
바이트패딩
struct a {
char b;
int c;
}
C
복사
위 경우에 sizeof 연산자를 사용하게 되면 char 1byte + int 4byte = 5byte가 필요하다고 생각할 수 있다.
하지만 생각과 달리 8byte가 필요하다. 결론부터 먼저 말하면
현재 기기의 주소체계에 맞는 연산비트에 맞추게 된다
예를들어, 32비트 CPU는 한번에 메모리에서 32비트씩 가져와서 연산을 하기 때문에 4byte단위로 접근을 한다.
만약 5byte만 할당이 되어 있다면 우리가 int변수 안의 메모리를 온전히 가져오기 위해서는 4byte를 먼저 불러오고 다시 4byte를 또 불러와야 하기 때문에 불필요한 오버헤드가 발생하게 된다.
메모리 공간 낭비가 있을지언정 연산범위에 맞게 메모리를 할당을 하게 되면 이러한 오버헤드를 줄여 연산 성능에 도움을 줄 수 있다
보통 바이트패딩에 대한 설명으로 클래스와 구조체를 통해서 설명을 하곤 하지만, 지역변수 또한 바이트 패딩이 된다는 사실을 실험해보았다.
#include <stdio.h>
int main(void)
{
char a = 'a';
char b = 'b';
int c = 1;
printf("%p %p %p", &a, &b, &c);
return (0);
}
//결과
0x7ffee4fc38fb 0x7ffee4fc38fa 0x7ffee4fc38f4
C
복사
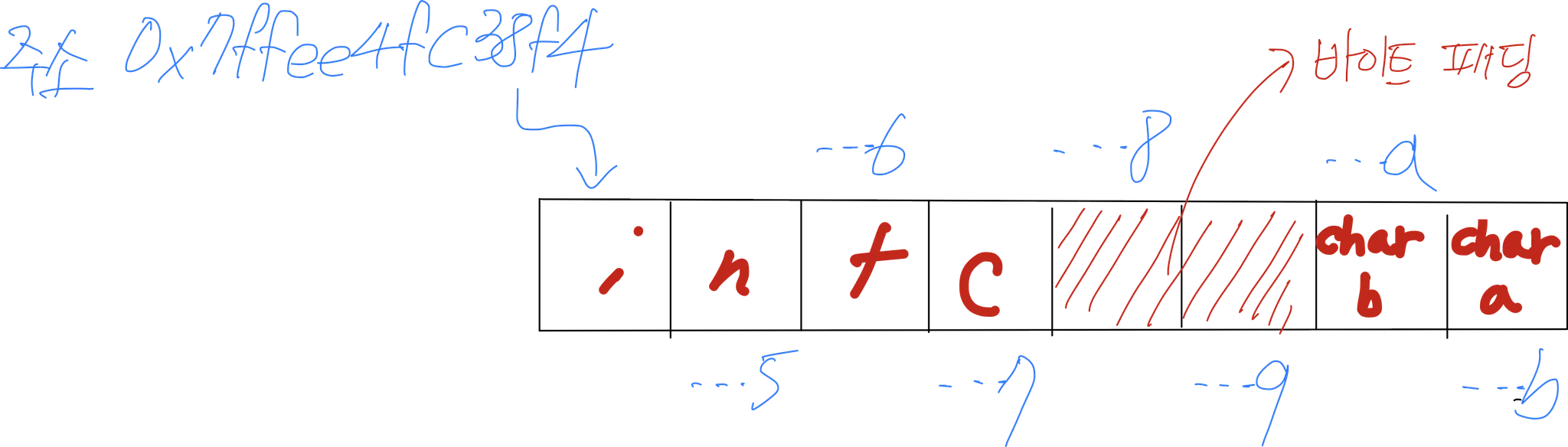
int c 의 주소가 0x7ffee4fc38f4부터 시작이기 때문에 int는 4byte이므로 ...7의 메모리 영역까지 차지
char a char b 는 1byte 자료형이므로 각각의 주소에 한칸씩 자리 차지
메모리가 연속적으로 할당된 것이 아니라 중간에 바이트 패딩이 생긴 것을 확인 할 수 있음
조금 더 자세한 설명은 아래 링크 참고 


가변인자
•
매개 변수의 개수가 정해져 있지 않고 상황에 따라 인자의 개수가 다르게 할당되어도 처리할 수 있게 해주는 것
•
매크로로 이루어져 있음
매크로 함수 : 일반 함수와 달리 단순 텍스트 치환만을 해줌. 함수 호출을 하는 것이 아니기 때문에 함수 호출 구문과 비교했을 때는 성능이 조금 더 좋은 편. 하지만 인자의 타입을 고려하지 않기 때문에 의도하지 않은 여러 오류가 발생할 수도 있음
#include <stdio.h>
#define fx(x) x*x
int main(void)
{
int result;
int x = 5;
result = fx(x+3);
printf("%d", result);
return (0);
}
//결과는 8 * 8 = 64가 아니라, x + 3 * x + 3 = 5 + 3 * 5 + 3 = 23
C
복사
•
가변 인자를 가지는 함수를 사용하기 위해서 필요한 매크로 (stdarg.h 필요)
1.
