



Subject
1. shell은 인터프리터다.
2. 파싱 알고리즘
3. 프랫 파서 in MiniShell
1. shell은 인터프리터다.
1) 인터프리터란 무엇인가?
shell이란 껍질을 뜻하며, 커널을 감싸고 있다는 의미에서 붙은 이름이다. 쉘은 사용자의 목적인 응용프로그램의 실행을 편하게 하기 위한 적절한 실행환경을 제공하는 프로그램이다. 운영체제의 핵심인 커널에 서비스를 요청하는, 일종의 클라이언트라고 생각할 수도 있다. 우리는 MiniShell에서는 이 shell의 일부를 구현해야 한다.
하지만, 우리의 shell은 단순히 실행 환경만을 제공하는 프로그램이 아니었으니, shell은 shellscript라는 프로그래밍 언어를 실행시키는 인터프리터다. 인터프리터란 코드를 문자열의 형태로 입력으로 받아서 해당 코드를 실행하는 프로그램이다. 대표적으로 python, node.js, 등이 인터프리터를 기반으로 동작하는 언어다. 따라서, 우리의 shell도 마찬가지로 shell script라는 프로그래밍 언어를 해석하고, 실행해야 한다.
2) 인터프리터의 동작 과정
일반적인 인터프리터는 코드를 실행하기 위해서 다음의 과정을 수행한다.
0.
input : 실행하고자 하는 코드를 문자열의 형태로 읽어들임. 일반적으로, 개행으로 구분되는 라인 단위의 입력을 받아 그에 해당하는 동작을 수행하고 다음 라인 입력을 대기한다.
1.
Lexing : 입력받은 코드를 특정 문자(연산자, 키워드, 등)를 기준으로 분리하여 의미를 갖는 최소 단위로 구분하는 작업. 이렇게 얻어진 단위를 token이라 부른다. 최종적으로 token의 배열을 획득한다. lexical analysis 또는 tokenize라고 부르기도 함. 이후 과정에서 이들 token이 어떠한 방식으로 결합되는 지에 따라서 다른 해석이 가능함.
2.
Parsing : 코드를 해석하는 작업. 렉싱 결과 획득한 token을 문법에 맞게 결합하여 의미를 갖는 구조로 재구성하는 과정. 토큰들의 결합은 tree가 되는데, 주로 이진트리가 선택됨. 이 트리를 추상 구문 트리(abstract syntax tree, ast)라고 함. 즉 단순한 token의 나열에서, 규칙적으로 결합된 ast를 생성하는 과정임.
3.
Evaluating : 생성된 구문 트리를 순회하면서 해당 트리가 표현하는 문법구조에 따른 동작을 수행한다.
트리의 순회를 마쳤으면, 다시 0번으로 돌아가 입력을 기다린다.
1, 2번 과정을 수행하는 프로그램 혹은 서브루틴을 흔히 파서(parser)라 한다. 토큰을 어떤 순서로, 어떻게 결합하는 지가 곧 파서의 성능을 결정하며, 보다 효율적이고 정밀한 해석을 위해서 다양한 파싱 알고리즘이 고안되었다. 현재는 파서를 생성하는 툴이 개발되어, 보통 사람이 파서를 구현하는 일은 거의 없게 되었다.
2. 파싱 알고리즘
1) 재귀 하향식 파싱 알고리즘
초창기 파싱 알고리즘은 재귀 하향식 파싱 알고리즘이었다(이하 재귀 하향 파서). 재귀 하향 파서는 우선순위가 높은 상위의 문법에서 시작하여 하위의 문법으로, 구문 전체가 해석이 될 때 까지 모든 문법을 적용해보는 알고리즘이다. 일반적으로 모든 문법의 패턴(토큰의 조합)에 대응하는 해석 함수를 준비하고, 각각의 경우에 대해서 해석 함수를 호출하는 방식으로 이루어진다. 만일 해당 해석 함수로 해당 토큰에 대한 해석에 성공하면, 이후 다음 토큰에 대해서 재귀적으로 해석 함수를 호출한다. 해당 해석 함수로 해당 토큰에 대한 해석이 실패한다면 다음 하위 문법의 해석 함수를 호출한다.
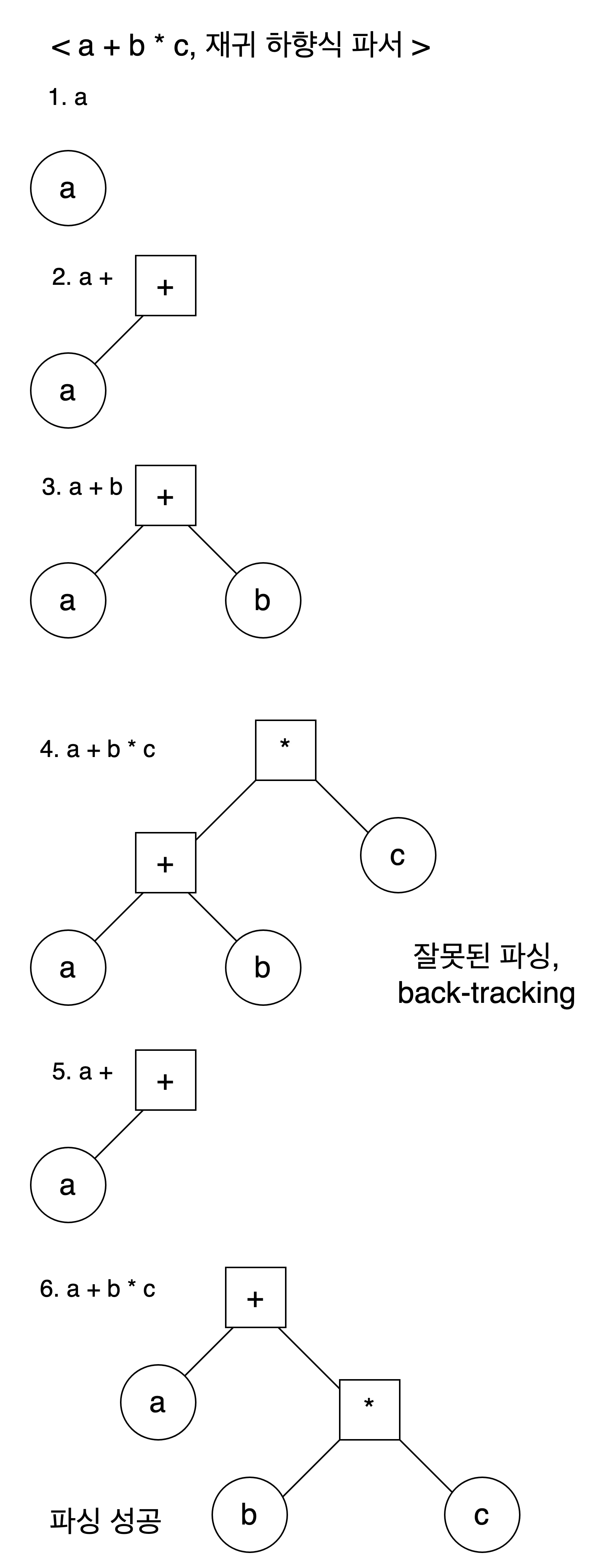
해당 알고리즘은 가능한 모든 문법 패턴에 대해서 해석을 시도한다는 점에서 완전 탐색 알고리즘이다. 재귀 하향식 파서는 해당 구문에 문법적 오류가 있어 해석이 불가능한 상황을 만나면, 다음 문법으로 해석을 시도해야 하고 이는 필연적으로 back-tracking을 의미한다. 이러한 back-tracking 과정에는 기존의 해석(즉 생성한 ast)을 모두 취소(즉 ast를 삭제)하는 과정을 포함한다. 이러한 백트래킹은 다음과 같은 문제를 갖는다.
