


이 게시글은 기존 게시물
의 기본적인 오일러 회로의 경로 구현으로 발생한 백준 1199번 문제의 시간초과를 해결 방법을 위한 게시물입니다.
기본적인 오일러 회로의 개념과 구현은 위 게시글을 참고하시면 감사하겠습니다.
시간 초과
void getEulerCircuit(int here)
{
for (int i = 0; i < n; i++) {
if (adj[here][i] > 0) {
adj[here][i]--;
adj[i][here]--;
getEulerCircuit(i);
}
}
ans.push_back(here);
}
C++
복사
우선 이 문제에서 중요한 부분은 위 코드이다.
그리고 여기서 시간초과의 큰 원인이 된다.
이 코드는 호출될 때마다 모든 정점에 대해서 간선이 존재하는지 확인을 하는 과정을 거치는데 이것이 매우 비효율적이다.
왜냐하면 간선을 하나씩 거치면서 지나온 간선을 지우게 되는데 점점 간선의 개수가 감소하여도 매번 모든 정점을 계산하게 될 것이다.
그래서 정점 사이에 간선이 존재하는 경우에만 확인을 하고 함수를 호출하면 가장 간단히 시간을 줄일 수 있는 방법이 될 것이다.
인접 행렬 vs 인접 리스트
정점 사이에 간선이 존재하는 경우만 어떻게 확인을 할까?
기존의 코드는 인접 행렬을 이용하여 구현하여 확인했는데 이를 인접 리스트로 바꾸면 수월하게 해결할 수 있다.
인접 행렬 : adj[a][b] : a에서 b의 간선이 몇개 인지?
인접 리스트 adj[a][0..n] : a에서 시작해서 간선이 존재하는 n개에 대한 도착 정보
ex) adj[1][0] = 1; → 1번 노드에서 간선이 존재하는 0번째 노드는 1이다.

1에서 2,3,4 정점에 간선이 존재한다.
자세한 설명은 구글링
하지만 여기서는 여러 개의 간선이 존재할 수 있기 때문에
adj[4][5] = make_pair(7,3); → 4번 정점에서 시작되어 연결되어있는 5번째 정점은 7이고 3개의 간선이 존재
이러한 식으로 표현해야 한다.
장단점을 간단히 설명하면
•
인접 행렬
장점 : 정점의 개수가 적고 간선의 개수가 많을 때 효율적, 구현이 쉬움, 출발 정점과 도착 정점을 random access가 가능.
단점 : 정점의 개수가 많고 간선의 개수가 적을 때는 빈 공간이 많아 메모리 소모가 크고, 존재하는 간선만 확인 시 정점 전부 탐색해야 함.
•
인접 리스트
장점 : 간선의 개수가 적을 때 효율적, 존재하는 간선만 탐색 시 연산이 빠름
단점 : 구현이 복잡, random access 불가(a에서 b로의 간선이 존재하는지 확인하려면 전부 탐색)
추가로 이 문제에서는 간선의 존재가 계속 유지되는 것이 아닌 함수를 호출할 때마다 간선이 하나씩 없어지므로 이에 대한 처리도 해줘야 한다!
구현
입력에 대한 구현은 생략!
void getEulerCircuit(int here)
{
for (int i = 0; i < adj[here].size(); i++) {
if (adj[here][i].second > 0) {
adj[here][i].second--;
for (int j = 0; j < adj[adj[here][i].first].size(); j++)
{
if (adj[adj[here][i].first][j].first == here)
{
adj[adj[here][i].first][j].second--;
}
}
getEulerCircuit(adj[here][i].first);
}
else
{
adj[here].erase(adj[here].begin() + i);
i--;
}
}
cout << here + 1 << " ";
}
C++
복사
here에서 존재하는 간선에 대해서만 탐색하고 반대 방향의 인접 리스트를 찾고 하나씩 지워준다.
else 문은 간선의 개수를 모두 소모했을 때 해당 pair자체를 지워줘서 탐색을 더 빠르게 해준다. 사실 이게 시간초과 해결의 핵심 포인트
이번 구현에서는 따로 경로를 저장하여 출력하지 않고 그대로 출력해줬다.
경로가 역순으로 나오겠지만 그 또한 오일러 회로이니까.
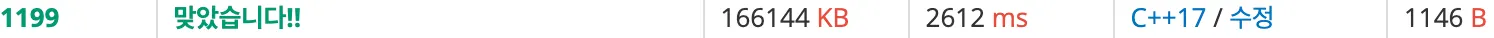
사실 이렇게 해도 시간초과가 간당간당하다 3000ms 와 얼마 차이 나지 않는다.
그 이유는 간선을 지울 때 반대로의 인접 리스트도 지워줘야 하는데 random access가 안된다는 인접 리스트의 단점에 전부 탐색하는 시간이 많이 소모되기 때문이다.
더 빠른 구현
void getEulerCircuit(int here)
{
for (int i = 0; i < adj[here].size(); i++) {
if (map[here][adj[here][i].first] > 0) {
adj[here][i].second -= map[here][adj[here][i].first];
map[here][adj[here][i].first] = 0;
}
if (adj[here][i].second > 0) {
adj[here][i].second--;
map[adj[here][i].first][here]++;
getEulerCircuit(adj[here][i].first);
}
else
{
adj[here].erase(adj[here].begin() + i);
i--;
}
}
cout << here + 1 << " ";
}
C++
복사
이 코드는 반대 간선을 바로 지우지 않고 2차원 배열인 map에 기록하여 나중에 반대 정점을 참조 시 예외처리로 지우고 가는 방식으로 더 빠르게 해결하였다.
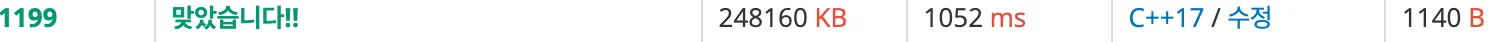
그렇게 하면 대략 1000ms에 해결할 수 있다.
사실 위 코드를 오랜만에 다시 보면서 무슨 의도로 map을 만든 것인지 한참 고민을 했다.
그러면서 오늘도 다시 한번 주석과 변수 명명의 중요함을 다시 깨닫게 될 수 있었다.
사실 이 문제를 풀 때는 밑에 방식으로 먼저 구현하고 위에 방식으로 더 쉽게 구현하였는데 밑의 방식이 설명이 더 어려워서 더 간단히 구현해도 통과하는지 확인을 해봤던 것 같다.
추가로 이해안되는 내용이나 설명이 필요하시면 댓글 작성해주시면 감사하겠습니다!