va_list
va_list ap;
C
복사
가변 인자의 주소를 담을 수 있는 포인터 변수. 관습적으로 ap라는 이름을 사용
2.
va_start
va_start(ap, args);
C
복사
가변 인자의 주소를 ap가 참조할 수 있도록 초기화 해주는 매크로
#define va_start(ap, v) ( (ap) = (va_list)_ADDRESSOF(v) + _INTSIZEOF(v) )
C
복사
Microsoft Visual Studio 기준으로 위와 같이 정의가 되어 있다.
마지막 필수 인자(v)를 매개변수로 넣게 되면 주소를 구하게 되고, 구한 주소에서 그 크기만큼 다음 주소로 넘겨서 가변인자의 시작 부분을 구할 수 있게 된다
_INTSIZEOF(v) => ( (sizeof(v) + sizeof(v) - 1) & ~(sizeof(int) - 1) )
위의 연산에 대해서 이해를 해보려고 많은 삽질을 했지만, 결과적으로 4의 배수씩만큼 연산을 하는것이라고 생각을 하면 되고 , 4의 배수씩만큼 연산을 하기 때문에 마지막 필수 인자의 크기를 구해서 그 값을 더하면 다음 가변인자의 주소를 알 수 있게 되는 것이다
3.
va_arg
#define va_arg(ap,t) ( *(t *)((ap += _INTSIZEOF(t)) - _INTSIZEOF(t)) )
C
복사
ap에 먼저 다음 가변인자의 주소를 넣게 된다.

ap는 다음 가변인자의 주소를 가리키고 있는 상태에서 그 더했던 크기만큼 다시 빼서 역참조(이용,ap는 여전히 2의 시작 주소를 가리키고 있는 상태)

4.
va_end
#define va_end(ap) ( ap = (va_list)0 )
C
복사
va_list 타입의 포인터 변수를 NULL을 할당하면서 가변 인자 사용이 끝날 때 사용한다.
위 매크로는 실제로 없어도 프로그램에 지장이 없다. 인텔 계열의 CPU에서는 va_end가 아무 일도 하지 않는다고 한다. 하지만 다른 플랫폼과의 호환성에서 중요한 역할을 할 수 있으므로 관례적으로 넣어준다. 또한 프로그래밍을 하면서 이미 사용이 끝난 va_list를 사용하여도 참조하는 것이 없도록 안전성에 기여하기도 한다.
5.
va_copy
va_copy(va_list dest, va_list src);
C
복사
va_copy는 현재 위치를 저장해야 하는 상황에서 사용한다. 예를들어 루프를 돌면서 포인터가 계속 전진하고 있는 상황에서 해당 위치를 저장해야 할 경우가 생기면 va_copy를 활용해서 해당 위치를 저장해둔다.