먼저 시간적인 효율성의 문제다. 해석이 가능한 상황에 도달하기 까지 가능한 문법 조합을 모조리 시도하므로, 불필요하게 시간이 소요된다. 심지어 그 어떠한 방법으로도 해석이 불가능한 문법적 오류가 있는 경우(잘못된 위치의 토큰) 혹은 해석에는 성공했으나 문법적으로 잘못된 해석인 경우(우선순위의 문제), 가능한 모든 조합을 시도한 뒤에야 실패했음을 알 수 있으므로, 매우 비효율적이다. 다음으로는 오류 탐지의 비효율성이다. 문법적 오류가 있는 경우 이미 모든 조합을 다 시도해봤으므로, 해당 문법적 오류가 어디서 나타나는지를 확인하는 것 또한 상당히 곤란하다. 이러한 비효율성은 해당 언어의 문법이 복잡하여 해석의 가지수에 비례하여 기하급수적(exponential)으로 증가한다.
2) 플로이드의 파싱 알고리즘(상향식 연산자 우선순위 파서)
컴퓨터 공학계 불후의 천재였던 로버트 플로이드(Robert W Floyd)는 기존의 파싱 알고리즘이 가지고 있는 비효율성(백트래킹 문제)을 개선한 새로운 알고리즘을 고안했는데, 이 것이 바로 상향식 연산자 우선순위 파싱 알고리즘(이하 플로이드 파서)이다.
해당 알고리즘의 핵심 아이디어는 바로 우선순위의 존재이다. 재귀 하향식 파서가 문법에 해당하는 함수를 호출하여 해당 토큰을 파싱했다면, 연산자 우선순위 파서에서는 토큰의 타입에 맞는 파싱 함수를 호출한다. 토큰에서 각 연산자의 우선순위를 미리 알게 되고, 이를 참조하여 우선순위가 높은 문법을 먼저 적용하는 것을 통해서 잘못된 순서로 토큰들이 결합하는 것을 막는다. 결합을 해보고 틀려서 백트래킹을 하는 것이 아닌, 처음부터 옳바른 방식으로 토큰을 결합하고, 불가능하면 즉시 에러를 찾는 것이다. 이는 완전 탐색을 그리디로 바꾼 것으로, 시간 복잡도를 O(N)으로 크게 개선한다. 또한 문법적 에러가 발생했을 시, 그 즉시 확인이 가능하므로, 구문 내에서 어디에 오류가 존재하는 확인하기도 편하다.
플로이드 파서의 특징 중 하나는 바로 상향식 파서라는 점이다. 현재 바라보는 토큰의 조합을 문법적 패턴과 대조해가며 최 상단의 비 말단 노드(non terminal node)부터 생성하고, 이를 구성하는 자식 노드를 생성하여 최종적으로 말단 노드를 생성하는 기존의 하향식 파싱과는 달리, 상향식 파서는 말단 노드(terminal node)부터 생성하고, 이를 결합하면서 비 말단 노드를 생성, 이들을 결합하면서 진행한다.
