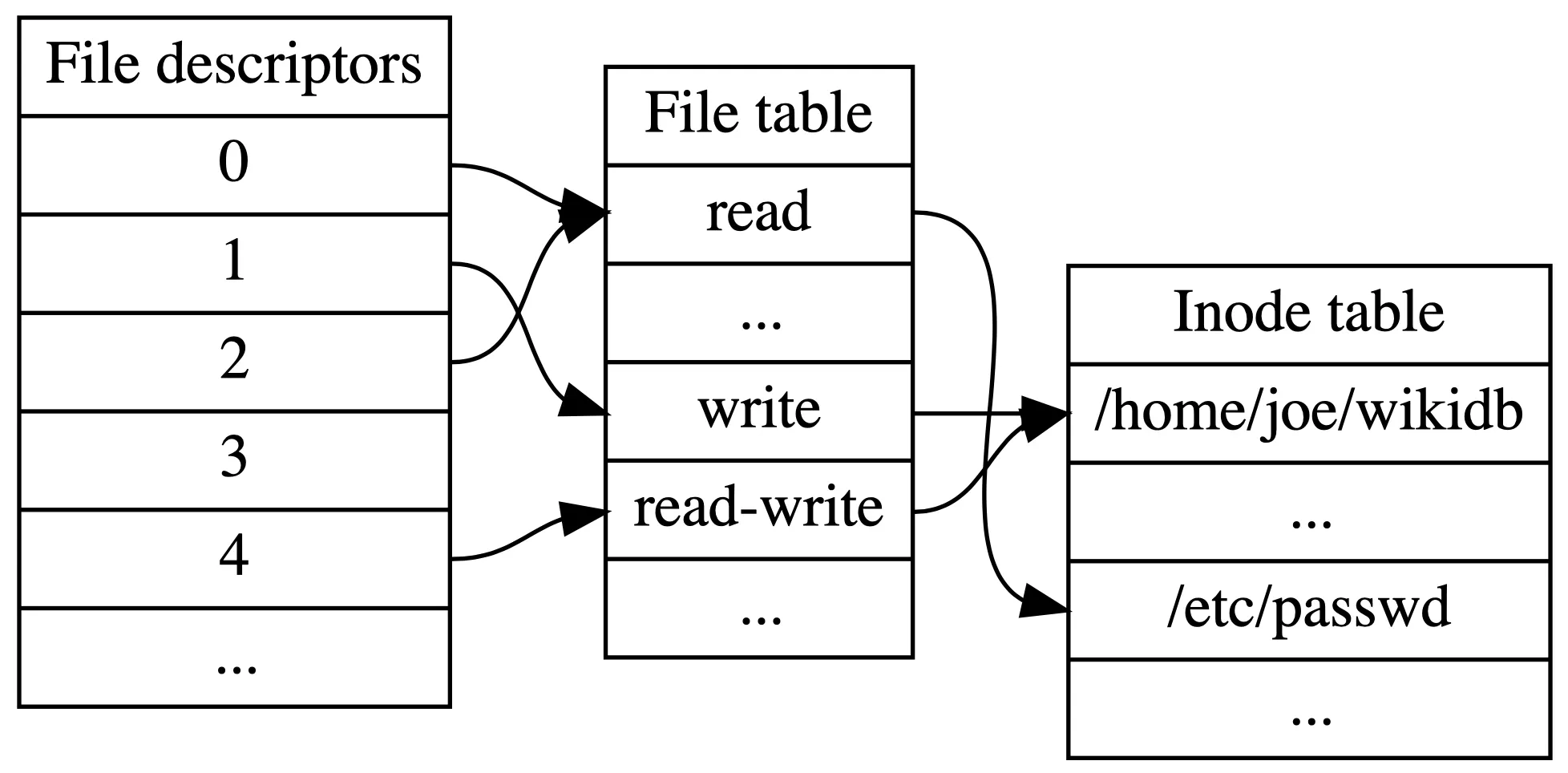
이미지 출처 : File descriptor - Wikiwand
결국 파일 디스크립터는 File Descriptor Table의 인덱스였고, 해당 인덱스의 포인터를 통해 다음 두 테이블에 접근함으로써 파일 정보를 얻어낼 수 있는 것이었다!!
Linked List 와 Array 의 차이점
해당 과제의 Bonus part에서는 연결리스트를 다루는 함수들을 구현한다.
배열과 연결리스트는 둘다 데이터를 구조적으로 다루기 위한 ‘자료구조’의 한 종류라는데,
문득 정확히 어떤 차이가 있는 건지 궁금했다.