목표
- 0 . * 의 모든 조합과 width .precision 필드 c s p d i u x X %를 사용할 수 있도록 printf 구현
설계
출력은 string (문자 혹은 문자열), hex (16진수), decimal (10진수) 이렇게 세개의 로직으로 나눌 수 있음
원 값에 width precision을 고려해서 추가로 붙는 빈 공백이나 0을 padd라고 했을 때, 이 padd의 길이를 측정하고 그 값을 공백 혹은 0으로 정하는 방법이 string (문자, 문자열) vs non-string (나머지)으로 나뉨
→ string의 경우는 원 값 앞에 붙는 prefix (접두사)만 고민하면됨
→ non-string의 경우 원 값 뒤로 붙는 prefix (접두사) & suffix (접미사)를 고려해야함 (ex. 16진수 주소의 0x를 기준으로 앞을 prefix, 뒤를 suffix로 두어 " 0x0000(주소)"처럼 나타낼 수 있음
여기서 padd값의 길이와 값을 찾아서 동적할당 받아서 순서에 맞춰 출력하면됨
원본값 출력에 대해서는 string은 그냥 출력하면 되니 특별한 로직이 존재하지 않음
원본값 출력에 대해서 non-string은 16진수(p, x, X)냐 10진수 (d,i,u)냐에 따라 나뉨
→ 따라서 10진수 변환 16진수 변환 두가지 로직만 두면 됨
width와 precision의 관계
1.
있는 경우
•
dot 있음
length < precision -> precision - length = suffix
precision + 2 < width -> width - (precision + 2) = prefix
precision + 2 >= width -> prefix = 0
length >= precision -> suffix = 0
length + 2 < width -> width - (length + 2) = prefix
length + 2 >= width -> prefix = 0
•
dot 없음
width > length + 2 -> suffix = 0 -> prefix = width - (length + 2)
width <= length + 2 -> suffix = 0 -> prefix = 0
→ 출력 순서 : 0x 출력 -> suffix 출력 -> 주소 출력 -> prefix 출력
2.
없는 경우
•
dot 있음
length < precision -> precision - length = suffix
precision + 2 < width -> width - (precision + 2) = prefix
precision + 2 >= width -> prefix = 0
length >= precision -> suffix = 0
length + 2 < width -> width - (length + 2) = prefix
length + 2 >= width -> prefix = 0
•
dot 없음
◦
0 있음
width > length + 2 -> suffix = width - (length + 2) -> prefix = 0
width <= length + 2 -> suffix = 0 -> prefix = 0
◦
0 없음
width > length + 2 -> prefix = width - (length + 2) -> suffix = 0
width <= length + 2 -> suffix = 0 -> prefix = 0
→ 출력 순서 : prefix 출력 -> 0x 출력 -> suffix 출력 -> 주소 출
width error 처리
1.
가변 인자 x시
1 << 31 - 1 ~ 1 << 63 - 1까지 에러, 그 외엔 무시 없이 모두 처리
2.
가변 인자 o시
int로 형 변환하여 처리, 부호 별도 처리
(-2147483646 <= x <= 2147483646 외엔 무시 없이 에러)
2147483647 에러 O
2147483648 => -2147483648 에러 O
2147483649 => -2147483647 에러 O
2147483650 => -2147483646 에러 X
precision error 처리
1.
가변 인자 x시
(-2147483646 <= x <= -1 은 무시) 2147483647은 에러, 외에 무시 없이 모두 처리
2147483647 에러 O
2147483648 => -2147483648 에러 X
2147483649 => -2147483647 에러 X
2147493650 => -2147483646 에러 X (무시)
... 쭉 한 바퀴 돌아서
4294967295 => -1 에러 X (무시)
4294967299 => 3 에러 X
2.
가변 인자 o시
int로 형 변환하여 처리, 음수는 무시 (0 <= x <= 2147483646만 처리)
2147483647 에러 O
2147483648 => -2147483648 에러 X (무시)
2147483649 => -2147483647 에러 X (무시)
... 쭉 한 바퀴 돌아서
4294967295 => -1 에러 X (무시)
space 처리
space는 width 주어질 시 고려하지 않음
space는 precision만 주어질 시 고려함
type 처리
type을 만나지 못하면 현재 처리 중인 형식 태그 무시
•
type c 처리
c는 precision, space, +, # 무시
c는 width, 0, -만 처리
%는 c와 동일
•
type s 처리
s는 space, +, #무시
s는 width, precision, -, 0만 처리
•
type p 처리
p는 space, +, #무시
p는 width, precision, -, 0만 처리
수 출력
•
플래그 혹은 . 플래그 존재 시에 0 플래그 무시
음수여도 width 충분하면 0 플래그 출력
부호가 없을 때만 space 처리
음수가 아닐 때 + 처리
•
플래그 혹은 수가 음수면 space 무시
#은 xXo에 대해서만 처리
List
Search