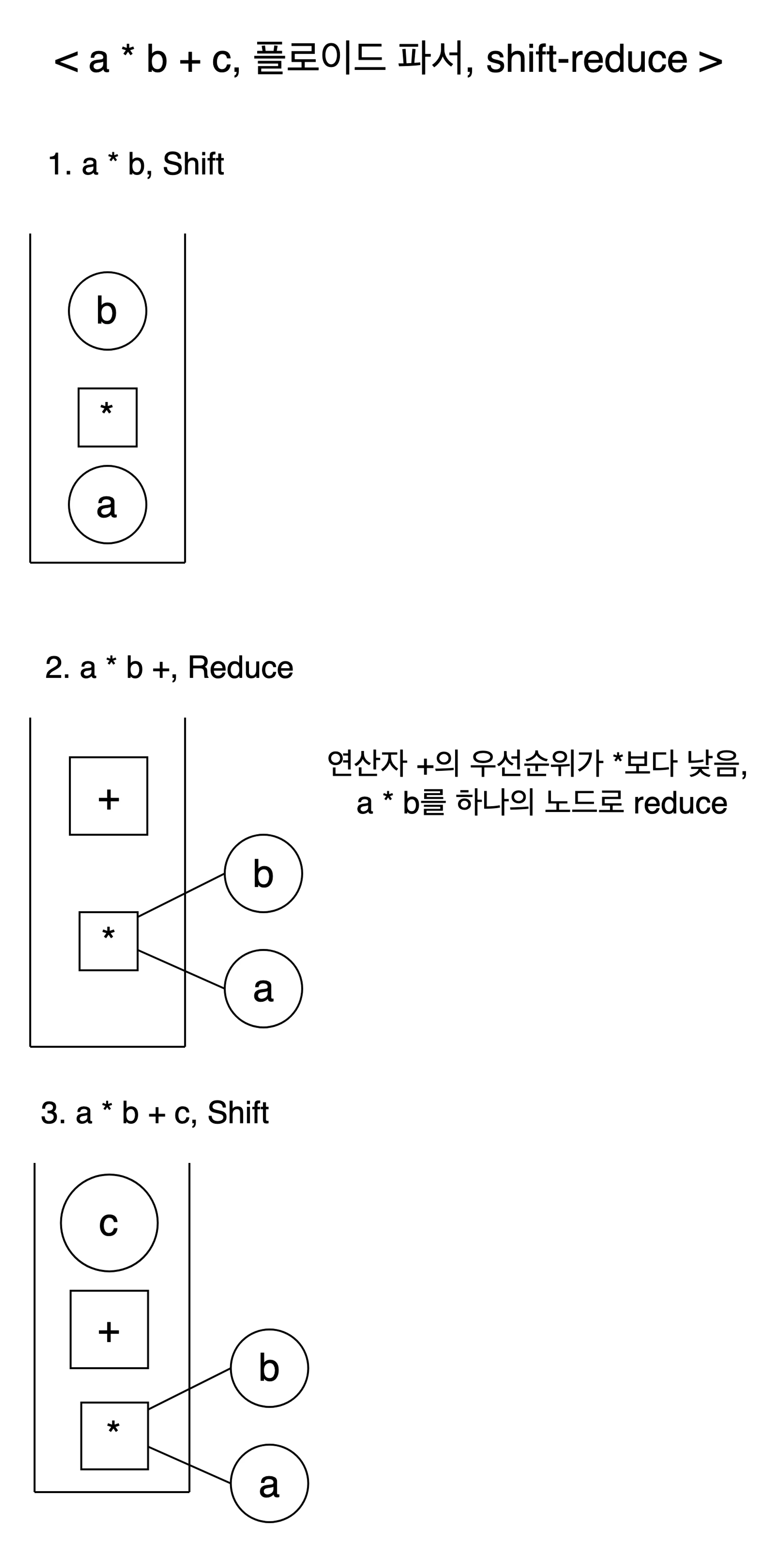
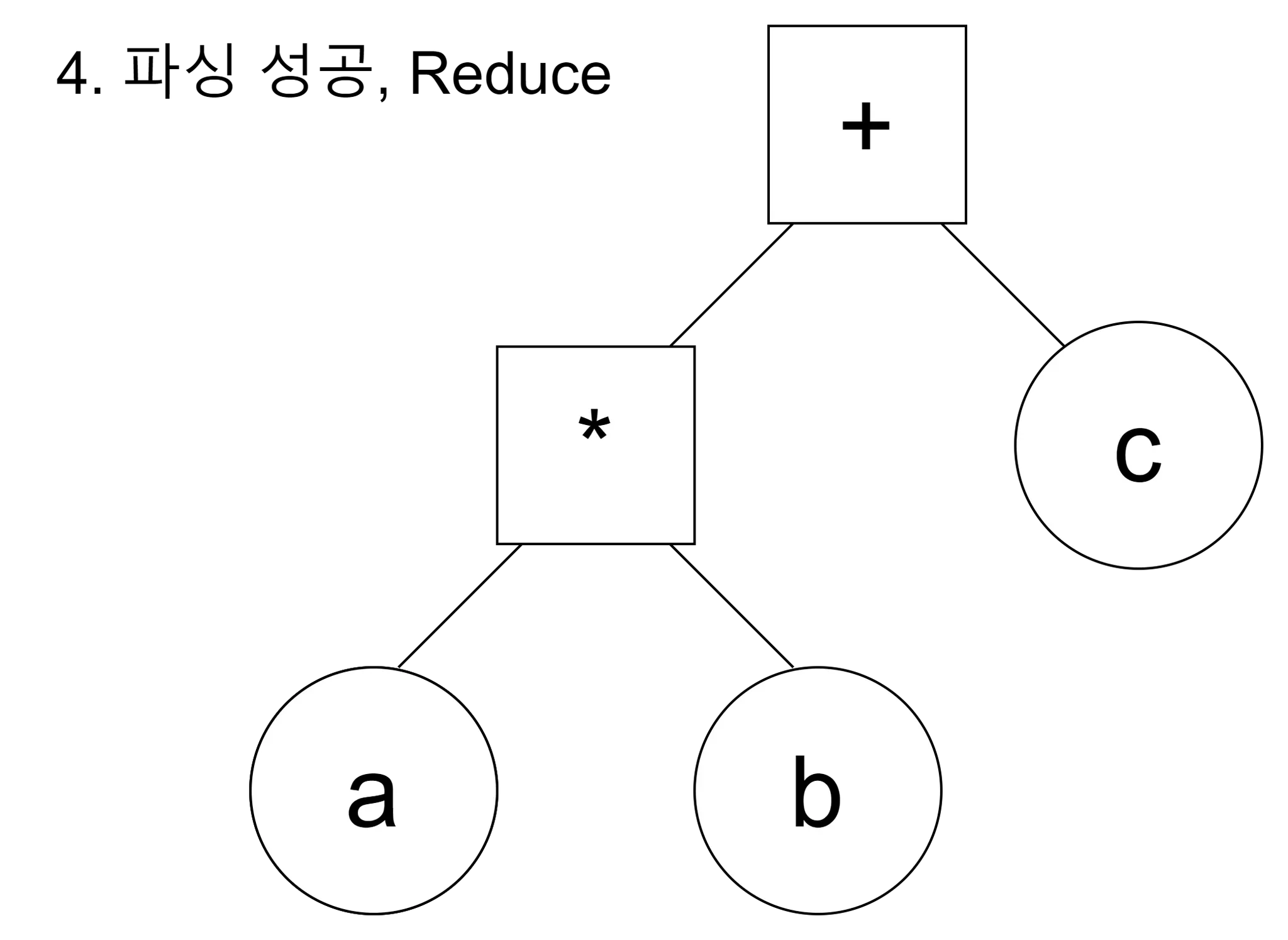
위는 대표적인 상향식 파서인 shift-reduce 파서에 연산자 우선순위를 결합한 결과이다. 해당 파서는 token들을 순서대로 확인하며, 토큰을 stack에 저장하며 파싱을 수행한다. shift는 통과(stack에 push), reduce는 결합(stack의 노드를 결합하여 축소)을 의미하는데, 현재 연산자보다 이전 연산자의 우선순위가 높다면 stack의 내용물을 결합(reduce)한 후 shift(stack에 token을 push)한다.
3) 프랫의 파싱 알고리즘(하향식 연산자 우선순위 파서).
플로이드의 동료이자 절친한 친구였던 크누스(Donald E Knuth), 그 크누스의 제자인 프랫(Vaughan Pratt)은 플로이드의 아이디어와, 하향식 원리를 결합하여 하향식 연산자 우선순위 파싱 알고리즘(이하 프랫 파서)를 고안한다. 프랫 파서는 연산자 우선순위 파서의 효율성과 재귀 하향식 파서에서 오는 구현의 간편함을 모두 취한 훌륭한 설계로 평가받는다.
플로이드의 연산자 우선순위 개념은 프랫 파서에서 바인딩 파워(Binding Power)의 형태로 나타난다. 바인딩 파워는 연산자가 인접한 노드를 끌어당겨 결합하려고 하는 힘을 의미한다. Binding Power는 기본적으로 연산자의 우선순위에 비례하며, 어느 표현식이 어느 트리의 하단에 위치할지를 결정한다. 일반적으로 Left Binding Power(이하 LBP)와 Right Binding Power(이하 RBP)가 있어서 둘을 비교하는데, RBP는 해당 연산자가 오른쪽 피연산자로 끌어들이려는 힘을 나타내는 값이고, LBP는 반대로 해당 연산자가 왼쪽 피연산자로 결합하려는 힘을 나타내는 값이다. 일반적으로, 좌측 연산자의 RBP와 우측 연산자의 LBP가 경쟁한다.
한 표현식의 RBP가 크다는 것은 해당 표현식의 오른쪽에 노드를 결합하려고 하는 힘이 강하다는 뜻이다. 다시 말하면 RBP가 상대적으로 클 수록 현재 표현식의 오른쪽 서브트리의 일부가 된다. 반대로 LBP는 RBP에 대한 상대적인 개념으로, 다음 표현식의 우선순위에 비례한다. 상대적으로 LBP가 크다는 것은 노드가 다음 표현식의 왼쪽 자식 으로 결합됨을 의미한다.