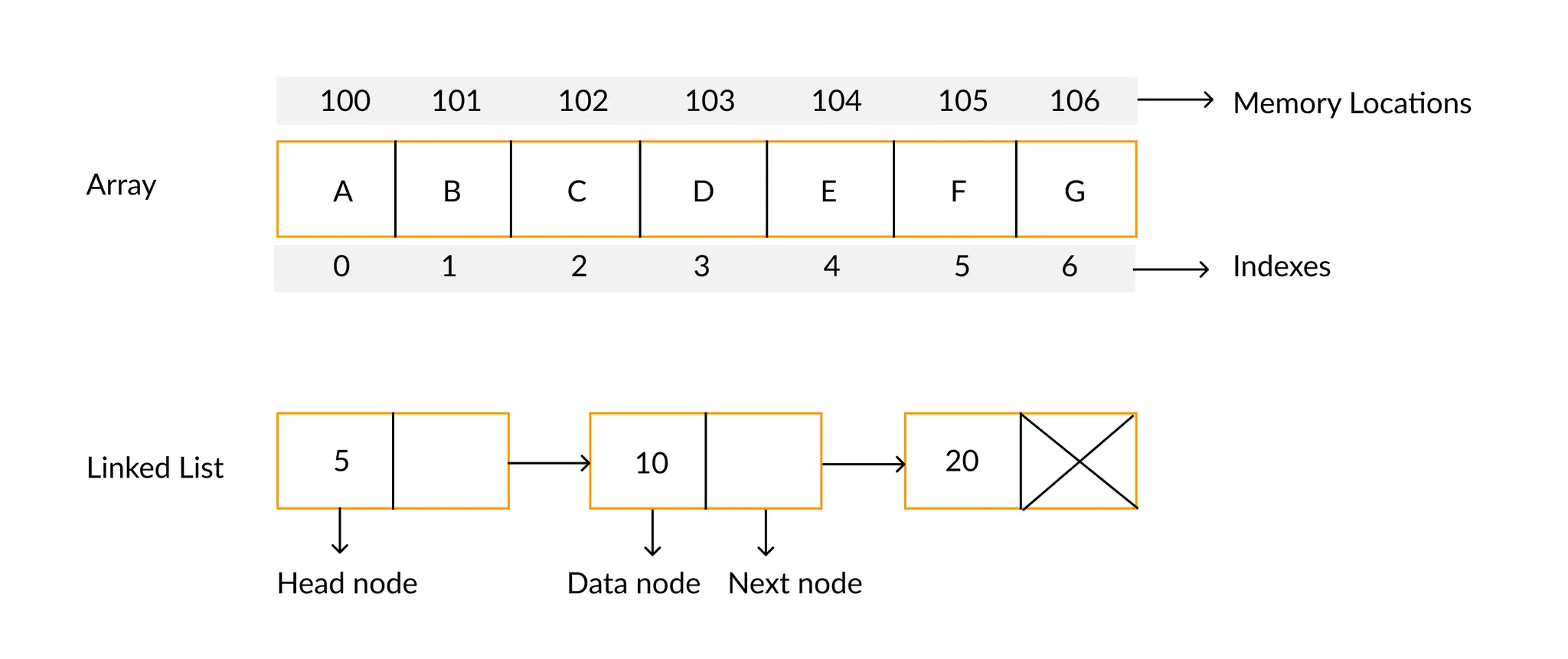
이미지 출처 : File descriptor - Wikiwand
배열(Array)
데이터들이 메모리 공간에서 연속적으로 저장되어 있는 자료구조이다.
•
배열에서 위치를 가리키는 숫자인 인덱스를 활용해 데이터에 쉽게 접근할 수 있다.
→ 데이터 탐색 시 O(1)의 시간복잡도를 가진다.
•
배열의 처음이나 중간에 데이터를 추가할 경우, 그 다음의 데이터들을 한 칸씩 뒤로 밀어야 한다.
→ 처음 및 중간에 데이터를 추가 시 O(n)의 시간복잡도를 가진다.
•
배열의 처음이나 중간의 데이터를 삭제할 경우, 그 다음의 데이터들을 한 칸씩 당겨와야 한다.
→ 처음 및 중간에 있는 데이터 삭제 시 O(n)의 시간복잡도를 가진다.
연결 리스트(linked list)
여러 개의 노드(데이터 묶음)들이 순차적으로 연결된 자료구조이다.
노드들은 메모리 공간에 흩어져 있으며, 각 노드가 이전 또는 다음 노드의 주소를 기억함으로써 연결된다.
•
특정 데이터에 접근하려면 처음부터 순차적으로 탐색해야 한다.
→ 데이터 탐색 시 O(n)의 시간복잡도를 가진다.
•
특정 데이터를 추가 및 삭제하는 경우, 노드가 기억하는 주소만 변경해주면 된다.
→ 데이터 추가 및 삭제 시 O(1)의 시간복잡도를 가진다.
배열과 연결리스트는 데이터 탐색과 추가 및 삭제에서 서로 가지고 있는 장단점이 달랐다.
무조건 배열이 좋다! 연결 리스트가 좋다! 판단하기 보다는 상황에 따라 유리한 자료구조를 택해야 겠다.
주가 되는 작업이 데이터 탐색이라면 배열을, 데이터 추가 및 삭제라면 연결 리스트를!
참고한 자료
잘못된 부분이 있다면 알려주세요