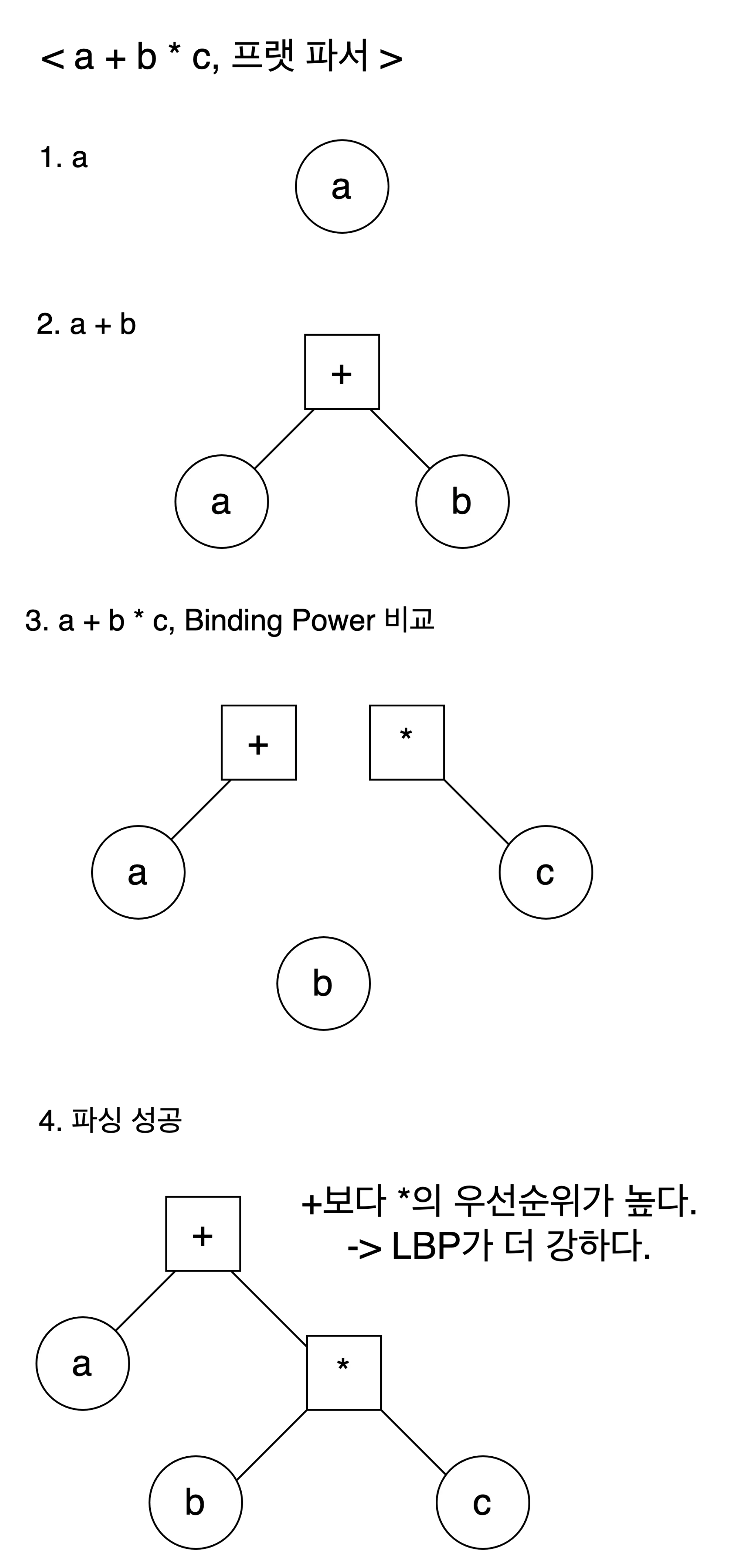
위의 예시에서는 +의 RBP보다 *의 LBP가 더 강하다(우선순위가 높으므로). 그 결과 노드 b는 이전 표현식 +의 오른쪽 자식 노드에서 *표현식의 왼쪽 자식 노드로 빨려들어간다.
3. 프랫 파서 in MiniShell
MiniShell 과제의 파서를 프랫 파서로 구현하였다. 따라서 그와 관련하여 대략적인 동작과 그 정의를 소개하고자 한다. 먼저 파싱의 대상이 되는 토큰에 대해서 정의한다. 미니 쉘의 문법에서 정의하는 토큰은 연산자 9종(<, <<, >, >>, |, ||, &&, ‘(’, ‘)’ )과 피연산자인 파일명과 커맨드(커맨드 + 인자)까지 총 11종이다. 다음으로는 연산자와 그 연산자로 대표되는 표현식에 대해서 알아보자.
1) 표현식 정의
•
리디렉션, 전위연산자
< infile command ...
<< delimeter command ...
< infile1 <infile 2 ...
<< heredoc1 << heredoc2 ...
> outfile1 > outfile2 ...
>> outfile1 >> outfile2 ...
Bash
복사
기본적으로 input에 대한 redirection을 수행하는 <와 << 연산자는 전위 연산자이다. 이들은 피연산자로 단 하나의 단어를 파일 이름으로 삼는다. 예외적으로 output에 대한 redirection을 수행하는 >와 >>또한 제한적으로 전위연산자로 이해될 수 있다. 이들 또한 마찬가지로 하나의 단어를 파일 이름으로 하여 피연산자로 갖는다.
특징이라면, read와 heredoc표현식 다음에는 바로 command가 나올 수 있다는 점이다. 연산자와 피연산자가 번갈아 등장하지 않는 이러한 예외적인 문법과 관련된 부분은 별도의 처리가 필요하다.
•
리디렉션, 중위연산자
command > outfile
command >> outfile
Bash
복사
기본적으로 output과 관련된 redirection을 수행하는 >, >>연산자는 중위 연산자이다.
•
파이프, 중위연산자
command1 | command2
Bash
복사
좌측 커맨드의 출력을 우측 커맨드의 입력으로 전달하는 파이프 연산자이다. 연산자의 좌우로 커맨드를 필요로 한다. 일반적인 프로그래밍 언어에서 피연산자의 부재는 문법적 오류이지만, 쉘 계열에서는 어째선지 허용하고 있다.
•
논리 연산자(AND, OR), 중위연산자
command1 && command2
command1 || command2
Bash
복사
파이프와 마찬가지로 좌우의 두 커맨드를 피연산자로 갖는다. 피연산자의 부재는 문법적 오류이지만, 쉘 계열에서는 어째선지 허용하고 있다.
2) 연산자 우선순위(operator precedence) 정의
각 연산자들의 우선순위는 다음과 같다. 번호가 작을 수록 우선순위가 낮고, BP도 낮다.
1.
시작 노드(초기값)
2.
논리연산 (&&, ||)
3.
파이프 ( | )
4.
리디렉션 (<, <<, >, >>)
5.
서브쉘 ( “(” )
서브쉘, 즉 소괄호의 존재는 파싱 과정에서 연산자의 우선순위를 조정하는 역할을 한다. 상대적으로 괄호 내부의 연산자는 그 우선순위가 증가하며, 그 반대로 괄호 바깥의 연산자는 그 우선순위가 감소한다.
3) 파싱 결과 예시
•
single command with single redirection
<infile command > outfile
Bash
복사
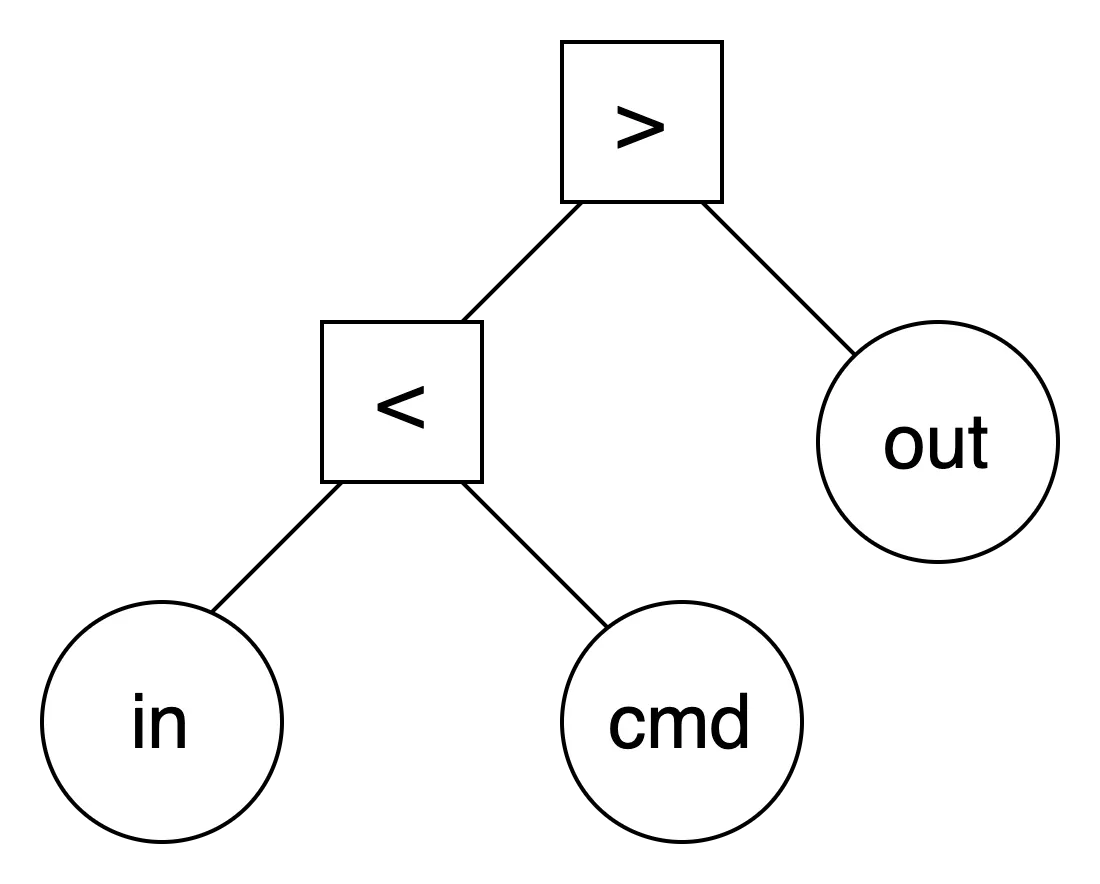
outfile에 대한 리디렉션을 수행한 후 infile에 대한 리디렉션을 수행하고, 최종적으로 command를 실행함.
•
single command with multiple redirection
< infile1 < infile2 command > outfile1 > outfile2
Bash
복사
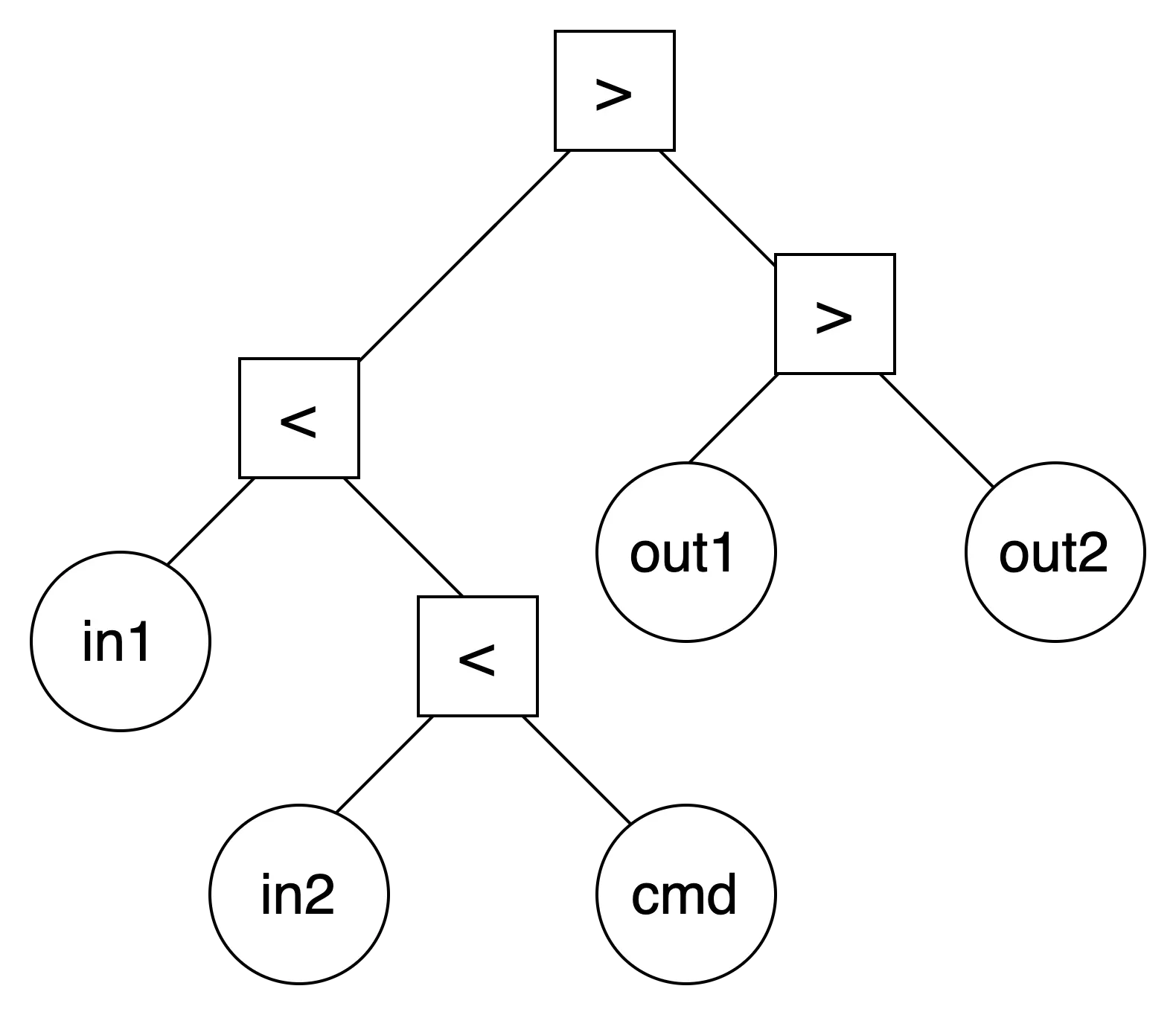
out1 리디렉션 → out2 리디렉션 → in1 리디렉션 → in2 리디렉션 → cmd 실행.
•
multiple redirection only
> out1 > out2 > out3 > out4
Bash
복사
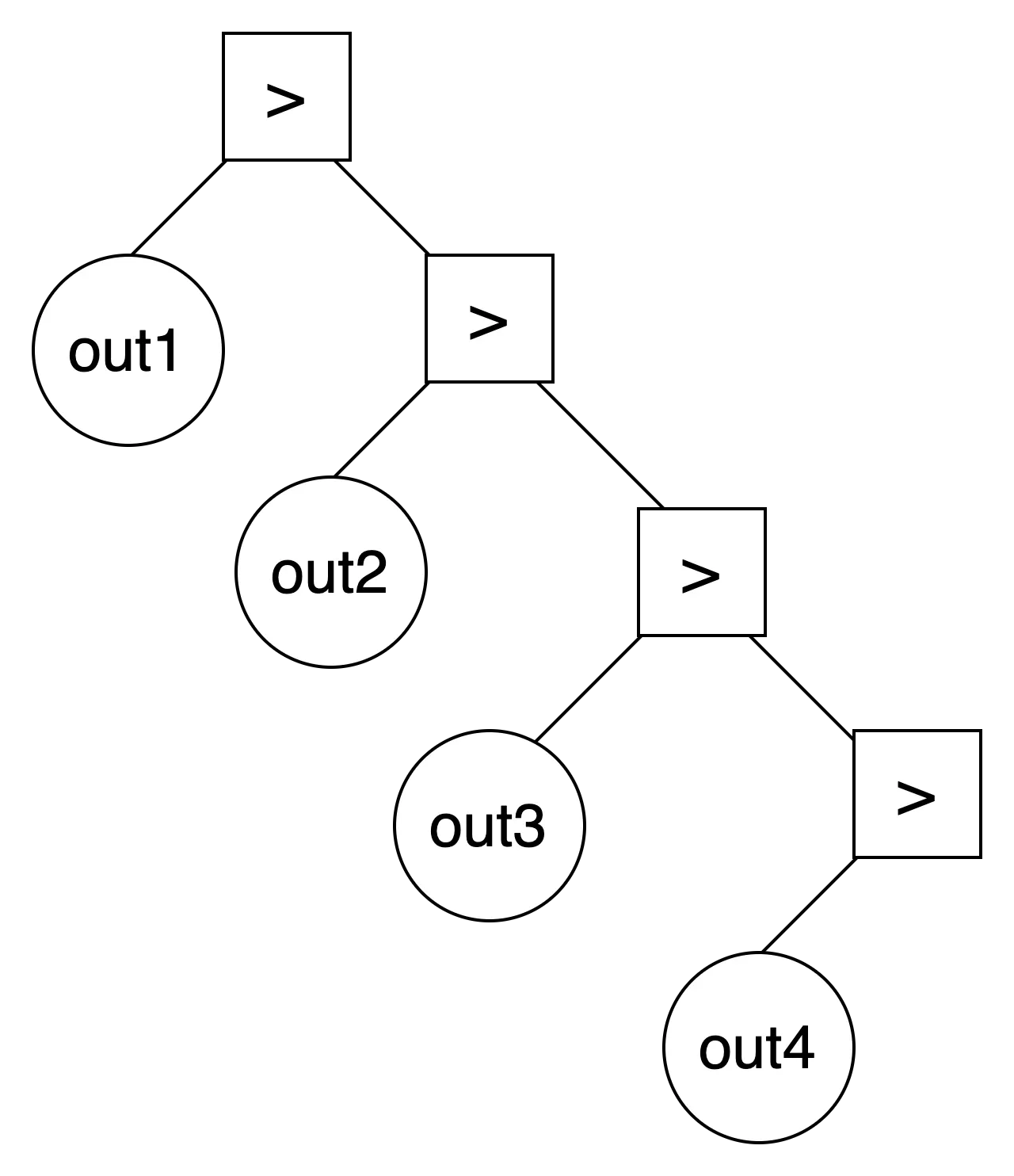
out1 리디렉션 → out2 리디렉션 → out3 리디렉션 → out4 리디렉션.
•
multiple command with pipe
<in1 command1 >out1 | <in1 command2 >out2 | <in3 command3 >out3
Bash
복사
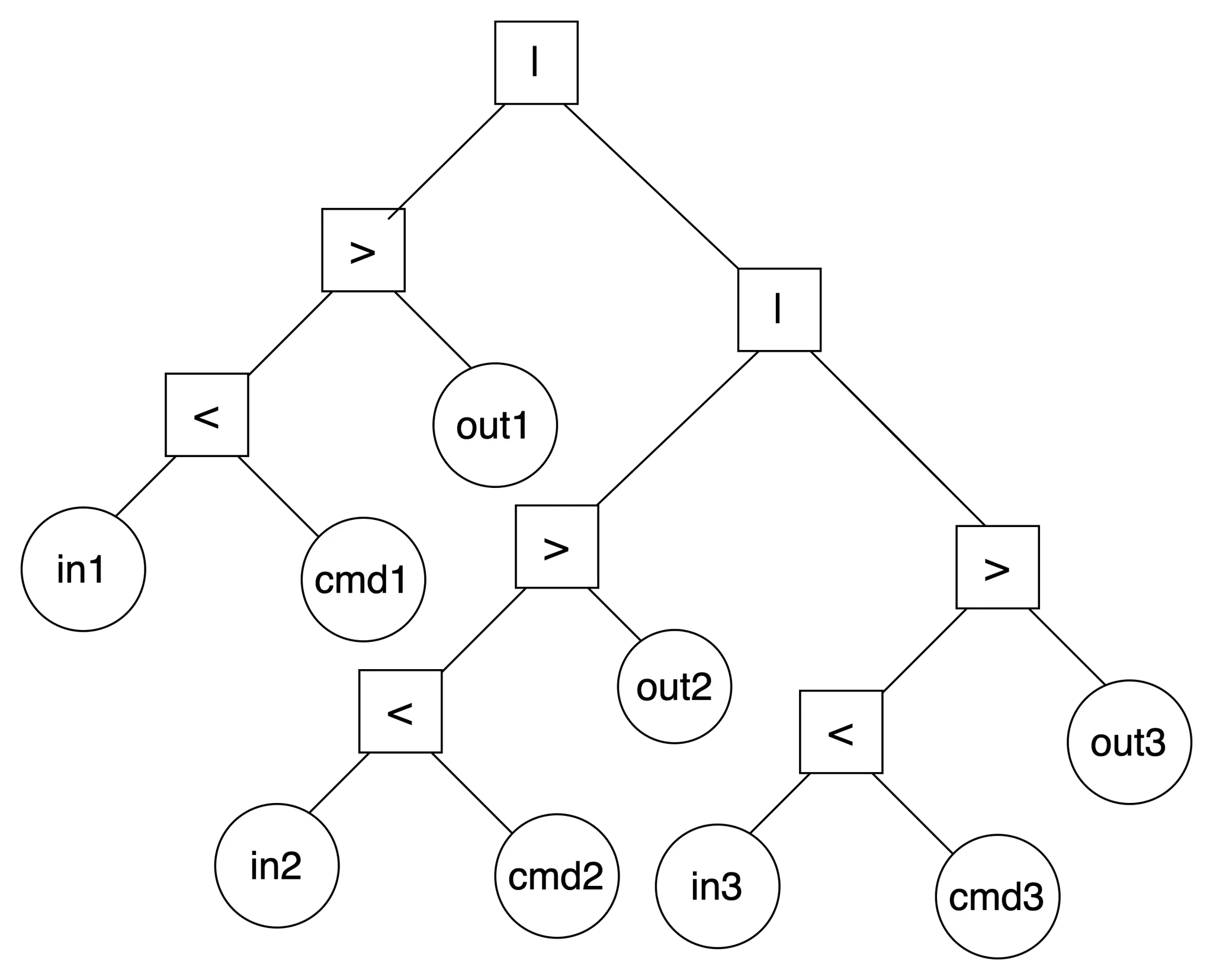
•
multiple command with logical operation
command1 && command2 || command3 && command4
Bash
복사
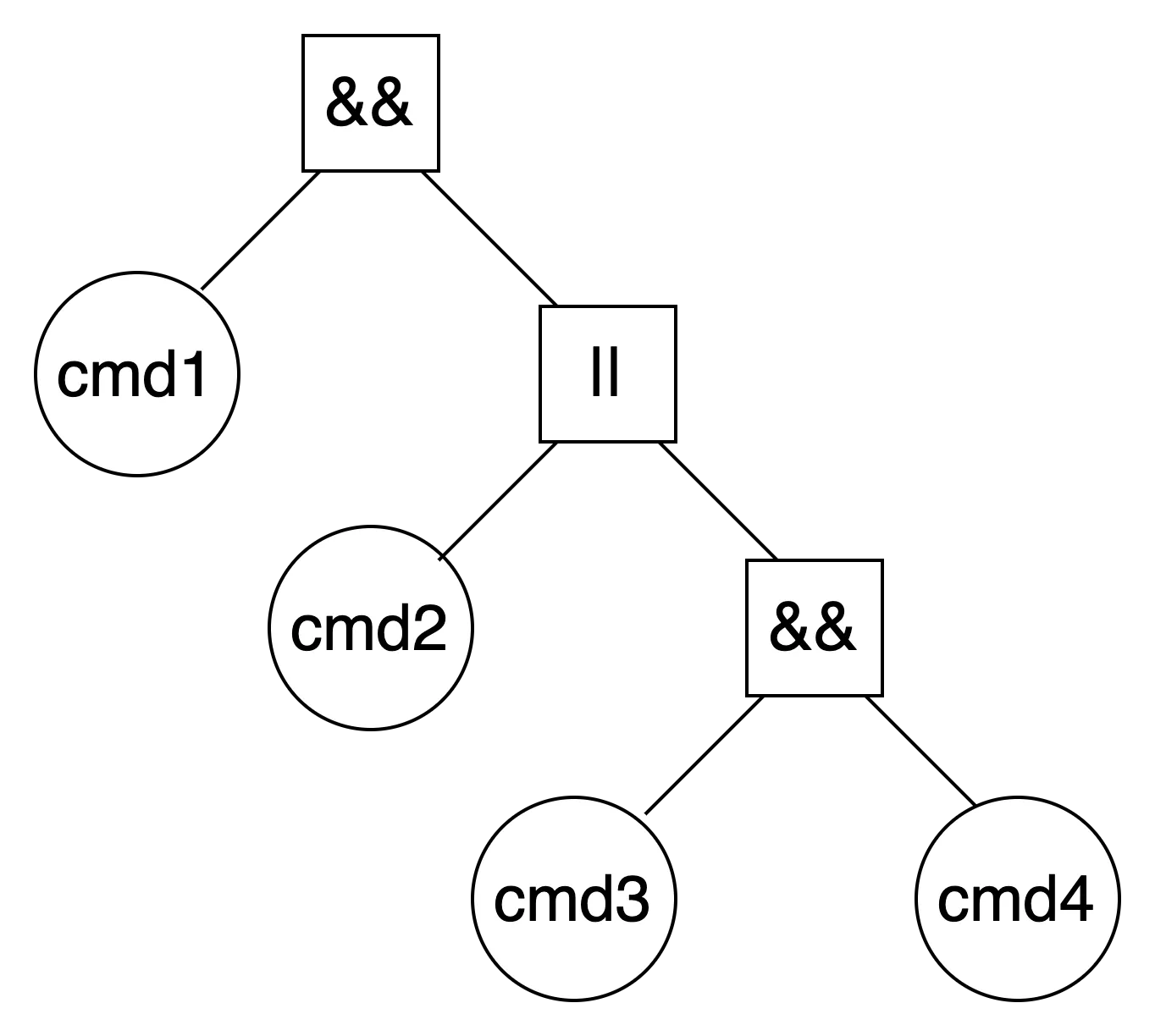
•
multiple command with pipe and logical operation
command1 && command2 | command3 || command4
Bash
복사
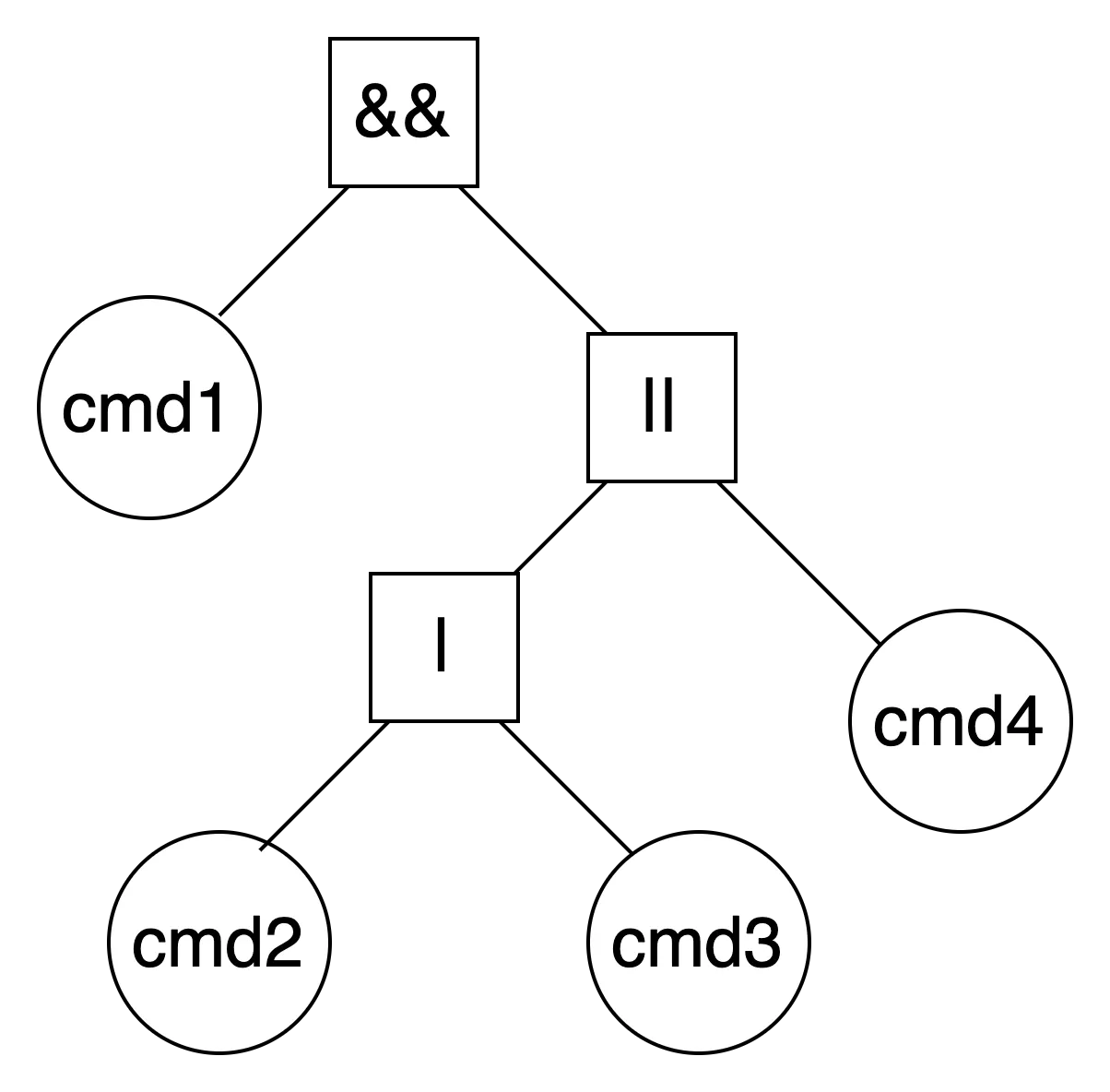
앞서 정의된 우선순위에 따라, &&의 RBP보다 ||의 LBP가 높으며, |의 RBP가 ||의 LBP보다 높다. 따라서 위와 같은 파싱 결과를 얻을 수 있다.
•
multiple command with sub-shell
command1 | ( ( command2 && command3 ) | command4 ) | command5
Bash
복사
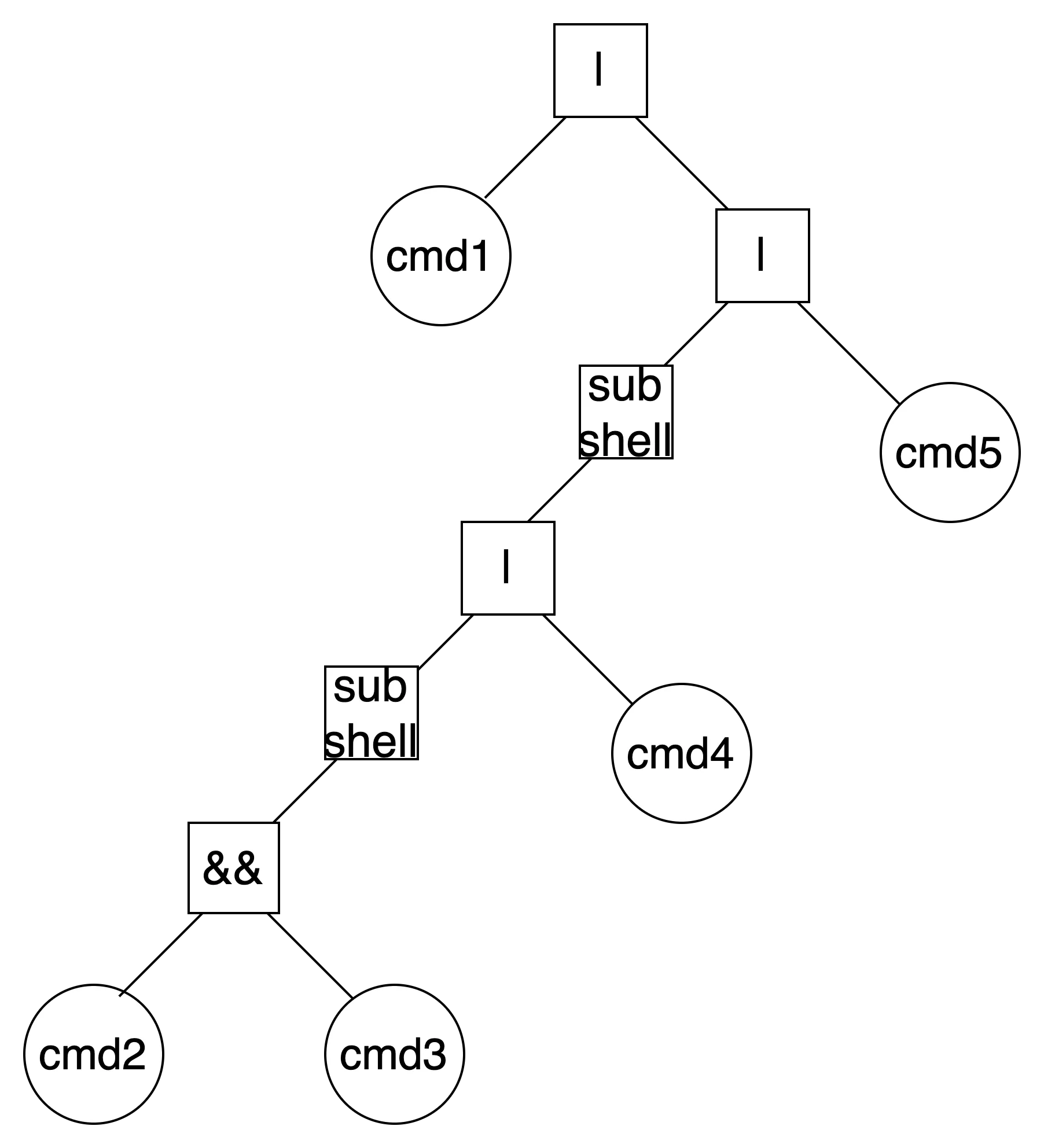
subshell 처리가 없었다면 cmd1과 cmd2, cmd3와 cmd4가 각각 pipe의 피연산자로 묶였을 것이다. 이는 파싱 과정에서 pipe의 BP와 &&의 BP가 subshell에 의해서 역전되었음을 의미한다.
•
bash와의 차이
나의 파서 구현에는 bash와 다른 거동을 보이는 경우가 있는데 이는 다음과 같다. 나의 minishell에서는 다음과 같은 구문은 문법적 오류로 판단된다.
< infile | cat - > outfile
Bash
복사
해당 구문의 해석 결과는 다음과 같다. 먼저 infile을 입력으로 리디렉션 하고, 이를 다시 파이프를 이용하여 cat -의 입력으로 전달한다. 끝으로 cat -의 결과를 리디렉션하여 stdout이 아닌 outfile로 출력한다. 다만, 여기서 pipe로 전달되어야 하는 출력을 생산할 커맨드가 없다. 나는 해당 구문을 문법적 오류라고 생각한다. 커맨드의 출력을 전달받아 이를 다음 커맨드의 입력으로 넘겨주는 | 연산자의 정의에 의한 피연산자인 커맨드가 존재하지 않기 때문이다. 하지만, bash에서는 해당 구문을 허용하고 있다.
이러한 문제가 생긴 원인은 shell script의 문법적 특성에 기인한다. shell 문법의 특징 중 하나는 비말단 노드가 연달아서 등장할 수 있다는 점이다. 바로 다음과 같은 경우다.
< infile cat -
Bash
복사
해당 부분에서 <의 피연산자인 infile과 cat -은 서로 붙어있다. 즉 연산자, 피연산자 토큰이 번갈아 등장하지 않는다. 이 부분을 해석하기 위해서 prefix expression의 파싱 함수는 연산자, 파일 이름, 표현식의 3개 노드를 구성하도록 설계했다. 그 결과 표현식 파싱 함수가 첫 토큰으로 pipe 연산자를 만나고 에러라 판단한다. 이는 말단 노드가 연달아 등장하는 상황에 취약한 프랫 파서의 특성이라 할 수도 있다.
< 참고문헌 >
•
Interpreter in go, Thorsten Bal, 박재석, 인사이트
•
연산자 우선순위 파싱 알고리즘.

•
위키피디아
•
프랫 파서

